Appearance
Redis 消息队列实现方式
1. 概述
常用的消息队列有,RabbitMq、Kafka、RocketMq、ActiveMq 等。这些消息队列需要独立安装部署,作为一个中间件来提供服务,虽然有着高性能、高可靠的优点,但是额外部署这些中间件也会增加运维成本,和服务器成本。
本篇文章探讨了一下如何使用 Redis 实现消息队列。使用 Redis 无需额外的部署,如果原先就有使用 Redis 的话。此外 Redis 更为轻量也更容易维护。但是 Redis 实现消息队列有多种方案,这些方案有其优点也有其缺点,适用于不同的应用场景。以下从 “实时性”、“可靠性”、“功能性” 这几个维度做一些对比分析探讨。
2. 理论部分
“消息队列” 是在消息的传输过程中保存消息的容器。消息队列常被使用在 “流量削峰”、“系统解耦”、“异步调用” 这几个方面。消息队列主要面对的几个问题是:
- 并发性能
- 实时性
- 如何防止消息丢失,保证可靠性
从简单的讲,消息队列就是一个 “队列”(queue),生产者负责发送消息,消息队列存储消息,消费者则负责接收消息。
在面对一些亿级流量场景,消息队列届的大哥 Kafka 是如何保证高性能的呢?参考链接
- Kafka Reactor 模型架构
- 页缓存技术+磁盘顺序写
- ZeroCopy:零拷贝技术
- 使用批量消息提升服务端处理能力
那使用 Redis 能否获得和 Kafka 一样的高性能呢?答案是一定的。Redis 是如何实现高性能的呢?参考链接
- IO 多路复用
- 单线程
- 基于内存存储
- 高效数据结构
- 写时拷贝(CopyOnWrite)
- 客户端管道批量命令
- 零拷贝技术
3. Redis 实现消息队列
3.1. 基于 List 实现
消息队列的基础结构是队列,而 Redis 正好有相对应的数据结构:List。
3.1.1. 生产者写消息
Bash
127.0.0.1:6379> lpush mq hello1
127.0.0.1:6379> lpush mq hello2
127.0.0.1:6379> lpush mq hello3
127.0.0.1:6379> lpush mq hello4
127.0.0.1:6379> lpush mq hello5lpush 命令向指定列表的左边推入元素,以上命令模拟了向 MQ 这个消息队列列表中写入五条消息,分别是 hello1 ~ hello5。同时写入多条也可以,如:
Bash
127.0.0.1:6379> lpush mq hello6 hello73.1.2. 消费者读取消息
首先,基于 List 实现的消息队列是可以有效保证实时性的。消费者要如何检测到有新消息推送过来呢?
要么是不停自旋调用
llen mq获取队列的长度,如果不为 0 则读取。或者自旋调用rpop不停读取数据。虽然能保证高实时性,但是这会造成 Redis 的性能浪费和消费者本身的性能浪费,严重时会导致系统崩溃;定时调用
llen mq获取队列的长度。实时性取决于定时任务的频率,如果每 100ms 一次,则就有 100ms 的延迟;brpop,brpop可以理解为rpop命令的阻塞升级版,brpop mq 1会尝试阻塞读取 MQ 1s 时间,如果 1s 内没有消息则会返回nil,如果有消息,会立即返回;生产者
Bash127.0.0.1:6379> rpush mqb hello (integer) 1消费者
Bash127.0.0.1:6379> brpop mqb 1 1) "mqb" 2) "hello" 127.0.0.1:6379> brpop mqb 1 (nil) (1.08s)
