Appearance
MySQL SQL 优化
1. 表 & 索引
1.1. 通过前缀索引优化索引大小
对于使用 REDUNDANT 或者 COMPACT 格式的 InnoDB 表,索引键前缀长度限制为 767 字节。如果 TEXT 或 VARCHAR 列的列前缀索引超过 191 个字符,则可能会达到此限制(假定为 utf8mb4 字符集,每个字符最多 4 个字节)。
可以通过设置参数 innodb_large_prefix 来开启或禁用索引前缀长度的限制,即是设置为 OFF,索引虽然可以创建成功,也会有一个警告,主要是因为 index size 会很大,效率大量的 IO 的操作,即使 MySQL 优化器命中了该索引,效率也不会很高。
Bash
# 设置 innodb_large_prefix=OFF 禁用索引前缀限制,虽然可以创建成功,但是有警告。
mysql> create index idx_nickname on users(nickname); # `nickname` varchar(255)
Records: 0 Duplicates: 0 Warnings: 1
mysql> show warnings;
+---------+------+---------------------------------------------------------+
| Level | Code | Message |
+---------+------+---------------------------------------------------------+
| Warning | 1071 | Specified key was too long; max key length is 767 bytes |业务发展初期,为了快速实现功能,对一些数据表字段的长度定义都比较宽松,比如用户表 users 的昵称 nickname 定义为 VARCHAR(128),而且有业务接口需要通过 nickname 查询,系统运行了一段时间之后,查询 users 表最大的 nickname 长度为 30,这个时候就可以创建前缀索引来减小索引的长度提升性能。
Bash
# `nickname` varchar(128) DEFAULT NULL 定义的执行计划
mysql> explain select * from users where nickname = 'Laaa';
+----+-------------+-------+------------+------+---------------+--------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+--------------+---------+-------+------+----------+-------+
| 1 | SIMPLE | users | NULL | ref | idx_nickname | idx_nickname | 515 | const | 1 | 100.00 | NULL |key_len 为 515,由于表和列都是 utf8mb4 字符集,每个字符占 4 个字节,变长数据类型 +2 Bytes,允许 NULL 额外 +1 Bytes,即 email 字段存储都是类似这样的值 xxxx@yyy.com,前缀索引的最大长度可以是 xxxx 这部分的最大长度即可。
Bash
# 创建前缀索引,前缀长度为 30
mysql> create index idx_nickname_part on users(nickname(30));
# 查看执行计划
mysql> explain select * from users where nickname = 'Laaa';
+----+-------------+-------+------------+------+--------------------------------+-------------------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+--------------------------------+-------------------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | users | NULL | ref | idx_nickname_part,idx_nickname | idx_nickname_part | 123 | const | 1 | 100.00 | Using where |可以看到优化器选择了前缀索引,索引长度为 123,即
前缀索引虽然可以减小索引的大小,但是不能消除排序。
Bash
mysql> explain select gender, count(*) from users where nickname like 'User100%' group by nickname limit 10;
