Appearance
Hello XXL-Job
简介
文档 & 源码
源码目录说明
Text
.
├── doc / -------------------------------- # 文档资料
│ └── db ------------------------------- # 调度中心表结构定义
├── xxl-job-admin ------------------------ # 调度中心
├── xxl-job-core ------------------------- # 公共依赖
└── xxl-job-executor-samples / ----------- # 执行器示例
├── xxl-job-executor-sample-springboot # Spring Boot 版
└── xxl-job-executor-sample-frameless # 无框架版环境要求
- Maven 3+
- JDK 17+ (>= 3.x) | JDK 1.8+ (<= 2.x)
- MySQL 8.0+
快速开始
调度中心部署
数据库初始化
XXL-JOB 调度中心依赖 MySQL 数据库,在启动调度中心之前需要先初始化数据库表结构。数据库表结构初始化脚本位于源码目录下:
Text
/doc/db/tables_xxl_job.sqlSQL
#
# XXL-JOB
# Copyright (c) 2015-present, xuxueli.
CREATE database if NOT EXISTS `xxl_job` default character set utf8mb4 collate utf8mb4_unicode_ci;
use `xxl_job`;
SET NAMES utf8mb4;
CREATE TABLE `xxl_job_info`
(
`id` int(11) NOT NULL AUTO_INCREMENT,
`job_group` int(11) NOT NULL COMMENT '执行器主键ID',
`job_desc` varchar(255) NOT NULL,
`add_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
`author` varchar(64) DEFAULT NULL COMMENT '作者',
`alarm_email` varchar(255) DEFAULT NULL COMMENT '报警邮件',
`schedule_type` varchar(50) NOT NULL DEFAULT 'NONE' COMMENT '调度类型',
`schedule_conf` varchar(128) DEFAULT NULL COMMENT '调度配置,值含义取决于调度类型',
`misfire_strategy` varchar(50) NOT NULL DEFAULT 'DO_NOTHING' COMMENT '调度过期策略',
`executor_route_strategy` varchar(50) DEFAULT NULL COMMENT '执行器路由策略',
`executor_handler` varchar(255) DEFAULT NULL COMMENT '执行器任务handler',
`executor_param` varchar(512) DEFAULT NULL COMMENT '执行器任务参数',
`executor_block_strategy` varchar(50) DEFAULT NULL COMMENT '阻塞处理策略',
`executor_timeout` int(11) NOT NULL DEFAULT '0' COMMENT '任务执行超时时间,单位秒',
`executor_fail_retry_count` int(11) NOT NULL DEFAULT '0' COMMENT '失败重试次数',
`glue_type` varchar(50) NOT NULL COMMENT 'GLUE类型',
`glue_source` mediumtext COMMENT 'GLUE源代码',
`glue_remark` varchar(128) DEFAULT NULL COMMENT 'GLUE备注',
`glue_updatetime` datetime DEFAULT NULL COMMENT 'GLUE更新时间',
`child_jobid` varchar(255) DEFAULT NULL COMMENT '子任务ID,多个逗号分隔',
`trigger_status` tinyint(4) NOT NULL DEFAULT '0' COMMENT '调度状态:0-停止,1-运行',
`trigger_last_time` bigint(13) NOT NULL DEFAULT '0' COMMENT '上次调度时间',
`trigger_next_time` bigint(13) NOT NULL DEFAULT '0' COMMENT '下次调度时间',
PRIMARY KEY (`id`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
CREATE TABLE `xxl_job_log`
(
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`job_group` int(11) NOT NULL COMMENT '执行器主键ID',
