Appearance
Hello ElasticSearch - Docker
1. 单机部署
1.1. ElasticSearch
创建 ElasticSearch Docker 网络
Bashdocker network create es-net拉取 ElasticSearch Docker 镜像
Bashdocker pull docker.elastic.co/elasticsearch/elasticsearch:8.18.3信息
国内常规网络下拉取 ElasticSearch 及其相关组件(Kibana、LogStash)的 Docker 镜像可能比较困难。而且这些镜像体积都比较大,接近 1GB。建议先在有网络条件的机器上把这些镜像拉下来,保存成 tar 文件,再拷贝到目标机器上加载、运行。
运行容器
Bashdocker run -d \ --name es01 \ --network es-net \ -m 1GB \ -e "discovery.type=single-node" \ -v es-data:/usr/share/elasticsearch/data \ -v es-logs:/usr/share/elasticsearch/logs \ -v es-plugins:/usr/share/elasticsearch/plugins \ -p 9200:9200 \ docker.elastic.co/elasticsearch/elasticsearch:8.18.3可以使用
-m标志为容器设置内存限制,这就不需要手动设置 JVM 的大小了(如-e "ES_JAVA_OPTS=-Xms512m -Xmx512m")。9200是 ElasticSearch 对外提供 REST API 服务的端口,ElasticSearch 集群节点之间内部通信的端口是9300。重置密码
ElasticSearch 8.x 默认开启安全特性。在非交互式容器中运行时 ElasticSearch 无法自动生成并打印
elastic用户的随机密码。所以我们这里需要手动重置下elastic用户的密码:Bashdocker exec -it es01 /usr/share/elasticsearch/bin/elasticsearch-reset-password -u elastic将
http_ca.crtSSL 证书从容器复制到本地Bashdocker cp es01:/usr/share/elasticsearch/config/certs/http_ca.crt .测试
Bashexport ELASTIC_PASSWORD="your_password" && \ curl --cacert http_ca.crt -u elastic:$ELASTIC_PASSWORD https://localhost:9200如果终端输出类似如下内容,则表示 ElasticSearch 运行成功:
JSON{ "name" : "5cee5053de20", "cluster_name" : "docker-cluster", "cluster_uuid" : "Zk24C_PES5mT1iZVBLa2Hg", "version" : { "number" : "8.18.3", "build_flavor" : "default", "build_type" : "docker", "build_hash" : "28fc77664903e7de48ba5632e5d8bfeb5e3ed39c", "build_date" : "2025-06-18T22:08:41.171261054Z", "build_snapshot" : false, "lucene_version" : "9.12.1", "minimum_wire_compatibility_version" : "7.17.0", "minimum_index_compatibility_version" : "7.0.0" }, "tagline" : "You Know, for Search" }
1.2. Kibana
拉取 Kibana Docker 镜像
Bashdocker pull docker.elastic.co/kibana/kibana:8.18.3信息
同上,建议先在有网络条件的机器上把这些镜像拉下来,保存成 tar 文件,再拷贝到目标机器上加载、运行。
启动 Kibana 容器
Bashdocker run -d \ --name kib01 \ --network es-net \ -e ELASTICSEARCH_HOST=http://es01:9200 \ -p 5601:5601 \ docker.elastic.co/kibana/kibana:8.18.3信息
Kibana 版本尽量保持与 ElasticSearch 保持一致。
Kibana 启动比较慢,可以使用
docker logs -f kib01查看运行日志。访问 Kibana
Kibana 启动时,会在终端输出一个唯一生成的链接,例如:
Texthttp://0.0.0.0:5601/?code=137927要访问 Kibana,请在网页浏览器中打开此链接。
Kibana 初始化配置
在浏览器中,输入启动 ElasticSearch 时生成的注册令牌。