+----+-------------+-------+------------+-------+--------------------------------+--------------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+--------------------------------+--------------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | users | NULL | range | idx_nickname_part,idx_nickname | idx_nickname | 515 | NULL | 899 | 100.00 | Using index condition |可以看到 Extra 为 Using index condition 表示使用了索引,但是需要回表查询数据,没有发生排序操作。
Bash
mysql> explain select gender, count(*) from users where nickname like 'User100%' group by nickname limit 10;
+----+-------------+-------+------------+-------+-------------------+-------------------+---------+------+------+----------+------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+-------------------+-------------------+---------+------+------+----------+------------------------------+
| 1 | SIMPLE | users | NULL | range | idx_nickname_part | idx_nickname_part | 123 | NULL | 899 | 100.00 | Using where; Using temporary |可以看到 Extra 为 Using where; Using temporary 表示在使用了索引的情况下,需要回表去查询所需的数据,同时发生了排序操作。
1.2. 复合索引的范围查询优化
在单列索引不能很好的过滤数据的时候,可以结合 WHERE 条件中其他字段来创建复合索引,更好的去过滤数据,减少 IO 的扫描次数,举个例子:业务需要按照时间段来查询交易记录,有如下的 SQL:
Bash
select * from trade_info where status = 1 and create_time >= '2020-10-01 00:00:00' and create_time <= '2020-10-07 23:59:59';开发同学根据以往复合索引的设计的经验:唯一值多选择性好的列作为复合索引的前导列,所以创建复合索 idx_create_time_status 是高效的,因为 create_time 是一秒一个值,唯一值很多,选择性很好,而 status 只有离散的 6 个值,所以认为这样创建是没问题的,但是这个经验只适合于等值条件过滤,不适合有范围条件过滤的情况,例如 idx_user_id_status(user_id, status) 这个是没问题的,但是对于包含有 create_time 范围的复合索引来说,就不适应了,我们来看下这两种不同索引顺序的差异,即 idx_status_create_time 和 idx_create_time_status。
Bash
# 分别创建两种不同的复合索引
mysql> create index idx_status_create_time on trade_info(status, create_time);
mysql> create index idx_create_time_status on trade_info(create_time,status);
# 查看 SQL 的执行计划
mysql> explain select * from users where status = 1 and create_time >= '2021-10-01 00:00:00' and create_time <= '2021-10-07 23:59:59';
+----+-------------+------------+------------+-------+-----------------------------------------------+------------------------+---------+------+-------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+-----------------------------------------------+------------------------+---------+------+-------+----------+-----------------------+
| 1 | SIMPLE | trade_info | NULL | range | idx_status_create_time,idx_create_time_status | idx_status_create_time | 6 | NULL | 98518 | 100.00 | Using index condition |从执行计划可以看到,两种不同顺序的复合索引都存在的情况,MySQL 优化器选择的是 idx_status_create_time 索引,那为什么不选择 idx_create_time_status,我们通过 optimizer_trace 来跟踪优化器的选择。