`job_id` int(11) NOT NULL COMMENT '任务,主键ID',
`executor_address` varchar(255) DEFAULT NULL COMMENT '执行器地址,本次执行的地址',
`executor_handler` varchar(255) DEFAULT NULL COMMENT '执行器任务handler',
`executor_param` varchar(512) DEFAULT NULL COMMENT '执行器任务参数',
`executor_sharding_param` varchar(20) DEFAULT NULL COMMENT '执行器任务分片参数,格式如 1/2',
`executor_fail_retry_count` int(11) NOT NULL DEFAULT '0' COMMENT '失败重试次数',
`trigger_time` datetime DEFAULT NULL COMMENT '调度-时间',
`trigger_code` int(11) NOT NULL COMMENT '调度-结果',
`trigger_msg` text COMMENT '调度-日志',
`handle_time` datetime DEFAULT NULL COMMENT '执行-时间',
`handle_code` int(11) NOT NULL COMMENT '执行-状态',
`handle_msg` text COMMENT '执行-日志',
`alarm_status` tinyint(4) NOT NULL DEFAULT '0' COMMENT '告警状态:0-默认、1-无需告警、2-告警成功、3-告警失败',
PRIMARY KEY (`id`),
KEY `I_trigger_time` (`trigger_time`),
KEY `I_handle_code` (`handle_code`),
KEY `I_jobid_jobgroup` (`job_id`,`job_group`),
KEY `I_job_id` (`job_id`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
CREATE TABLE `xxl_job_log_report`
(
`id` int(11) NOT NULL AUTO_INCREMENT,
`trigger_day` datetime DEFAULT NULL COMMENT '调度-时间',
`running_count` int(11) NOT NULL DEFAULT '0' COMMENT '运行中-日志数量',
`suc_count` int(11) NOT NULL DEFAULT '0' COMMENT '执行成功-日志数量',
`fail_count` int(11) NOT NULL DEFAULT '0' COMMENT '执行失败-日志数量',
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `i_trigger_day` (`trigger_day`) USING BTREE
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
CREATE TABLE `xxl_job_logglue`
(
`id` int(11) NOT NULL AUTO_INCREMENT,
`job_id` int(11) NOT NULL COMMENT '任务,主键ID',
`glue_type` varchar(50) DEFAULT NULL COMMENT 'GLUE类型',
`glue_source` mediumtext COMMENT 'GLUE源代码',
`glue_remark` varchar(128) NOT NULL COMMENT 'GLUE备注',
`add_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
CREATE TABLE `xxl_job_registry`
(
`id` int(11) NOT NULL AUTO_INCREMENT,
`registry_group` varchar(50) NOT NULL,
`registry_key` varchar(255) NOT NULL,
`registry_value` varchar(255) NOT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `i_g_k_v` (`registry_group`, `registry_key`, `registry_value`) USING BTREE
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
CREATE TABLE `xxl_job_group`
(
`id` int(11) NOT NULL AUTO_INCREMENT,
`app_name` varchar(64) NOT NULL COMMENT '执行器AppName',
`title` varchar(12) NOT NULL COMMENT '执行器名称',
