Appearance
Hello ElasticSearch - 相关性评分
ElasticSearch 的相关性评分用于衡量文档与用户查询的匹配程度。默认情况下,ElasticSearch 使用 BM25 算法作为其相关性评分模型(自 5.0 版本起)。
1. TF(词频)
TF(Term Frequency)是指查询中的某个词(term)在文档特定字段中出现的频率。TF 的核心思想是:一个词在文档中出现得越多,说明该文档与这个词的相关性越高。
公式如下:
:查询中的词; :文档; :词 在文档 中出现的次数。
信息
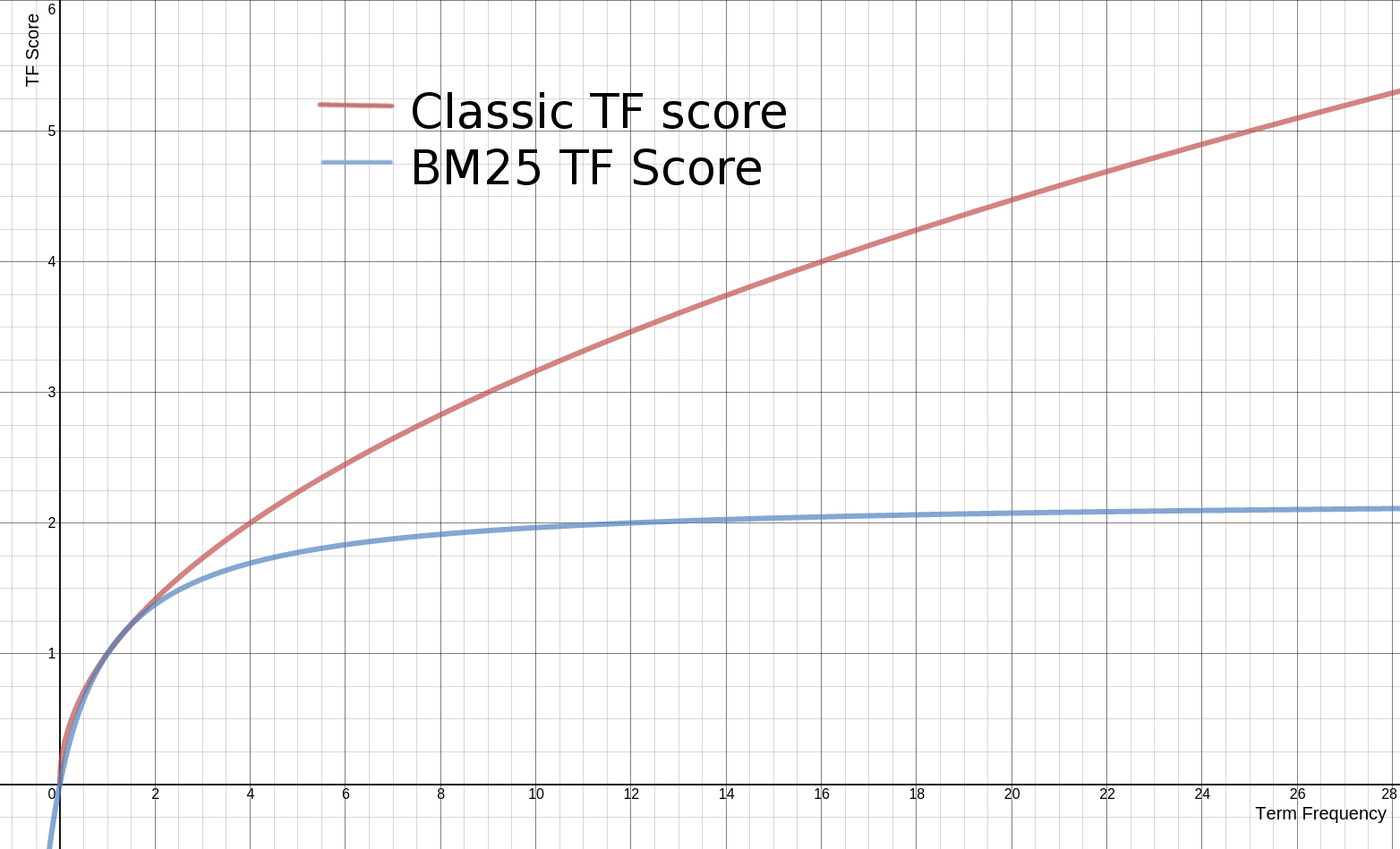
ElasticSearch 对原始词频取平方根,防止高频词对评分的影响过大。
高 TF 值通常意味着文档更相关。但单纯依赖 TF 可能导致问题,比如常见词(如 “的”、“是”)出现频率高但意义不大,因此需要结合 IDF。
2. IDF(逆文档频率)
IDF(Inverse Document Frequency)衡量一个词的稀有性。如果一个词在索引中的文档中出现得很少(稀有),它的 IDF 值较高,说明它对区分相关文档更有价值。
公式如下:
:索引中总文档数; :包含词 的文档数; - 使用对数函数平滑 IDF 值,防止稀有词的权重过高。
常见词(如 “的”)在许多文档中出现,IDF 值低。稀有词(如专业术语)在少数文档中出现,IDF 值高。IDF 帮助降低常见词对相关性评分的影响,提升稀有词的权重。
3. TF-IDF(传统模型)
在 ElasticSearch 早期版本(如 2.x 及之前),默认使用 TF-IDF 模型。TF-IDF 是 BM25 的前身,结合了 TF 和 IDF,但没有 BM25 的饱和机制和字段长度归一化优化。
简化的 TF-IDF 公式如下:
:查询中匹配的词比例(协调因子); :查询归一化因子,确保不同查询的评分可比较。
TF 增长无上限,可能导致高频词过度影响评分。缺乏字段长度归一化,容易偏向长文档。协调因子可能导致短查询的评分不稳定。
由于这些问题,ElasticSearch 从 5.0 开始用 BM25 替换了 TF-IDF。
4. BM25 算法
ElasticSearch 默认使用 BM25(Best Matching 25)算法作为相关性评分模型。BM25 是一种基于概率的排名函数,结合了 TF 和 IDF,并引入了字段长度归一化和参数调节,以更精确地评估文档相关性。
公式如下:
:查询; :文档; :查询中的词; :词 在文档 中的词频; :词 的逆文档频率; :控制 TF 饱和度的参数(默认 1.2),防止高频词对评分影响过大;:控制字段长度归一化影响的参数(默认 0.75),值越大,字段长度对评分影响越大;:文档字段长度; :索引中所有文档字段的平均长度。
TF 饱和:通过
优点:
- 比传统的 TF-IDF 更鲁棒,避免了 TF 无限增长导致的偏差;
- 平衡了词频、稀有性和字段长度,适用于多种搜索场景;
- 在实际应用中,BM25 的性能优于早期 TF-IDF 模型,尤其在大规模文档集上。