Appearance
LVS 搭配 iptables 实现 FULLNAT 原理分析
最近在看 kube-proxy ipvs 的源码,发现用了很多年的 LVS 而且 NAT 模式居多的我尽然不知道原来 LVS 可以利用 iptables 实现 SNAT 模式。很长时间以来一直以为 LVS 的 NAT 模式只支持 DNAT,真是印证了 “纸上得来终觉浅,绝知此事要躬行”,还是要多读源码。
惯用思路,先实践验证后分细原理。
先搭建一套普通的 LVS NAT 模式环境。
1. 环境
| 角色 | IP |
|---|---|
| LVS | 192.168.122.11、10.0.5.63(模拟公网)、10.0.0.254(VIP) |
| RealServer | 192.168.122.249 |
| Client | 10.0.5.119 |
LVS 有两块网卡,分别模拟公网和内网。
2. 配置 NAT 模式
2.1. RealServer
在 192.168.122.249 上起一个简单 Web 程序充当 RealServer。
Bash
[root@rs ~]# python -m SimpleHTTPServer 8080
Serving HTTP on 0.0.0.0 port 8080 ...默认网关指向 LVS 的内网 IP:192.168.122.11。
Bash
[root@rs ~]# ip route show
default via 192.168.122.11 dev eth0 proto static metric 100
192.168.122.0/24 dev eth0 proto kernel scope link src 192.168.122.249 metric 1002.2. LVS
开启转发:
Bash
echo 1 > /proc/sys/net/ipv4/conf/all/forwarding创建 VS:
Bash
ipvsadm -A -t 10.0.0.254:80 -s rr添加 RS:
Bash
ipvsadm -a -t 10.0.0.254:80 -r 192.168.122.249:8080 -m -w 1绑定 VIP:
Bash
ip addr add 10.0.0.254/24 dev eth1Bash
[root@lvs ~]# ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.0.0.254:80 rr
-> 192.168.122.249:8080 Masq 1 0 02.3. 验证
在客户端上 curl 一下 VIP,验证一下能否访问到 RS 上的服务。

OK,没有问题。
3. 抓包分析 NAT 模式
都知道 NAT 模式只会修改目的 IP,即 VIP->RIP,并不会修改源 IP,即 CIP->DIP(LVS 本机 IP),我们来用 tcpdump 抓包验证一下是不是这样。
在 RS 上使用 tcpdump port 8080 -nn 开启抓包:

从抓包的结果来看 LVS NAT 模式只修改了目的 IP,没有修改源 IP。
另外,我们再猜想一下 RS 这会能不能访问外网。先推理一下,虽然 GW 已经指向了 LVS,但是由于 LVS 只做 DNAT,以及 iptables 也没有做相关 SNAT 的配置,所以 RS 当然是不能访问外网的,来验证一下。

结果当然是不能的。
4. 结合 iptables 做 SNAT
iptables 要做 SNAT 肯定是在 NAT 表的 POSTROUTING 链上做,所以我们先粗暴的来一条 iptables -t nat -A POSTROUTING -j MASQUERADE 看看会发生什么。
Bash
[root@lvs ~]# iptables -nL -t nat
Chain PREROUTING (policy ACCEPT)
target prot opt source destination
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
Chain POSTROUTING (policy ACCEPT)
target prot opt source destination
MASQUERADE all -- 0.0.0.0/0 0.0.0.0/0赶紧看看服务还能不能用,瑟瑟发抖。
curl 10.0.0.254,正常,还好没发生血案。
抓包看看有没有 SNAT。

然并卵,源 IP 还是客户端的 IP。
再看看 RS 这会能不能出公网。

可以了,意外的收获。
之前的认知也就止步于此。
反省一下其实应该再往下多想一下:为什么 LVS 对 RS 出去的包做了 SNAT,而 Client 进来后转发到 RS 的包没有做 SNAT 呢?
其实是需要启用内核一个参数,net.ipv4.vs.conntrack = 1 是我在读 kube-proxy ipvs 源码时发现的。
我们来启用下:
Bash
echo 1 > /proc/sys/net/ipv4/vs/conntrack再来抓包看一下