要重新生成令牌,请运行:
Bashdocker exec -it es01 /usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s kibana登录 Kibana
使用启动 ElasticSearch 时生成的密码,以
elastic用户身份登录 Kibana。初识 Kibana Dev Tools
在左侧菜单中找到并打开 Dev Tools:
图 1.1 - Dev Tools 入口 在 Dev Tools 的控制台中输入并执行:
JSONGET /输出:
JSON{ "name": "5cee5053de20", "cluster_name": "docker-cluster", "cluster_uuid": "Zk24C_PES5mT1iZVBLa2Hg", "version": { "number": "8.18.3", "build_flavor": "default", "build_type": "docker", "build_hash": "28fc77664903e7de48ba5632e5d8bfeb5e3ed39c", "build_date": "2025-06-18T22:08:41.171261054Z", "build_snapshot": false, "lucene_version": "9.12.1", "minimum_wire_compatibility_version": "7.17.0", "minimum_index_compatibility_version": "7.0.0" }, "tagline": "You Know, for Search" }可以看到输出内容与直接访问
https://localhost:9200的输出一致。查询 ElasticSearch 中全部的索引文档,返回所有文档数据:
JSONGET _search { "query": { "match_all": {} } }JSON{ "took": 1, "timed_out": false, "_shards": { "total": 12, "successful": 12, "skipped": 0, "failed": 0 }, "hits": { "total": { "value": 0, "relation": "eq" }, "max_score": null, "hits": [] } }
1.3. IK 分词器
ElasticSearch 默认的分词器对中文的处理并不友好。例如,使用 ElasticSearch 的 _analyze API 调用 standard 分析器对输入的中文进行分词处理:
JSON
POST /_analyze
{
"analyzer": "standard",
"text": "春江潮水连海平,海上明月共潮生。"
}JSON
{
"tokens": [
{
"token": "春",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
},
{
"token": "江",
"start_offset": 1,
"end_offset": 2,
"type": "<IDEOGRAPHIC>",
"position": 1
},
{
"token": "潮",
"start_offset": 2,
"end_offset": 3,
"type": "<IDEOGRAPHIC>",
"position": 2
},
...
}可以看到中文被逐字分词,即使将分词器改为 chinese 也是一样。
处理中文分词,一般会使用 IK 分词器 。
1.3.1. 在线安装
进入容器:
Bashdocker exec -it es01 /bin/bash在线下载并安装:
Bashbin/elasticsearch-plugin install https://get.infini.cloud/elasticsearch/analysis-ik/8.18.3退出容器:
Bashexit重启容器:
Bashdocker restart es01
1.3.2. 离线安装(推荐)
在 Github 首页可以看到 Releases 链接,选择与 ElasticSearch 对应的版本进行下载,并上传至服务器当前用户的 home 目录。
查看
es-plugins数据卷的文件目录:Bash$ docker volume inspect es-plugins [ { "CreatedAt": "2025-08-18T16:00:37+08:00", "Driver": "local", "Labels": null, "Mountpoint": "/var/lib/docker/volumes/es-plugins/_data", "Name": "es-plugins", "Options": null, "Scope": "local" } ]在 ElasticSearch 的插件目录下创建
analysis-ik文件夹:Bashmkdir -p /var/lib/docker/volumes/es-plugins/_data/analysis-ik解压插件:
Bashunzip ~/elasticsearch-analysis-ik-8.18.3.zip -d /var/lib/docker/volumes/es-plugins/_data/analysis-ik重启容器:
Bashdocker restart es01
一键安装命令
需先安装 jq、unzip:
Bash
sudo apt install jq -yBash
sudo apt install unzip -y一键安装命令(记得将 zipPath 改为实际插件的路径):
Bash
zipPath=/path/to/elasticsearch-analysis-ik-8.18.3.zip \
volumeName=$(docker volume ls --format "table {{.Name}}" | grep 'es.*plugins') \
volumePath=$(docker volume inspect ${volumeName} | jq -r '.[0].Mountpoint') && \
sudo mkdir ${volumePath}/analysis-ik && \
sudo unzip ${zipPath} -d ${volumePath}/analysis-ik再手动重启容器即可。
1.3.3. 分词器测试
IK 分词器包含两种模式:
ik_smart:优先选择语义完整的词,减少冗余和不必要的短词;JSONPOST /_analyze { "analyzer": "ik_smart", "text": "春江潮水连海平,海上明月共潮生。" }JSON{ "tokens": [ { "token": "春江", "start_offset": 0, "end_offset": 2, "type": "CN_WORD", "position": 0 }, { "token": "潮水", "start_offset": 2, "end_offset": 4, "type": "CN_WORD", "position": 1 }, { "token": "连", "start_offset": 4, "end_offset": 5, "type": "CN_CHAR", "position": 2 }, ... ] }ik_max_word:优先选择最长的词进行切分,同时保留所有可能的短词组合。JSONPOST /_analyze { "analyzer": "ik_max_word", "text": "春江潮水连海平,海上明月共潮生。" }JSON{ "tokens": [ { "token": "春江", "start_offset": 0, "end_offset": 2, "type": "CN_WORD", "position": 0 }, { "token": "江潮", "start_offset": 1, "end_offset": 3, "type": "CN_WORD", "position": 1 }, { "token": "潮水", "start_offset": 2, "end_offset": 4, "type": "CN_WORD", "position": 2 }, ... ] }
1.3.4. 扩展词库
要扩展或禁用分词器的词条,只需要编辑 IK 分词器插件目录中的 config/IKAnalyzer.cfg.xml 文件(不存在可新建):
XML
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict"></entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>1.4. 拼音分词器
为了实现根据拼音搜索或字母自动补全,我们可以使用拼音分词器 。
1.4.1. 安装方式
安装方式同 IK 分词器一样。
1.4.2. 分词器测试
请求:
JSON
POST /_analyze
{
"text": [
"苹果手机"
],
"analyzer": "pinyin"
}响应:
JSON
{
"tokens": [
{ "token": "ping", "start_offset": 0, "end_offset": 0, "type": "word", "position": 0 },
{ "token": "pgsj", "start_offset": 0, "end_offset": 0, "type": "word", "position": 0 },
{ "token": "guo", "start_offset": 0, "end_offset": 0, "type": "word", "position": 1 },
{ "token": "shou", "start_offset": 0, "end_offset": 0, "type": "word", "position": 2 },
{ "token": "ji", "start_offset": 0, "end_offset": 0, "type": "word", "position": 3 }
]
}1.4.3. 选项参数
最新完整的可选参数详见 。