Bash
# 开启 optimizer_trace 跟踪
mysql> set session optimizer_trace="enabled=on",end_markers_in_json=on;
# 执行 SQL 语句
mysql> select * from trade_info where status = 1 and create_time >= '2021-10-01 00:00:00' and create_time <= '2021-10-07 23:59:59';
# 查看跟踪结果
mysql>SELECT trace FROM information_schema.OPTIMIZER_TRACE\G;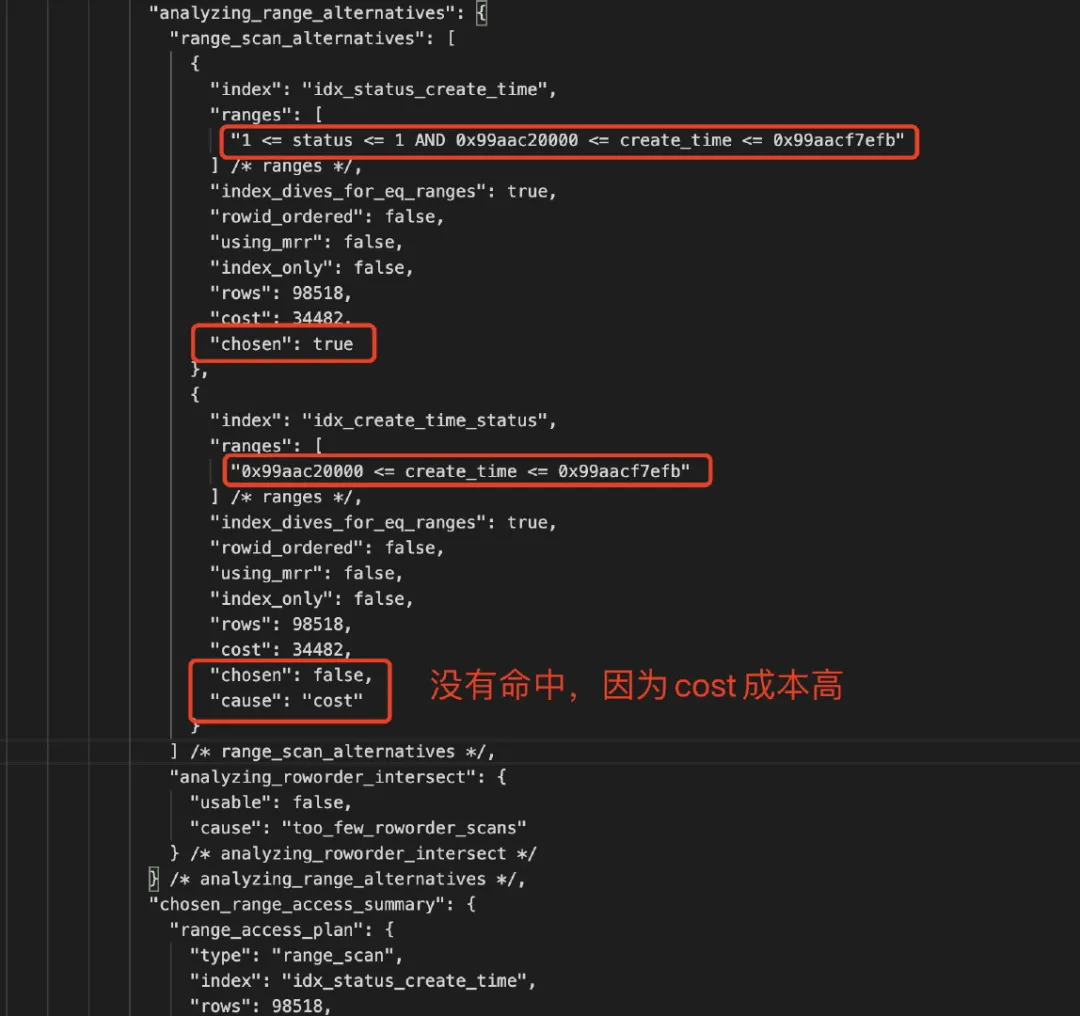
对比下两个索引的统计数据,如下所示:
| 复合索引 | Type | Rows | 参与过滤索引列 | Chosen | Cause |
|---|---|---|---|---|---|
idx_status_create_time | Index Range Scan | 98518 | status AND create_time | True | Cost 低 |
idx_create_time_status | Index Range Scan | 98518 | create_time | False | Cost 高 |
MySQL 优化器是基于 Cost 的,COST 主要包括 IO_COST 和 CPU_COST,MySQL 的 CBO(Cost-Based Optimizer 基于成本的优化器)总是选择 Cost 最小的作为最终的执行计划去执行,从上面的分析,CBO 选择的是复合索引 idx_status_create_time,因为该索引中的 status 和 create_time 都能参与了数据过滤,成本较低;而 idx_create_time_status 只有 create_time 参数数据过滤,status 被忽略了,其实 CBO 将其简化为单列索引 idx_create_time,选择性没有复合索引 idx_status_create_time 好。
复合索引设计原则
- 将范围查询的列放在复合索引的最后面,例如
idx_status_create_time; - 列过滤的频繁越高,选择性越好,应该作为复合索引的前导列,适用于等值查找,例如
idx_user_id_status;
这两个原则不是矛盾的,而是相辅相成的。
1.3. 索引跳跃扫描
一般情况下,如果表 users 有复合索引 idx_status_create_time,我们都知道,单独用 create_time 去查询,MySQL 优化器是不走索引,所以还需要再创建一个单列索引 idx_create_time。用过 Oracle 的同学都知道,是可以走索引跳跃扫描(Index Skip Scan),在 MySQL 8.0 也实现 Oracle 类似的索引跳跃扫描,在优化器选项也可以看到 skip_scan=on。
Bash
| optimizer_switch | use_invisible_indexes=off,skip_scan=on,hash_join=on |适合复合索引前导列唯一值少,后导列唯一值多的情况,如果前导列唯一值变多了,则 MySQL CBO 不会选择索引跳跃扫描,取决于索引列的数据分布情况。
Bash
mysql> explain select id, user_id, status, phone from users where create_time >= '2021-01-02 23:01:00' and create_time <= '2021-01-03 23:01:00';
+----+-------------+-------+------------+-------+------------------------+------------------------+---------+------+-------+----------+---------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+------------------------+------------------------+---------+------+-------+----------+---------------------------------------+
| 1 | SIMPLE | users | NULL | range | idx_status_create_time | idx_status_create_time | NULL | NULL | 15636 | 11.11 | Using where; Using index for skip scan|可以通过 optimizer_switch='skip_scan=off' 来关闭索引跳跃扫描特性。
Note:索引跳跃