发现 SNAT 已经生效了,客户端的 IP 已经修改成了 LVS 内网 IP,即:CIP –> DIP。
5. 原理分析
net.ipv4.vs.conntrack = 1 的作用是什么,为什么启用了它以后就 iptables 就能 SNAT?
关于 net.ipv4.vs.conntrack 参数网上的资料比较少,还是得查手册 https://www.kernel.org/doc/Documentation/networking/ipvs-sysctl.txt。
Text
conntrack - BOOLEAN
0 - disabled (default)
not 0 - enabled
If set, maintain connection tracking entries for
connections handled by IPVS.
This should be enabled if connections handled by IPVS are to be
also handled by stateful firewall rules. That is, iptables rules
that make use of connection tracking. It is a performance
optimisation to disable this setting otherwise.
Connections handled by the IPVS FTP application module
will have connection tracking entries regardless of this setting.
Only available when IPVS is compiled with CONFIG_IP_VS_NFCT enabled.再看下模块帮助 https://github.com/torvalds/linux/blob/master/net/netfilter/ipvs/Kconfig。
Text
config IP_VS_NFCT
bool "Netfilter connection tracking"
depends on NF_CONNTRACK
---help---
The Netfilter connection tracking support allows the IPVS
connection state to be exported to the Netfilter framework
for filtering purposes.意思比较直白了,就是让 Netfilter 的状态管理功能也能应用于 IPVS 模块,反过来也就是说默认 nf_conntract 没法作用于 ipvs,好像是废话哈,接下来我们就来分析下为什么不能。
还是一样的思路,先实践再慢慢推理。
抄家伙,在 LVS 机器上 yum install -y conntrack-tools。
正式开始:
echo 0 > /proc/sys/net/ipv4/vs/conntrack,先禁用 ipvs nfct 的功能;iptables -t nat -F清空 NAT 表的规则;conntrack -F清除一下nf_conntrack表;- 在客户机上
curl 10.0.0.254; - 查看 LVS 的
conntrack表;

conntrack 表这时连接信息不会记录到 conntrack 表。
echo 1 > /proc/sys/net/ipv4/vs/conntrack,启用 ipvs nfct 看下会不会记录;- 再次查看 LVS 的 conntrack 表;