具体基于 List 实现,读取消息可以通过两种方式。
第一种是
rpop,从列表的右边读取并弹出元素,该操作是原子性的,并发下安全。Bash127.0.0.1:6379> rpop mq 127.0.0.1:6379> rpop mq依次弹出的是 hello1、hello2,按照先进先出的顺序弹出。
第二种方式是
lrange,使用lrange可以实现消息的批量消费,lrange list start stop读取 List 的从 start ~ stop 之间的元素。读取之后为了防止重复消费,需要使用ltrim start stop进行清除。- 因为期间需要进行两个操作,因此是非并发安全的,需要通过分布式锁来保证安全性。
- 此外还存在着事务的问题,如果读取完消息之后进程挂掉,会导致之前已经读取的消息在下次运行时被重复消费。
- 这种方式适用于对消息可靠性要求不高,但是要求处理性能高的情况,如处理大量的日志数据进行分析操作。
除了使用
ltrim之外也可以使用lrem key count value来删除已经消费的数据。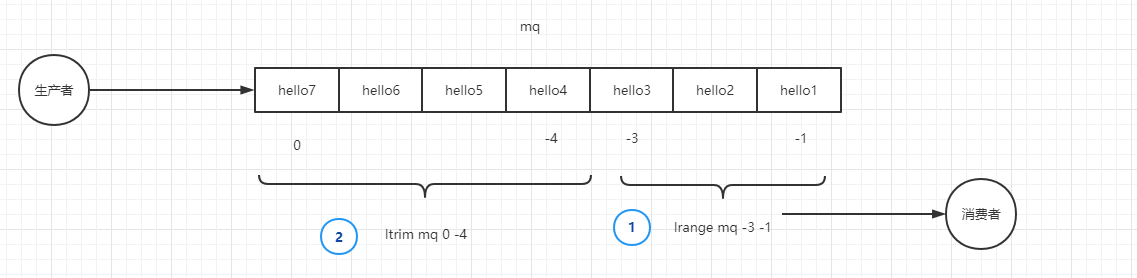
如图所示,假设 MQ 中有 7 条消息,每次消费 3 条消息。那么第一条命令
lrange mq -3 -1,读取倒数第 3 到倒数第 1 之间的所有元素。第二条命令ltrim mq 0 -4,保留未读取的零到倒数第 4 条消息,把已经读取的消息删除。以下演示了在 redis-cli 中的模拟:
Bash127.0.0.1:6379> lrange mq -3 -1 1) "hello3" 2) "hello2" 3) "hello1" 127.0.0.1:6379> ltrim mq 0 -4 OK 127.0.0.1:6379> lrange mq 0 -1 1) "hello7" 2) "hello6" 3) "hello5" 4) "hello4"
3.1.3. 多生产者多消费者
多生产者
基于 List 的多生产者是没有问题的,多个生产者同时向 MQ 中推送消息,仍然能保证消息有序。
多消费者
rpop方式多消费者下并发同样安全,不会出现消息被重复消费的情况。lrange+ltrim方式多消费者下并发不安全,需要使用分布式锁保证有序,否则会出现消息被重复消费的问题。同时不保证事务安全性。需要通过额外手段记录读取 MQ 的位置,以保证宕机复位时不会出现消息重复读取的问题。
3.1.4. 发布订阅方式
发布订阅简单的理解是将一个消息广播给多个消费者,每个消费者针对该消息只消费一次。
针对发布订阅有两种思路:
第一种是较为简单的,既然一对一消费可以通过一个 List 实现,那么一对多消费就使用多个 List 来一一对应各个消费者:
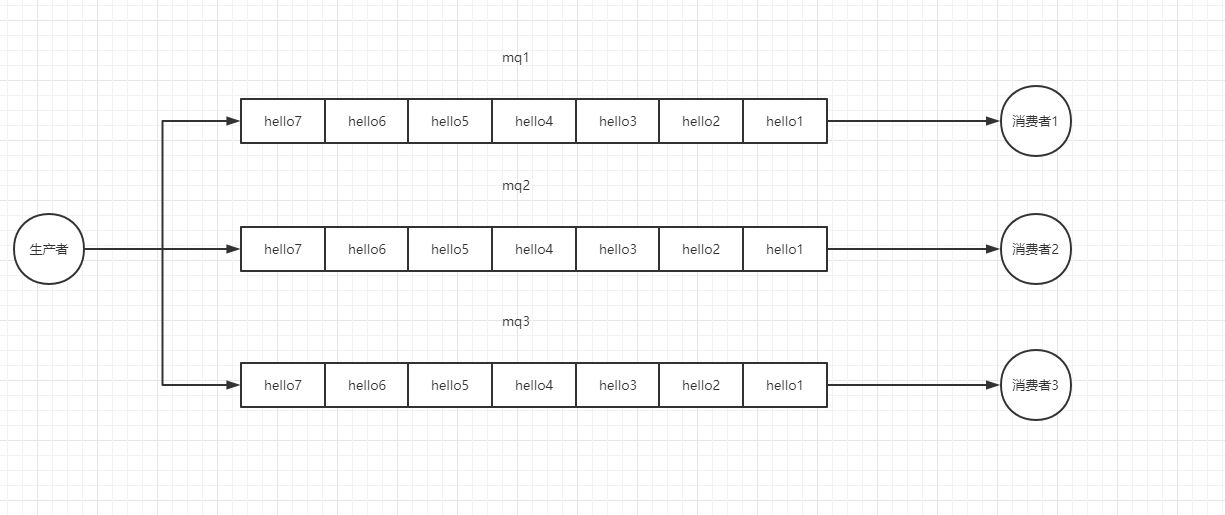
这里只需要维护一个消费者和消息队列名称映射的列表,生产者发送消息时发送给所有的消费者对应的队列。消费者读取自己对应的消息队列。
实现起来简单,但是存在两个问题:
- 资源浪费,原本只需要一个列表存储,变成了几个消费者就需要几个列表,而且列表的数据都是相同的,这无疑造成了浪费。当数据量不大,消费者不多时可以不顾及这点。
- 无法保证消息可靠的同步发送到各个队列上。如果生产者写入完 MQ1 之后就宕机了,就好导致只有消费者 1 接收到了消息,而其它的消费者无法接收到消息,这就会导致数据不一致的情况出现。
第二种实现方式,就是仍然只维护一个队列,这样使用方法 1 两个问题就没有了。但是要如何保证各个消费者能消费到数据呢?