索引跳跃扫描的核心是在复合索引中,即使查询条件不包含前导列,也能高效利用索引。其实现方式通常涉及遍历前导列的 Distinct 值,形成多个子查询,从而避免全表扫描。应用场景包括前导列基数低(如性别只有少量值)、查询条件包含非前导列的情况。
2. 查询
2.1. 分页查询优化
业务要根据时间范围查询交易记录,接口原始的 SQL 如下:
SQL
SELECT *
FROM trade_info
WHERE STATUS = 0 AND create_time >= '2020-10-01 00:00:00' AND create_time <= '2020-10-07 23:59:59'
ORDER BY id DESC
LIMIT 102120, 20;表 trade_info 上有索引 idx_status_create_time(status, create_time),实际上它等价于索引 (status, create_time, id),对于典型的分页 limit m, n 来说,越往后翻页越慢,也就是 m 越大会越慢,因为要定位 m 位置需要扫描的数据越来越多,导致 IO 开销比较大,这里可以利用辅助索引的覆盖扫描来进行优化,先获取 id,这一步就是索引覆盖扫描,不需要回表,然后通过 id 跟原表 trade_info 进行关联,改写后的 SQL 如下:
SQL
SELECT *
FROM trade_info a
INNER JOIN (
SELECT id -- 这里子查询走的是索引覆盖扫描,不需要回表
FROM trade_info
WHERE STATUS = 0 AND create_time >= '2020-10-01 00:00:00' AND create_time <= '2020-10-07 23:59:59'
ORDER BY id DESC
LIMIT 102120, 20
) AS b ON a.id = b.id3. 插入
3.1. 按序进行分批事务插入
将所有数据按主键顺序排序;
在 InnoDB 存储引擎中,主键是有序排列的,当数据按主键乱序插入时,若待插入的数据在中间页找到插入位置,但该页空间不足。此时会产生页分裂:
- 在当前页的右侧新建一个空页;
- 将原页 50% 的记录移动到新页中,形成两个半满页;
- 新记录根据主键顺序,插入到合适的页中;
- 更新相关页的双向链表指针;
假设当前页有
[10, 20, 30, 40, 50, 60, 70, 80, 90],要插入55:- 当前页已满,触发页分裂;
- 新建一个页,并搬移一半的数据:
- 原页:
[10, 20, 30, 40, 50] - 新页:
[60, 70, 80, 90]
- 原页:
- 插入
55后:- 原页:
[10, 20, 30, 40, 50, 55] - 新页:
[60, 70, 80, 90]
- 原页:
页分裂因为涉及数据搬移、指针更新、B+ 树平衡调整等操作,所以性能较差。而且随机 I/O 较多,特别是多次页分裂后,会产生磁盘碎片,进而降低查询性能。
将排序后的数据进行分批,每批数据量为 500 ~ 1000 左右;
批量插入,减少了网络通信、日志写入、索引更新的次数。
关闭事务自动提交,循环分批插入,并定期提交;
启用事务自动提交时:
- 每执行一条
INSERT,都会立即提交事务; - 每次提交都会触发日志写入、索引更新、写缓冲刷盘等操作;
- InnoDB 存储引擎中,每次提交都会触发一次
fsync操作(刷入磁盘),导致 I/O 开销较大;
关闭自动提交后,
INSERT操作会先写入内存(Buffer Pool),并不会立刻提交到磁盘。每执行一批INSERT后,统一提交(COMMIT),触发一次日志写入、索引更新和fsync。使得:- 日志写入、索引更新的次数显著减少,因为多个批次的数据会在内存中合并后一次性写入;
- 锁争用减少,因为事务提交的频率降低,减少了锁等待和日志竞争;
- 每执行一条
SQL
-- 关闭自动提交
SET AUTOCOMMIT = 0;
-- 循环执行,每批数据量为 500 ~ 1000 左右
INSERT INTO target_tb VALUES (...) ...;
-- 定期提交,例如每 5 ~ 10 批提交一次
COMMIT;3.2. 通过 LOAD DATA 导入大批量数据
LOAD DATA 是 MySQL 导入大量数据的最快方法。
SQL
LOAD DATA INFILE '/path/to/datafile.csv'
INTO TABLE target_tb -- 目标表名
FIELDS TERMINATED BY ',' -- 字段分隔符,CSV 一般用 ,
LINES TERMINATED BY '\n' -- 行结束符,Unix/Linux 一般用 \n,Windows 用 \r\n
ENCLOSED BY '"' -- 字段被 " 包围时去除,如 hello"" 会被解析为 hello
IGNORE 1 LINES -- 跳过标题行
(column1, column2, column3, ...); -- 要导入的列,顺序需与 CSV 文件一致若需要从客户端本地文件加载数据到服务器,则需要:
客户端连接服务端时,加上
--local-infile选项:SQL$ mysql --local-infile -u username -p确保服务端
local_infile参数为1:SQL-- 查询 local_infile 当前值 SELECT @@local_infile; -- 设置 local_infile = 1 SET GLOBAL local_infile = 1;使用