conntrack 表源 IP 已经被替换成 LVS 的内网 IP 了。
下面我们来分析下为什么会出现上边的结果,分析下 ipvs nfct 的实现原理。
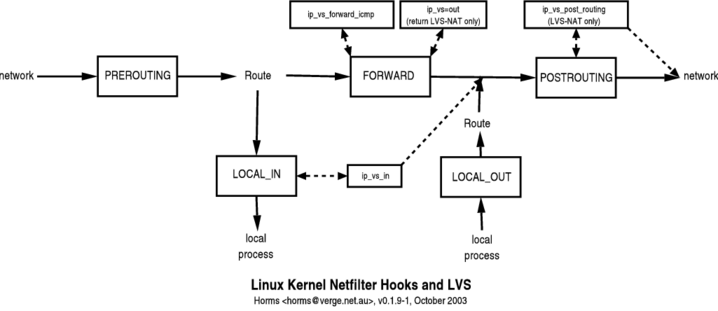
LVS(Linux Virtual Server)能实现负载均衡主要依靠内核 IPVS(IP Virtual Server)模块,而 IPVS 是基于内核 Netfilter 实现。IPVS 利用了 Netfilter 的 Hook 机制,主要在三个 Hook 点放置了钩子函数,分别是:NF_INET_LOCAL_IN、NF_INET_LOCAL_OUT 和 NF_INET_FORWARD,源码如下:
C
static struct nf_hook_ops ip_vs_ops[] __read_mostly = {
/* After packet filtering, change source only for VS/NAT */
// @xnile RIP->DIP修改为VIP->DIP,用于本机请求VIP后的回包
{
.hook = ip_vs_reply4,
.owner = THIS_MODULE,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_LOCAL_IN,
.priority = NF_IP_PRI_NAT_SRC - 2,
},
/* After packet filtering, forward packet through VS/DR, VS/TUN,
* or VS/NAT(change destination), so that filtering rules can be
* applied to IPVS. */
// @xnile CIP->VIP修改为CIP->RIP
{
.hook = ip_vs_remote_request4,
.owner = THIS_MODULE,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_LOCAL_IN,
.priority = NF_IP_PRI_NAT_SRC - 1,
},
/* Before ip_vs_in, change source only for VS/NAT */
// @xnile NF_INET_LOCAL_OUT 本机应用层发出去的包
// @xnile DIP->DIP 修改为DIR->VIP
{
.hook = ip_vs_local_reply4,
.owner = THIS_MODULE,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_LOCAL_OUT,
.priority = NF_IP_PRI_NAT_DST + 1,
},
/* After mangle, schedule and forward local requests */
// @xnile NF_INET_LOCAL_OUT 本机应用层发出去的包
// @xnile DIP->VIP修改为DIP->RIP
{
.hook = ip_vs_local_request4,
.owner = THIS_MODULE,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_LOCAL_OUT,
.priority = NF_IP_PRI_NAT_DST + 2,
},
/* After packet filtering (but before ip_vs_out_icmp), catch icmp
* destined for 0.0.0.0/0, which is for incoming IPVS connections */
{
.hook = ip_vs_forward_icmp,
.owner = THIS_MODULE,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_FORWARD,
.priority = 99,
},
/* After packet filtering, change source only for VS/NAT */
//@xnile RIP->CIP to src为VIP
{
.hook = ip_vs_reply4,
.owner = THIS_MODULE,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_FORWARD,
.priority = 100,
},
#ifdef CONFIG_IP_VS_IPV6
//... 省略ipv6部分
#endif