使用
rpop肯定不行的,会导致消息丢失,所以还是得用lrange来读取数据。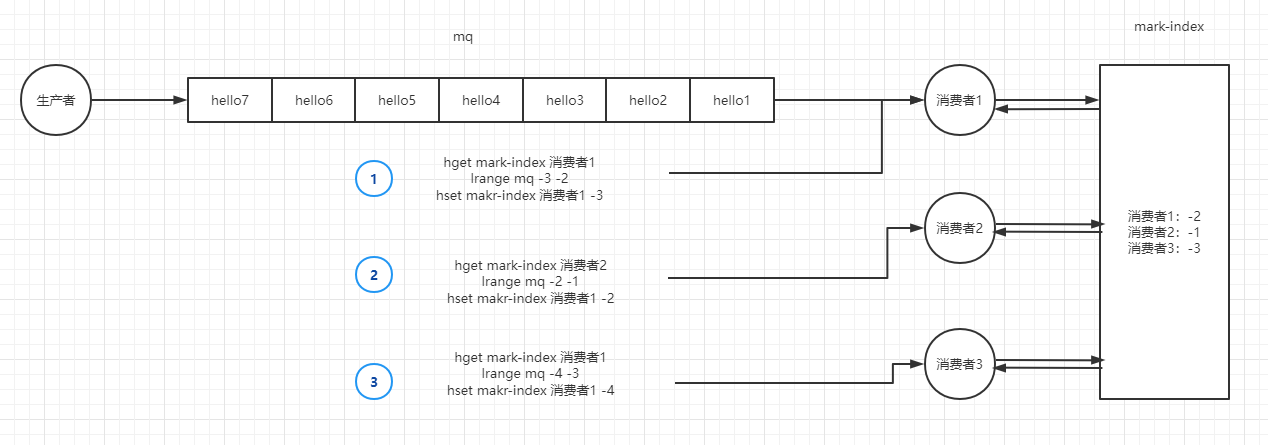
上图演示了实现的思路,
首先是维护一个读取位置的 map,保存每个消息队列读取到的位置。每个消费者读取数据时从自己上一次读取的位置继续读取。读取完成之后更新该位置。
这种方式也实现了消息应答。可以保证消费者宕机的情况下,下次能回到前次消费的坐标进行消费,以防止消息丢失。
当然这种方式也存在着问题:
消息未被清除,会一直堆积下去。这个可以通过一个定时线程清除已读取的消息并且更新所有消费者读取消息的位置。但是还要保证并发安全性,因此这个定时清除线程还需要加锁。这会造成一部分的性能损失。
3.1.5. 消息应答
消息应答机制是保证消费者可靠消费消息的有效手段。主要过程就是,消费者拿到数据之后,先进行消费的业务逻辑,消费完成之后回复消息队列一个 ACK 报文,之后消息队列才将消息移除掉。通过这种方式可以有效防止消费者宕机导致消息丢失的情况。
在 Redis 可以通过 rpoplpush 这个命令来实现 ACK 机制。
Redis rpoplpush 命令用于移除列表的最后一个元素,并将该元素添加到另一个列表并返回。
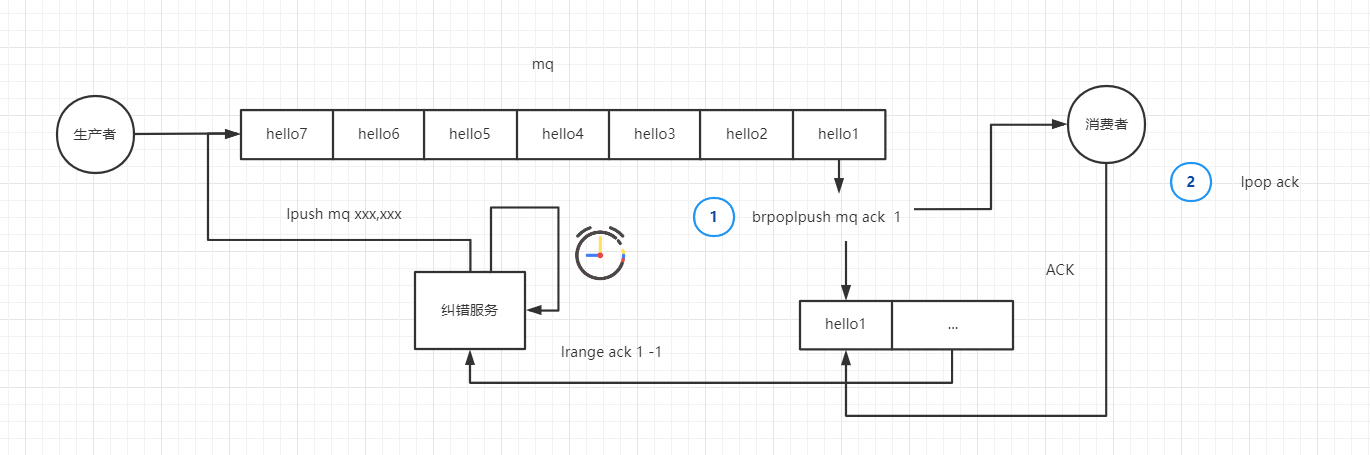
针对上图的点对点方式的消息队列,在不考虑并发消费的情况下,是可靠的(PS:并发情况下各消费者各自维护一个 ACK 队列也是可靠的)。
brpoplpush mq ack 1阻塞读取 MQ 的消息,之后写入 ACK 列表;lpop ack清除 ACK 最左侧已经消费的数据,模拟推送 ACK 报文操作;
假设这时消费者宕机,完成了步骤 1,但是未完成步骤 2,那么在 ACK 队列第一个元素之后就会备份这些未消费的数据。
再启动一个线程,作为纠错服务。定时读取 ACK 队列第二个元素及其之后的元素,重新推入 MQ,进行消费。这样可以有效的防止消息丢失。
3.1.6. List 方式的消息队列总结
- 实时性:实时性较好,可以通过 brpop 方式阻塞获取新消息,有高实时性;或者通过定时任务方式监听队列,存在较低延迟;
- 可靠性:综合可靠性一般,在点对点的消息推送机制下(
lpush+rpop方案)不容易存在消息丢失,可以保证高可靠性。在其它场景可能存在并发安全性问题,但是可以通过加锁解决。存在事务失败问题,但是发生的概率较低。存在消息丢失问题,但是可以自己实现 ACK 机制。 - 功能性:功能性一般,通过自己的额外扩展可以满足多种不同的消息队列功能,如多对多、发布订阅模式。
基于 List 的特点,可以推导出在两种常见场景下的实现方案:
针对生产者都采用 lpush 的方式推送数据,
针对消费者:
- 对实时性和可靠性要求高的情况,消费者使用
brpop阻塞读取和消费数据 - 对实时性和可靠性要求不高的情况,但是推送数据量大,要求处理性能高,消费者使用定时任务 +
lrange+ltrim方式读取和消费数据
3.2. 基于 pub-sub 实现
pub-sub 是 Redis 官方支持的一种发布订阅模式。
3.2.1. 生产者写消息
首先需要着重注意的是,pub-sub 机制和 List 不同,List 是 Redis 的数据结构,Redis 自身会保证其数据持久化的可靠性,而 pub-sub 则没有持久化机制,这意味着,如果发生消息时,消费者宕机,那么消息也就丢失了。所以该种方式是不满足可靠性要求的。
生产者发生消息使用命令 publish channel message 的方式,
例如
Bash
127.0.0.1:6379> publish mq hello1
127.0.0.1:6379> publish mq hello2
127.0.0.1:6379> publish mq hello3在发送消息时没有消费者订阅该频道的话,那么该消息就会被丢弃。
3.2.2. 消费者读取消息
消费者使用 subscribe channel 命令来订阅某个频道,其中 channel 代表频道的名称,执行该命令之后就会阻塞,直到有消息到来。
例如
消费者监听消息
Bash127.0.0.1:6379> subscribe mq Reading messages... (press Ctrl-C to quit) 1) "subscribe" 2) "mq" 3) (integer) 1在生产者发送消息