keep_first_letter:启用时,仅保留每个汉字的拼音首字母。例如,“刘德华” 变为ldh。默认值:true;keep_separate_first_letter:启用时,将每个汉字的拼音首字母分开存储。例如,“刘德华” 变为l、d、h。默认值:false;limit_first_letter_length:设置首字母结果的最大长度。默认值:16;keep_full_pinyin:启用时,保留每个汉字的完整拼音。例如,“刘德华” 变为["liu","de","hua"]。默认值:true;keep_joined_full_pinyin:启用时,将每个汉字的完整拼音连接起来。例如,“刘德华” 变为["liudehua"]。默认值:false;keep_none_chinese:保留结果中的非汉字字母或数字。默认值:true;keep_none_chinese_together:将非汉字字母保持在一起。默认值:true。例如,“DJ 音乐家” 变为["DJ","yin","yue","jia"]。当设为false时,“DJ 音乐家” 变为["D","J","yin","yue","jia"]。注意:需先启用keep_none_chinese;keep_none_chinese_in_first_letter:在首字母中保留非汉字字母。例如,“刘德华 AT2016” 变为ldhat2016。默认值:true;keep_none_chinese_in_joined_full_pinyin:在连接的完整拼音中保留非汉字字母。例如,“刘德华 2016” 变为liudehua2016。默认值:false;none_chinese_pinyin_tokenize:将非汉字字母若为拼音时拆分为单独的拼音词。例如,liudehuaalibaba13zhuanghan变为["liu","de","hua","a","li","ba","ba","13","zhuang","han"]。注意:需先启用keep_none_chinese和keep_none_chinese_together。默认值:true;keep_original:启用时,同时保留原始输入。默认值:false;lowercase:将非汉字字母转换为小写。默认值:true;trim_whitespace:去除空格。默认值:true;remove_duplicated_term:启用时,移除重复的词以节省索引空间。例如,“de 的” 变为de。默认值:false。注意:与位置相关的查询可能会受到影响;ignore_pinyin_offset:在 6.0 版本后,偏移量受到严格约束,不允许重叠的词元。使用此参数可以忽略偏移量,允许重叠词元。请注意,所有与位置相关的查询或高亮显示将变得不准确。建议使用多字段并为不同的查询目的指定不同设置。如果需要偏移量,请设置为false。默认值:true。
1.4.4. 注意事项
在使用拼音分词器创建索引时,应搭配 IK 分词器一起使用:
JSON
PUT /my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "ik_max_word",
"filter": "pinyin_filter"
}
},
"filter": {
"pinyin_filter": {
"type": "pinyin"
/* ... */
}
}
}
}
/* ... */
}拼音分词器推荐的配置如下:
JSON
PUT /my_index
{
"settings": {
"analysis": {
/* ... */
"filter": {
"pinyin_filter": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
}
/* ... */
}拼音分词器适合在创建倒排索引的时候使用,不适合在搜索的时候使用。应在创建索引和搜索时使用不同的分词器:
JSON
PUT /my_index
{
/* ... */
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "my_analyzer",
"search_analyzer": "ik_smart"
}
}
}
}2. 集群部署
2.1. 宿主机配置
修改 vm.max_map_count 内核参数:
修改
/etc/sysctl.confBashecho "vm.max_map_count = 262144" | sudo tee -a /etc/sysctl.confvm.max_map_count是一个内核参数,用于控制一个进程可以拥有的最大内存映射区域(memory map areas)数量。默认值通常为65530(或65536)。ElasticSearch 要求vm.max_map_count至少为262144。应用更改:
Bashsudo sysctl -p
2.2. Docker Compose
YAML
name: es-cluster
services:
es01:
image: docker.elastic.co/elasticsearch/elasticsearch:8.18.3
container_name: es01
hostname: es01
mem_limit: 1g
environment:
- node.name=es01
- cluster.name=es-cluster
- discovery.seed_hosts=es02,es03