};注意留意一下上边 hook 的优先级,我们再看下 iptables NAT 勾子函数的定义:
C
static struct nf_hook_ops nf_nat_ipv4_ops[] __read_mostly = {
/* Before packet filtering, change destination */
// @xnile iptables -t nat -A REROUTING
{
.hook = nf_nat_ipv4_in,
.owner = THIS_MODULE,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_PRE_ROUTING,
.priority = NF_IP_PRI_NAT_DST,
},
/* After packet filtering, change source */
// @xnile iptables -t nat -A POSTROUTING
{
.hook = nf_nat_ipv4_out,
.owner = THIS_MODULE,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_POST_ROUTING,
.priority = NF_IP_PRI_NAT_SRC,
},
/* Before packet filtering, change destination */
// @xnile iptables -t nat -A OUTPUT
// @xnile DNAT 本机出去的包
{
.hook = nf_nat_ipv4_local_fn,
.owner = THIS_MODULE,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_LOCAL_OUT,
.priority = NF_IP_PRI_NAT_DST,
},
/* After packet filtering, change source */
// @xnile SNAT
{
.hook = nf_nat_ipv4_fn,
.owner = THIS_MODULE,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_LOCAL_IN,
.priority = NF_IP_PRI_NAT_SRC,
},
};借用一张 Netfilter 钩子函数与钩子点位置关系图看起来会更直观一些。
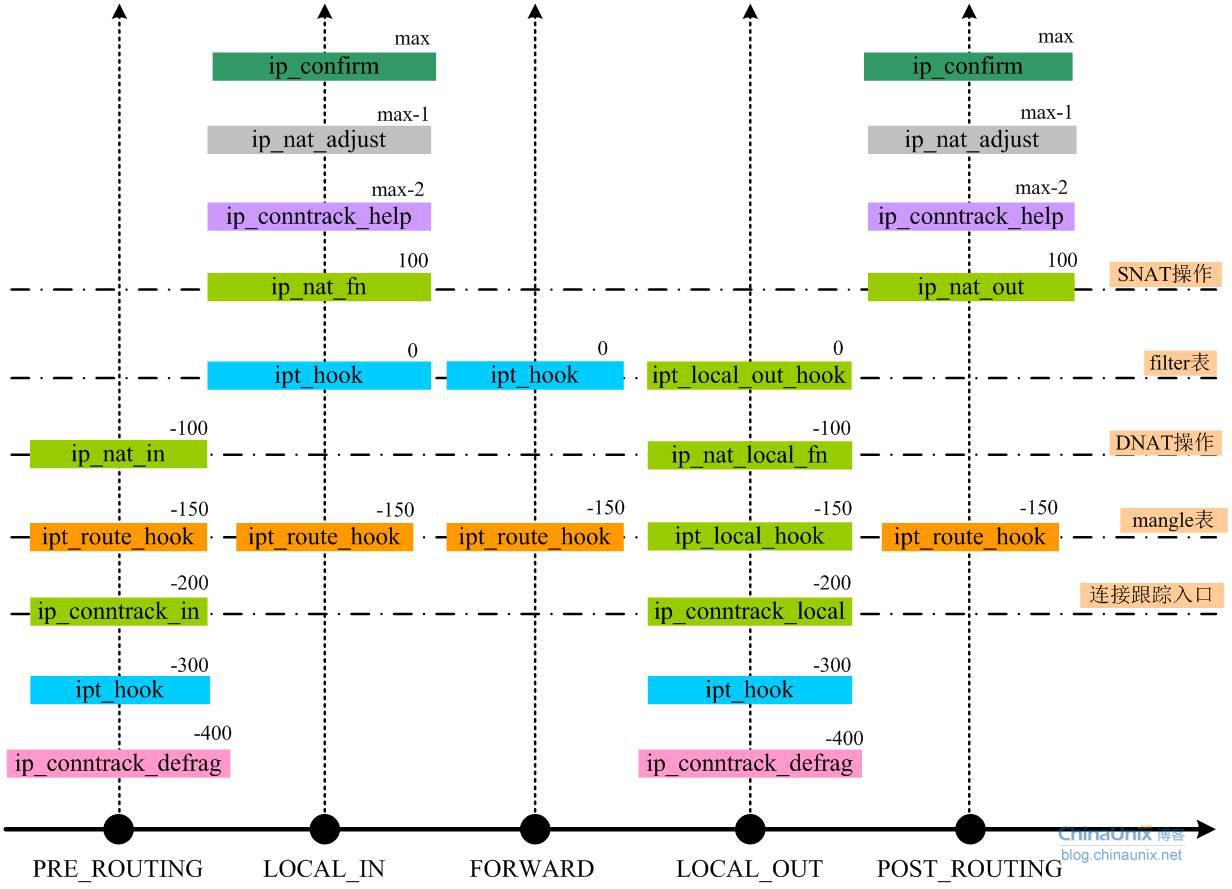
6. 背景知识
NAT 构建于
nf_conntrack之上,当数据包进入nf_conntrack后,会建立一个 tuple 以及相应的 replay tuple,而应答的数据包,会直接查找与之匹配的 repaly tupleTexttuple[ORIGINAL]={10.0.5.119-->10.0.0.254,TCP} tuple[REPLY]={10.0.0.254-->10.0.5.119,TCP}如果要做 SNAT 就修改 replay tuple 中的目的地址,如果要做 DNAT 就修改 replay tuple 中的源地址。
另外,
nf_conntrack有一个 confirm 的逻辑,就是上图中最上边绿色的部分,只有当数据流的头包离开协议栈的时候才会被 confirm,被 confirm 过的conntrack才会加入到conntrack哈希表。
困为 LVS 钩子函数的优先级要高于 confirm,数据流会首先导向到 LVS 的钩子函数中处理,然而钩子函数处理后会返回 NF_STOLEN,也就是数据流不会再往下走了,当然也就不会执行 confirm 逻辑,因此 conntrack 表中就不会有对应的 tuple 和 replay tuple,SNAT 当然也就不起作用。
Text
ip_vs_nat_xmit->ip_vs_nat_send_or_cont->ip_vs_update_conntrack
ip_vs_conn_new->ip_vs_bind_xmit7. 新问题
如果 telnet 目标机器上一个未监听的端口,在目标机器上用 conntrack -L 为什么看不到这个链接的状态?此包是在哪个阶段被丢弃的。
猜测只有回复 ACK 后才会更新状态。
假如这条链接能记录到 conntrack 表里,又应该给它个什么状态呢,三次握手之外的新状态?
因为没有去分析源码,所以只是推测,以后有时间再去研究下。
8. 总结
虽然 LVS 结合 iptables 也可以实现类似 FULLNAT 的效果,但也并非完美,除了性能问题外还有一个严重的问题:RealServer 无法获取客户端的 IP,正因为如此才有了 LVS FULLNAT 这样项目的存在。