Bash127.0.0.1:6379> publish mq hello1 (integer) 1消费者监听到新消息
Bash127.0.0.1:6379> subscribe mq Reading messages... (press Ctrl-C to quit) 1) "subscribe" 2) "mq" 3) (integer) 1 1) "message" 2) "mq" 3) "hello1"
此外还可以使用 psubscribe channelLike 命令来执行通配符匹配,满足名称匹配的频道的消息都会被接收。通过这种方式可以很简单的实现一个消费者订阅多个话题。
例如
消费者监听消息
Bash127.0.0.1:6379> psubscribe mq* Reading messages... (press Ctrl-C to quit) 1) "psubscribe" 2) "mq*" 3) (integer) 1在生产者发送消息
Bash127.0.0.1:6379> publish mq1 hello1 (integer) 1 127.0.0.1:6379> publish mq2 hello2 (integer) 1消费者监听到新消息
Bash127.0.0.1:6379> psubscribe mq* Reading messages... (press Ctrl-C to quit) 1) "psubscribe" 2) "mq*" 3) (integer) 1 1) "pmessage" 2) "mq*" 3) "mq1" 4) "hello1" 1) "pmessage" 2) "mq*" 3) "mq2" 4) "hello2"
3.2.3. 多生产者多消费者
pub-sub 实现多生产者是很简单的,和点对点模式基本没有区别。但是多消费者的情况下,会出现消息被重复消费的情况。
多生产者
多个生产者向一个频道写入消息:
例如
生产者 1:
Bash127.0.0.1:6379> publish mq hello1 (integer) 1生产者 2:
Bash127.0.0.1:6379> publish mq hello2 (integer) 1
多消费者
假设有一个服务,存在两个实例,作为消费者若使用
subscribe它们是独立的两个消费者,但是作为功能而言,它们是同一个服务。如果出现多实例反复消费多次的情况下,数据的一致性就会出现问题。如果两个实例都订阅了 MQ 这个频道。那么每个消息都会被重复消费一次。
那要怎么保证并发消费时不被重复消费呢。pub-sub 本身并没有解决方案。也无法判断收到的消息是否已经被消费过。只能绕开 pub-sub。
例如让每个实例都监听不同的频道,生产者采用轮询或者随机负载算法,来将消息写入某一个指定的频道,而指定的某个频道,只有一个消费者来消费它,依靠这样的流程来实现并发消费。这种方案性能有较高的保障,但是存在一旦某个实例宕机,某个频道的消息全部都无法被消费的情况。
或者采用一个分布式锁的方式来调度这样的竞争访问。例如实例 A 读取到了消息,那么它申请一个锁,在这个锁有效期内,它可以任意的消费频道的消息。而其它竞争对手尝试获取锁失败之后,则不允许消费数据,虽然也接收到了消息,但是直接丢弃,不做处理。直到这个分布式锁释放被另一个实例占用。这种方式实现起来相对简单,但是存在着性能上的极大浪费。严重情况可能还不如单实例监听,但是多实例方案至少避免了单实例挂掉的情况下,所有消息都无法被消费的情况。
3.2.4. 发布订阅方式
pub-sub 原生就是发布订阅模式的实现,因此不再叙述,可以参考上述内容。
3.2.5. 消息应答
以下通过引入一个纠错消费者的概念来实现 ACK 机制。同时保证消息消费的可靠性。
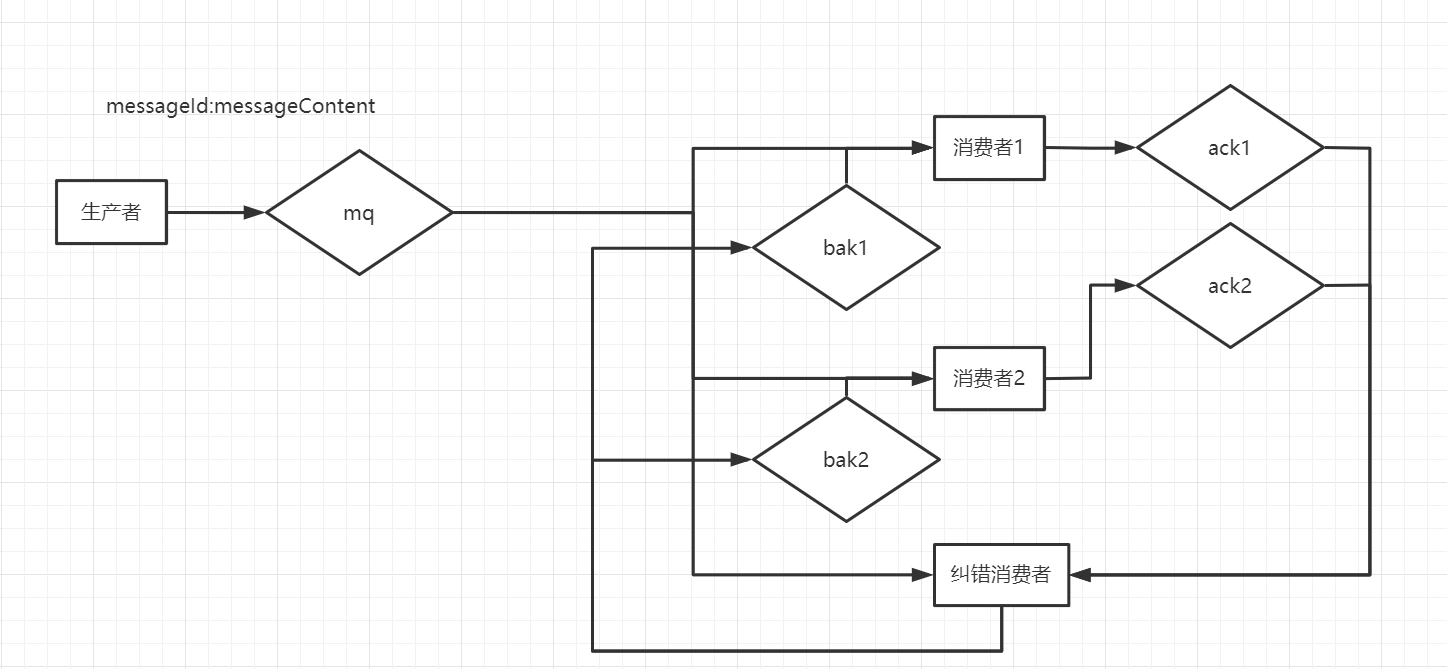
针对每一条消息,生成一个唯一不重复的 ID 来标识消息。纠错消费者接受到消息之后将其存入本地持久化 map 中,此处可以使用 Redis 或者数据库,考虑到性能采用 Redis zset 的方式会更好一些。
例如 message Msg27839:hello,Msg27839 是该条消息的唯一标识。hello 是实际的消息内容。