`address_type` tinyint(4) NOT NULL DEFAULT '0' COMMENT '执行器地址类型:0=自动注册、1=手动录入',
`address_list` text COMMENT '执行器地址列表,多地址逗号分隔',
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
CREATE TABLE `xxl_job_user`
(
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(50) NOT NULL COMMENT '账号',
`password` varchar(50) NOT NULL COMMENT '密码',
`role` tinyint(4) NOT NULL COMMENT '角色:0-普通用户、1-管理员',
`permission` varchar(255) DEFAULT NULL COMMENT '权限:执行器ID列表,多个逗号分割',
PRIMARY KEY (`id`),
UNIQUE KEY `i_username` (`username`) USING BTREE
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
CREATE TABLE `xxl_job_lock`
(
`lock_name` varchar(50) NOT NULL COMMENT '锁名称',
PRIMARY KEY (`lock_name`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
## —————————————————————— init data ——————————————————
INSERT INTO `xxl_job_group`(`id`, `app_name`, `title`, `address_type`, `address_list`, `update_time`)
VALUES (1, 'xxl-job-executor-sample', '示例执行器', 0, NULL, '2018-11-03 22:21:31');
INSERT INTO `xxl_job_info`(`id`, `job_group`, `job_desc`, `add_time`, `update_time`, `author`, `alarm_email`,
`schedule_type`, `schedule_conf`, `misfire_strategy`, `executor_route_strategy`,
`executor_handler`, `executor_param`, `executor_block_strategy`, `executor_timeout`,
`executor_fail_retry_count`, `glue_type`, `glue_source`, `glue_remark`, `glue_updatetime`,
`child_jobid`)
VALUES (1, 1, '测试任务1', '2018-11-03 22:21:31', '2018-11-03 22:21:31', 'XXL', '', 'CRON', '0 0 0 * * ? *',
'DO_NOTHING', 'FIRST', 'demoJobHandler', '', 'SERIAL_EXECUTION', 0, 0, 'BEAN', '', 'GLUE代码初始化',
'2018-11-03 22:21:31', '');
INSERT INTO `xxl_job_user`(`id`, `username`, `password`, `role`, `permission`)
VALUES (1, 'admin', 'e10adc3949ba59abbe56e057f20f883e', 1, NULL);
INSERT INTO `xxl_job_lock` (`lock_name`)
VALUES ('schedule_lock');
commit;| 表名 | 说明 |
|---|---|
xxl_job_lock | 任务调度锁表 |
xxl_job_group | 执行器信息表,维护任务执行器信息 |
xxl_job_info | 调度扩展信息表:用于保存 XXL-JOB 调度任务的扩展信息,如任务分组、任务名、机器地址、执行器、执行入参和报警邮件等等 |
xxl_job_log | 调度日志表:用于保存 XXL-JOB 任务调度的历史信息,如调度结果、执行结果、调度入参、调度机器和执行器等等 |
xxl_job_log_report | 调度日志报表:用户存储 XXL-JOB 任务调度日志的报表,调度中心报表功能页面会用到 |
xxl_job_logglue | 任务 GLUE 日志:用于保存 GLUE 更新历史,用于支持 GLUE 的版本回溯功能 |
xxl_job_registry | 执行器注册表,维护在线的执行器和调度中心机器地址信息 |
xxl_job_user | 系统用户表 |
源码编译部署
根据需要修改配置文件:
Text
/xxl-job-admin/src/main/resources/application.properties正常编译打包部署 JAR 项目即可。
Docker 部署
Bash
docker run -d \
--name xxl-job-admin \