LOAD DATA LOCAL INFILE替代LOAD DATA INFILE命令;
4. 更新
4.1. 根据主键或索引进行更新
InnoDB 的行锁是加在索引上的,而不是在记录上加锁。当索引不存在或索引失效时,会从行锁升级为表锁。
4.2. 分批更新
营销系统有一批过期的优惠卷要失效,核心 SQL 如下:
SQL
-- 需要更新的数据量 500w
UPDATE coupons
SET STATUS = 1
WHERE STATUS = 0 AND create_time >= '2020-10-01 00:00:00' AND create_time <= '2020-10-07 23:59:59';在 Oracle 里更新 500w 数据是很快,因为可以利用多个 cpu core 去执行,但是 MySQL 就需要注意了,一个 SQL 只能使用一个 cpu core 去处理,如果 SQL 很复杂或执行很慢,就会阻塞后面的 SQL 请求,造成活动连接数暴增,MySQL CPU 100%,相应的接口 Timeout,同时对于主从复制架构,而且做了业务读写分离,更新 500w 数据需要 5 分钟,Master 上执行了 5 分钟,binlog 传到了 slave 也需要执行 5 分钟,那就是 Slave 延迟 5 分钟,在这期间会造成业务脏数据,比如重复下单等。
优化思路:先获取 where 条件中的最小 id 和最大 id,然后分批次去更新,每个批次 1000 条,这样既能快速完成更新,又能保证主从复制不会出现延迟。
优化如下:
先获取要更新的数据范围内的最小
id和最大id(表没有物理delete,所以id是连续的)Bashmysql> explain select min(id) min_id, max(id) max_id from coupons where status = 0 and create_time >= '2020-10-01 00:00:00' and create_time <= '2020-10-07 23:59:59'; +----+-------------+-------+------------+-------+------------------------+------------------------+---------+------+--------+----------+--------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+------------------------+------------------------+---------+------+--------+----------+--------------------------+ | 1 | SIMPLE | users | NULL | range | idx_status_create_time | idx_status_create_time | 6 | NULL | 180300 | 100.00 | Using where; Using index |Extra为Using where; Using index使用了索引idx_status_create_time,同时需要的数据都在索引中能找到,所以不需要回表查询数据。以每次 1000 条 commit 一次进行循环
update,主要代码如下:Javacurrent_id = min_id; for current_id < max_id do update coupons set status = 1 where id >= current_id and id <= current_id + 1000; // 通过主键 id 更新 1000 条很快 commit; current_id += 1000; done
4.3. 延迟索引更新
SQL
ALTER TABLE target_tb DISABLE KEYS;
-- modifications
ALTER TABLE target_tb ENABLE KEYS;5. 聚合
5.1. COUNT
整表
COUNT(*)MyISAM 存储引擎把一个表的总行数存在了磁盘上,因此对整表
COUNT(*)的时候会直接返回该数据,效率很高。而 InnoDB 存储引擎,在COUNT(*)时需要把数据一行一行取出来然后进行累积计数。若确实有需要对整表COUNT(*)的情况,则可以自行在应用层实现计数。COUNT(普通字段)、COUNT(主键 Id)、COUNT(1)与COUNT(*)的效率对比:先说结论:
COUNT(普通字段)<COUNT(主键 Id)<COUNT(1)≈COUNT(*)。COUNT(普通字段):存储引擎会将每一行的字段值取出来,返回给服务层。再根据字段上有无NOT NULL约束作进一步处理。若有NOT NULL约束,则服务层直接将值进行计数累加。若无NOT NULL约束,则服务层只选取非NULL值的字段进行计数累加。COUNT(主键 Id):存储引擎会将每一行的字段值取出来,返回给服务层,服务层按行进行计数累加。COUNT(1):将等行数的常量值1返回给服务层,服务层按行进行计数累加。COUNT(*):InnoDB 存储引擎专门针对这种情况做了优化,不会对字段进行取值,服务层按行进行计数累加。