纠错消费者获取到该消息之后,先将其存入 Redis 中,分别存入三个 key 中,一个 key 是 Msg27839,value 是 hello,用来存储原始的消息,设置时间 ttl 为 1min。一个 key 是 zset ack1:Msg27839,score 是当前时间戳 + 30s 的时间,一个 key 是 zset ack2:Msg27839,score 也是当前时间戳 + 30s 的时间,分别代表 ack1 和 ack2 两个频道的 ack 接收确认,利用 zset 的有序性,可以很轻松的一次性读取出所有过期未收到 ack 报文的消息。
当消费者 1 消费完消息之后,向 ack1 频道发送消息,消息内容为消息 ID,纠错消费者监听到消息之后,删除 zset 中的 ack1:Msg27839。此时假设消费者 2 宕机,未能成功消费消息并且发送 ack 消息到 ack2 频道。
纠错服务定时每半分钟读取一次 zset,从 zset 取出分数小于当前时间戳的所有消息,将其重新写入到 bak1 或者 bak2 频道中。此时 ack2:Msg27839 消息未接收到 ack 报文,因此重新将其推送到频道 bak2 中进行二次消费,同时重新设置 Msg27839 这个存储原始消息的 key 的过期时间为 1min。
此处的 30s 读取一次 zset,我们认为该消费正常被处理的时间是 30s 如果超过 30s 未返回 ack 则认为是失败。
此处的原始消息存储 1min 时间,是让其能自动过期,释放空间,不用手动删除。1min 时间是 30s 的两倍,是为了保证纠错服务进行回写 bak 频道时消息仍然能被读取到。
我们假设一种场景,如果消费者 1 和消费者 2 全部宕机的情况下。那么消息也会通过纠错服务一直持久化到 Redis 中,不会导致消息丢失。一旦两个消费者恢复可用,之前的历史消息就能被纠错服务通过定时任务的方式推送给两个消费者,消息没有丢失。
基于以上的实现逻辑我们总能保证消息都会被所有消费者消费到。并且也间接实现了 pub-sub 的持久化。
3.2.6. pub-sub 方式的消息队列总结
- 实时性:实时性极好,实现的消息推送机制本身就是高实时性的。
- 可靠性:可靠性较差。一旦消费者宕机消息就会直接被丢弃。
- 功能性:功能性一般,实现简单的发布订阅还好,但是为了满足一些高可用性就需要增加很多额外的操作。
基于 pub-sub 的特点,可以推导出在其常用场景:
不在意消息丢失,不在意消息接收可靠性,需要发布订阅功能,需要高实时性的场景。这种场景一般常见于日志推送。
3.3. 基于 Redis5 的 stream 实现
Redis Stream 是 Redis 5.0 版本新增加的数据结构。
Redis Stream 主要用于消息队列(MQ,Message Queue),Redis 本身是有一个 Redis 发布订阅 (pub/sub) 来实现消息队列的功能,但它有个缺点就是消息无法持久化,如果出现网络断开、Redis 宕机等,消息就会被丢弃。
简单来说发布订阅 (pub/sub) 可以分发消息,但无法记录历史消息。
而 Redis Stream 提供了消息的持久化和主备复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失。
Redis Stream 的结构如下所示,它有一个消息链表,将所有加入的消息都串起来,每个消息都有一个唯一的 ID 和对应的内容:
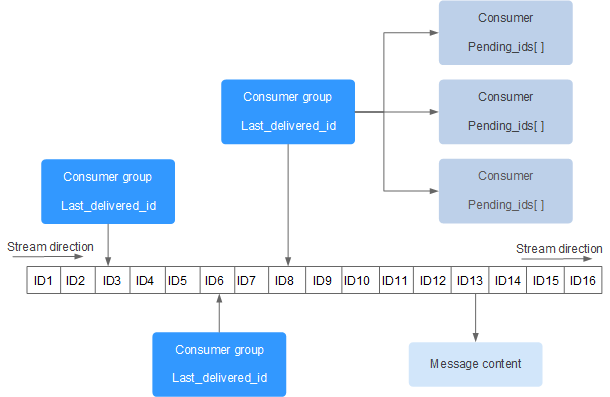
其实 redis stream 是针对 list 的一个加强,底层的数据结构也是 list。其实现原理和前文介绍的 list 实现发布订阅类似,都是通过一个标志位记录当前 consumer 消费者访问的位置。
对于一个 stream 可以对应多个 consumer group(消费者组)。一个消费者组可以包含多个消费者。
last_deliverd_id 记录了该消费者组访问到 list 的位置,也就是游标。下次读取消息时从该位置继续往前读取。需要注意的是,记录的是消费者组的位置,消费者组中任意一个消费者读取了消息都会使游标 last_delivered_id 往前移动。
pending_ids 记录了消费者(Consumer)的状态变量,作用是维护消费者的未确认的 id。pending_ids 记录了当前已经被客户端读取的消息,但是还没有 ack (Acknowledge character:确认字符)。通过这个实现了消息应答机制,保证了消息推送的可靠性。