- cluster.initial_master_nodes=es01,es02,es03
- xpack.security.enabled=false
networks:
- es-cluster
ports:
- '9201:9200'
volumes:
- 'es01-data:/usr/share/elasticsearch/data'
- 'es01-logs:/usr/share/elasticsearch/logs'
- 'es01-plugins:/usr/share/elasticsearch/plugins'
es02:
image: docker.elastic.co/elasticsearch/elasticsearch:8.18.3
container_name: es02
hostname: es02
mem_limit: 1g
environment:
- node.name=es02
- cluster.name=es-cluster
- discovery.seed_hosts=es03,es01
- cluster.initial_master_nodes=es01,es02,es03
- xpack.security.enabled=false
networks:
- es-cluster
ports:
- '9202:9200'
volumes:
- 'es02-data:/usr/share/elasticsearch/data'
- 'es02-logs:/usr/share/elasticsearch/logs'
- 'es02-plugins:/usr/share/elasticsearch/plugins'
es03:
image: docker.elastic.co/elasticsearch/elasticsearch:8.18.3
container_name: es03
hostname: es03
mem_limit: 1g
environment:
- node.name=es03
- cluster.name=es-cluster
- discovery.seed_hosts=es01,es02
- cluster.initial_master_nodes=es01,es02,es03
- xpack.security.enabled=false
networks:
- es-cluster
ports:
- '9203:9200'
volumes:
- 'es03-data:/usr/share/elasticsearch/data'
- 'es03-logs:/usr/share/elasticsearch/logs'
- 'es03-plugins:/usr/share/elasticsearch/plugins'
volumes:
es01-data:
es01-logs:
es01-plugins:
es02-data:
es02-logs:
es02-plugins:
es03-data:
es03-logs:
es03-plugins:
networks:
es-cluster:mem_limit: 1g:为容器设置内存限制,防止单个节点占用过多系统资源。或者也可以使用环境变量限制 JVM 的堆内存大小(如ES_JAVA_OPTS=-Xms512m -Xmx512m);environment:node.name=es01:设置节点的名称为es01,用于在集群中标识该节点;cluster.name=es-cluster:定义集群名称,所有节点共享同一个集群名称es-cluster;discovery.seed_hosts=es02,es03:指定集群中其他节点的地址,用于节点发现(es01会尝试连接es02和es03);cluster.initial_master_nodes=es01,es02,es03:指定初始主节点列表,用于集群启动时的主节点选举;xpack.security.enabled=false:禁用 ElasticSearch 的 X-Pack 安全功能(例如用户认证和加密),适合开发或测试环境,简化配置。
2.3. Cerebro
是一个简单、轻量且易用的 ElasticSearch 集群管理工具,适合需要快速监控和管理的小型或测试环境集群。它提供直观的 Web 界面,支持实时监控、索引管理和快照操作,但功能较为基础,社区支持有限。项目更新频率较低,最新稳定版为 2021-04-10 发布。
可以直接从 Github 发布页面下载最新版本。支持直接在 Windows 上解压运行(bin/cerebro.bat)。
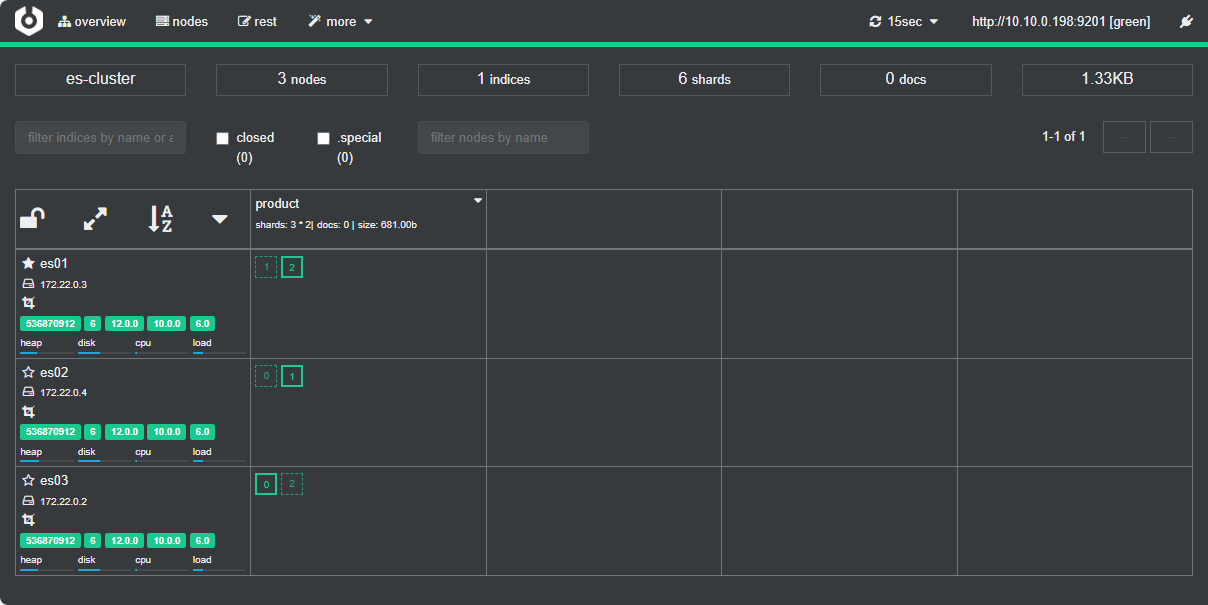
Cerebro 配置自定义证书
打开 conf\application.conf 文件,添加如下内容:
Properties
hosts = [
{
host = "https://your_es_address:9200"
name = "es-cluster"
auth = {
username = "elastic"
password = "your_password"
}
}
]
play.ws.ssl {
trustManager = {
stores = [
{ type = "PEM", path = "your_path_to_ca.crt" }
]
}
}