stream 的部分命令和 list 一致,只是将 L 替换成为了 X 作为特殊标识,例如:
XADD:添加消息到末尾XTRIM:对流进行修剪,限制长度XLEN:获取流包含的元素数量,即消息长度XRANGE:获取消息列表,会自动过滤已经删除的消息
以上命令在 list 中都是存在的。
而以下命令是 stream 特有的:
XDEL- 删除消息XREVRANGE- 反向获取消息列表,ID 从大到小XREAD- 以阻塞或非阻塞方式获取消息列表XGROUPCREATE - 创建消费者组XREADGROUPGROUP - 读取消费者组中的消息XACK- 将消息标记为"已处理"XGROUP SETID- 为消费者组设置新的最后递送消息 IDXGROUP DELCONSUMER- 删除消费者XGROUP DESTROY- 删除消费者组XPENDING- 显示待处理消息的相关信息XCLAIM- 转移消息的归属权XINFO- 查看流和消费者组的相关信息;XINFO GROUPS- 打印消费者组的信息;XINFO STREAM- 打印流信息
使用 stream 之前需要保证当前的 Redis 版本>5:
Bash
$ ./redis-server -v
Redis server v=5.0.5 sha=00000000:0 malloc=jemalloc-5.1.0 bits=64 build=d448d45b28029e7需要注意的是 Windows 的 Redis 已经停止更新了,目前只到 3:
所以需要使用 Linux 版本。
3.3.1. 生产者写消息
使用 XADD key ID field value [field value ...] 来创建并写消息:
- key:队列名称,如果不存在就创建
- ID:消息 id,我们使用 * 表示由 Redis 生成,可以自定义,但是要自己保证递增性。
- field value:记录。
Bash
127.0.0.1:6379> xadd mq * msg hello
"1650865623927-0"
127.0.0.1:6379> xadd mq * msg2 hello2 msg3 hello3
"1650865654238-0"查看信息:
Bash
# 查看长度
127.0.0.1:6379> xlen mq
(integer) 2
# 查看 stream 信息
127.0.0.1:6379> xinfo stream mq
1) "length"
2) (integer) 2
3) "radix-tree-keys"
4) (integer) 1
5) "radix-tree-nodes"
6) (integer) 2
7) "groups"
8) (integer) 0
9) "last-generated-id"
10) "1650865654238-0"
11) "first-entry"
12) 1) "1650865623927-0"
2) 1) "msg"
2) "hello"
13) "last-entry"
14) 1) "1650865654238-0"
2) 1) "msg2"
2) "hello2"
3) "msg3"
4) "hello3"
# 查看数据 XRANGE key start end [COUNT count]
127.0.0.1:6379> xrange mq 1650865623927-0 1650865654238-0
1) 1) "1650865623927-0"
2) 1) "msg"
2) "hello"
2) 1) "1650865654238-0"
2) 1) "msg2"
2) "hello2"
3) "msg3"
4) "hello3"
# 使用- + 代表开始到结尾
127.0.0.1:6379> xrange mq - +
1) 1) "1650865623927-0"
2) 1) "msg"
2) "hello"
2) 1) "1650865654238-0"
2) 1) "msg2"
2) "hello2"
3) "msg3"
4) "hello3"上述已经往 stream 中写入了两条数据。
还可以使用 XTRIM 对流进行修剪,限制长度,语法格式:
XTRIM key MAXLEN [~] count
- key:队列名称
- MAXLEN:长度
- count:数量****
使用 XDEL 删除消息,语法格式:
XDEL key ID [ID ...]
- key:队列名称
- ID:消息 ID
使用 XREVRANGE 逆序获取消息列表,会自动过滤已经删除的消息,语法格式:
XREVRANGE key end start [COUNT count]
- key:队列名
- end:结束值,+ 表示最大值
- start:开始值,- 表示最小值
- count:数量
XREAD,使用 XREAD 以阻塞或非阻塞方式获取消息列表,语法格式:
XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] id [id ...]
- count:数量
- milliseconds:可选,阻塞毫秒数,没有设置就是非阻塞模式
- key:队列名
- id:消息 ID 该 ID 代表从此处开始往后读,读取大于该 ID 的数据,不包含该 ID 的数据
例如
Bash
# 读取第一条数据
127.0.0.1:6379> xread count 1 block 1000 streams mq 0-0
1) 1) "mq"
2) 1) 1) "1650865623927-0"
2) 1) "msg"
2) "hello"
# 读取 1650865623927-0 后一条数据
127.0.0.1:6379> xread count 1 block 1000 streams mq 1650865623927-0
1) 1) "mq"
2) 1) 1) "1650865654238-0"
2) 1) "msg2"
2) "hello2"
3) "msg3"
4) "hello3"3.3.2. 消费者读取消息
创建消费者组
XGROUP [CREATE key groupname id-or-$] [SETID key groupname id-or-$] [DESTROY key groupname] [DELCONSUMER key groupname consumername]
- key:队列名称,如果不存在就创建
- groupname:组名。
- id or:id 代表从该 ID 之后开始消费。:id 代表从该 ID 之后开始消费。表示从尾部开始消费,只接受新消息,当前 Stream 消息会全部忽略。
Bash
# 创建了一个名为 c 的消费者组,从头部开始消费 MQ
127.0.0.1:6379> xgroup create mq c 0-0
OK创建消费者并消费数据
XREADGROUP GROUP,使用 XREADGROUP GROUP 读取消费组中的消息,语法格式:
XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] ID [ID ...]
- group:消费组名
- consumer:消费者名,没有会自动创建。
- count:读取数量。
- milliseconds:阻塞毫秒数。
- key:队列名。
- ID:消息 ID,> 代表从头部开始。
Bash
# 为消费者组 c 创建消费者 c1 并从 MQ 读取数据,从头部开始读取
127.0.0.1:6379> xreadgroup group c c1 streams mq >
1) 1) "mq"
2) 1) 1) "1650865623927-0"
2) 1) "msg"
2) "hello"
2) 1) "1650865654238-0"
2) 1) "msg2"
2) "hello2"
3) "msg3"
4) "hello3"
# 读取 1 个、阻塞 10s,从 1650865623927-0 之后读取
127.0.0.1:6379> xreadgroup group c c1 count 1 block 10000 streams mq 1650865623927-0
1) 1) "mq"
2) 1) 1) "1650865654238-0"
2) 1) "msg2"
2) "hello2"
3) "msg3"
4) "hello3"我们使用 ack 命令标识 stream 的两条数据为已经消费完成
Bash
127.0.0.1:6379> xack mq c 1650865623927-0 1650865654238-0
(integer) 2之后再使用 xreadgroup 读取数据,因为此时队列的数据都已经消费过,所以会阻塞 10s 等待新的消息推送过来
Bash
127.0.0.1:6379> xreadgroup group c c1 count 1 block 10000 streams mq >
(nil)
(11.15s)写入一条新的消息:
Bash
127.0.0.1:6379> xadd mq * msg hi
"1650868048238-0"消费者成功接收到消息:
Bash
127.0.0.1:6379> xreadgroup group c c1 count 1 block 10000 streams mq >
1) 1) "mq"
2) 1) 1) "1650868048238-0"
2) 1) "msg"
2) "hi"
(3.62s)查看消费者状态:
Bash
127.0.0.1:6379> xinfo groups mq
1) 1) "name"
2) "c"
3) "consumers"
4) (integer) 1
5) "pending"
6) (integer) 2
7) "last-delivered-id"
8) "1650868048238-0"
127.0.0.1:6379> xinfo consumers mq c
1) 1) "name"
2) "c1"
3) "pending"
4) (integer) 2
5) "idle"
6) (integer) 270305MQ 有一个消费者组 c,c 有一个消费者 c1,c 当前读取到 1650868048238-0,可以看到该位置就是队列的末尾了。但是还有两个 pending 的,代表有两条消息没有收到 ACK,而 270305 代表其等待的时间 ms。
Bash
127.0.0.1:6379> xrange mq - +
1) 1) "1650865623927-0"
2) 1) "msg"
2) "hello"
2) 1) "1650865654238-0"
2) 1) "msg2"
2) "hello2"
3) "msg3"
4) "hello3"
3) 1) "1650867786477-0"
2) 1) "msg"
2) "hi"
4) 1) "1650867796123-0"
2) 1) "msg"
2) "hi"
5) 1) "1650867834732-0"
2) 1) "msg"
2) "hi"
6) 1) "1650868048238-0"
2) 1) "msg"
2) "hi"使用 xpending 查看这两条数据:
xpendign key groupName [start end count] [consumerName]
Bash
127.0.0.1:6379> xpending mq c
1) (integer) 2
2) "1650867834732-0"
3) "1650868048238-0"
4) 1) 1) "c1"
2) "2"原来是"1650867834732-0","1650868048238-0"没有被成功消费掉。
发送 ack,再查看已经没有 pending 的消息了。
Bash
127.0.0.1:6379> xack mq c 1650867834732-0 1650868048238-0
(integer) 2
127.0.0.1:6379> xpending mq c
1) (integer) 0
2) (nil)
3) (nil)
4) (nil)这些 pending 的数据,同个消费者组下的其它消费者也是读取不到的。
Redis 会对这些 pending 的消息做数据恢复吗?答案是不会,需要手动去处理它,使用 xdel 将其删除,然后重新写入 MQ。需要注意的是 xdel 不会删除 pending 的数据,需要在重新写入完成之后将其 ack。
例如当前有一条未 ack 的消息:
Bash
127.0.0.1:6379> xpending mq c - + 10 c1
1) 1) "1650868714168-0"
2) "c1"
3) (integer) 156886
4) (integer) 1我们可以这样操作,将其删除,重新写入 MQ,然后 ack。消费者再次读取时就没有问题了。
Bash
127.0.0.1:6379> xdel mq 1650868714168-0
(integer) 1
127.0.0.1:6379> xpending mq c
1) (integer) 1
2) "1650868714168-0"
3) "1650868714168-0"
4) 1) 1) "c1"
2) "1"
127.0.0.1:6379> xadd mq * msg hi
"1650869436235-0"
127.0.0.1:6379> xack mq c 1650868714168-0
(integer) 1
127.0.0.1:6379> xpending mq c
1) (integer) 0
2) (nil)
3) (nil)
4) (nil)
127.0.0.1:6379> xreadgroup group c c2 count 1 block 10000 streams mq >
1) 1) "mq"
2) 1) 1) "1650869436235-0"
2) 1) "msg"
2) "hi"
127.0.0.1:6379> xack mq c 1650869436235-0
(integer) 1
127.0.0.1:6379> xpending mq c
1) (integer) 0
2) (nil)
3) (nil)
4) (nil)除了删除重新写入的场景之外,还可以使用 xclaim 来做消息转移。xclaim 可以将消息转移到同消费者组的另一个消费者的 pending 队列中,同时其还会返回消息内容。如果某个消费者故障,转移到另一个消费者受理是一个不错的方式。

解释:XCLAIM 命令用于进行消息转移,当某个等待队列中的消息长时间没有被处理(没有 ACK)的时候,可以用 XCLAIM 命令将其转移到其他消费者的等待列表中。
key:表示消息队列的名称;group:表示消费者组名称;consumer:表示消费者名称;min-idle-time:表示消息空闲时长(表示消息已经读取,但还未处理);ID [ID …]:可选参数,表示要转移的消息的消息 ID,可传入多个消息 ID;[IDLE ms]:可选参数,设置消息空闲时间(上一次读取消息的时间),如果未指定,这假定 IDLE 为 0,即每次转移消息之后重置消息空闲时间。因为如果空闲时间一直累加的话,消息会一直转移;[TIME ms-unix-time]:可选参数,与 IDLE 参数相同,只是它将空闲时间设置为特定的 Unix 时间(以毫秒为单位),而不是相对的毫秒量。这对于重写生成 XCLAIM 命令的 AOF 文件非常有用;[RETRYCOUNT count]:可选参数,设置重试计数器的值,每次消息被读取时,该计数器都会递增。一般 XCLAIM 命令不需要修改重试计数器的值;[FORCE]:可选参数,即使指定要转移的消息的消息 ID 在其他等待列表中不存在,也强制将该消息 ID 加入到执行消费者的等待列表中;[JUSTID]:可选参数,仅返回要转移消息的消息 ID,使用此参数意味着重试计数器不会递增。
3.3.3. 多生产者多消费者
多生产者
只要都使用 xadd 命令往同一个 stream 写入即可。
多消费者
创建一个消费者组,将多个消费者都包含进该消费者组中,即可。
3.3.4. 发布订阅方式
实现多个消费者组监听同一个 stream 即可。
3.3.5. 消息应答
使用 strean 的原生的 ack 机制即可。不过需要注意,对应 pending 的数据需要安排一个线程定时去处理和恢复。
3.3.6. stream 方式的消息队列总结
- 实时性:实时性好,可以通过 block 方式阻塞获取新消息,有高实时性;
- 可靠性:可靠性好,Redis 的自带的持久化机制可以防止消息丢失,但是相比 Kafka 的磁盘写入还是略不可靠。自带的 ack 机制可以满足消息应答实现,防止消息丢失。但是需要注意对于死信息积压在 pending 区的数据需要定时去处理回收。此外,积压的消息会一直保存在 stream 中,哪怕已经 ack 过,还需要额外的一个线程定时将已经读取完的消息删除。
- 功能性:功能性好,可以轻松实现多种不同的消息队列功能,如多对多、发布订阅模式。 基于 stream 的特点,可以推导出在其常用场景:
大部分使用消息队列的场景都可以使用 stream 替代。基于 Redis 的高性能和使用内存的机制使得其的性能优于大部分消息队列。在小规模场景会有更出色的表现。但是针对大流量的场景不推荐使用 stream,毕竟内存的大小是有限的,这也是所有 Redis 实现的消息队列的局限之处。