-e PARAMS="--spring.datasource.url=jdbc:mysql://127.0.0.1:3306/xxl_job?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai" \
-p 8080:8080 \
-v xxl-job-log:/data/applogs \
xuxueli/xxl-job-admin:VERSION支持如下环境变量:
PARAMS:指定配置参数/xxl-job-admin/src/main/resources/application.properties中的所有配置项都可以通过该环境变量指定。参数格式:ABNFrule = 1*("--" key "=" value)JAVA_OPTS:JVM 参数LOG_HOME:日志文件目录
集群化部署
调度中心集群部署需满足如下条件:
- 连接同一个 MySQL 实例
- 集群机器时钟同步
信息
推荐搭配 Nginx 配置负载均衡。
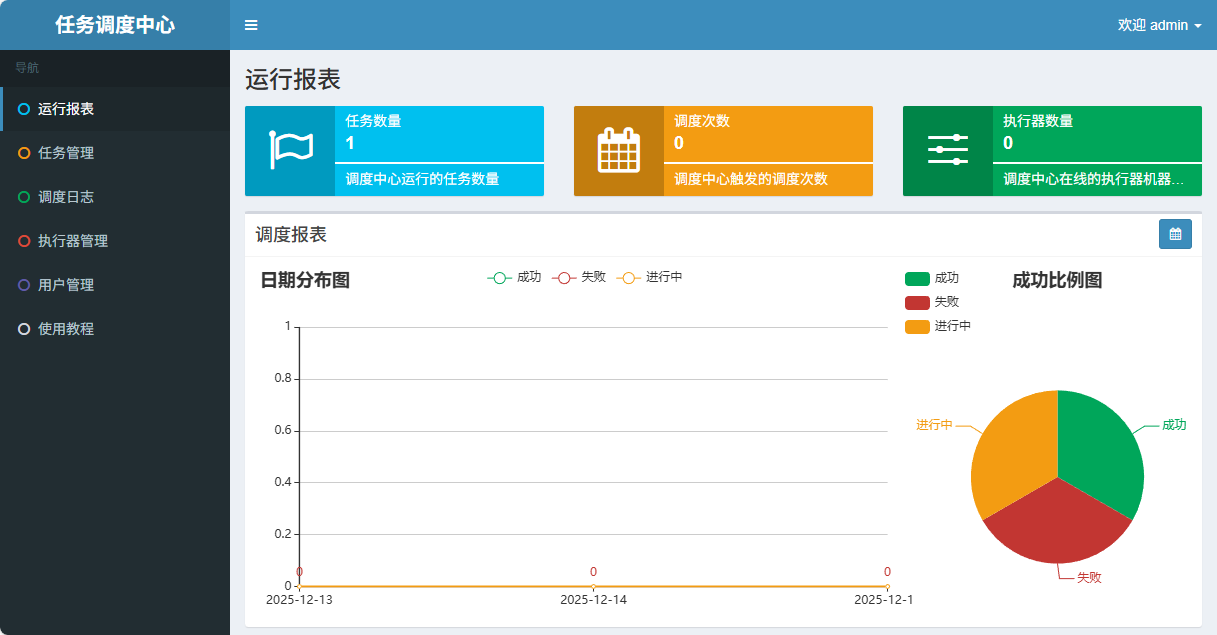
访问控制台
- 默认访问地址:
http://localhost:8080/xxl-job-admin - 默认账号密码:
admin/123456
执行器部署
引入依赖
XML
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
<version>${xxl-job.version}</version>
</dependency>执行器配置
配置文件:
YAML
xxl:
job:
admin:
addresses: http://127.0.0.1:8080/xxl-job-admin
accessToken: default_token
timeout: 3
executor:
enabled: true
appname: xxl-job-executor-sample
address:
ip: localhost
port: 9999
logpath: /data/applogs/xxl-job/jobhandler
logretentiondays: 30注册 XxlJobSpringExecutor Bean 实例:
Java
@Configuration
@Slf4j
public class XxlJobConfig {
@Value("${xxl.job.admin.addresses}")
private String adminAddresses;
@Value("${xxl.job.admin.accessToken}")
private String accessToken;
@Value("${xxl.job.admin.timeout}")
private int timeout;
@Value("${xxl.job.executor.appname}")
private String appname;
@Value("${xxl.job.executor.address}")
private String address;
@Value("${xxl.job.executor.ip}")
private String ip;
@Value("${xxl.job.executor.port}")
private int port;
@Value("${xxl.job.executor.logpath}")
private String logPath;
@Value("${xxl.job.executor.logretentiondays}")
private int logRetentionDays;
@Bean
@ConditionalOnProperty(prefix = "xxl.job.executor", name = "enabled")
public XxlJobSpringExecutor xxlJobExecutor() {
log.info("xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setTimeout(timeout);
xxlJobSpringExecutor.setAppname(appname);
xxlJobSpringExecutor.setAddress(address);
xxlJobSpringExecutor.setIp(ip);
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setLogPath(logPath);
xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);
return xxlJobSpringExecutor;
}
}添加 @XxlJob 注解(Bean 模式)
为 Service Bean 的 Job 方法添加 @XxlJob 注解:
Java
@Service
public class YourJobService {
@XxlJob("demoJobHandler")
public void demoJobHandler() {
XxlJobHelper.log("hello xxl-job");
}
}信息
在 Service 方法中添加 @XxlJob 注解的方式为 Bean 模式,更多模式请参考任务模式。
至此,正常启动/部署应用程序。
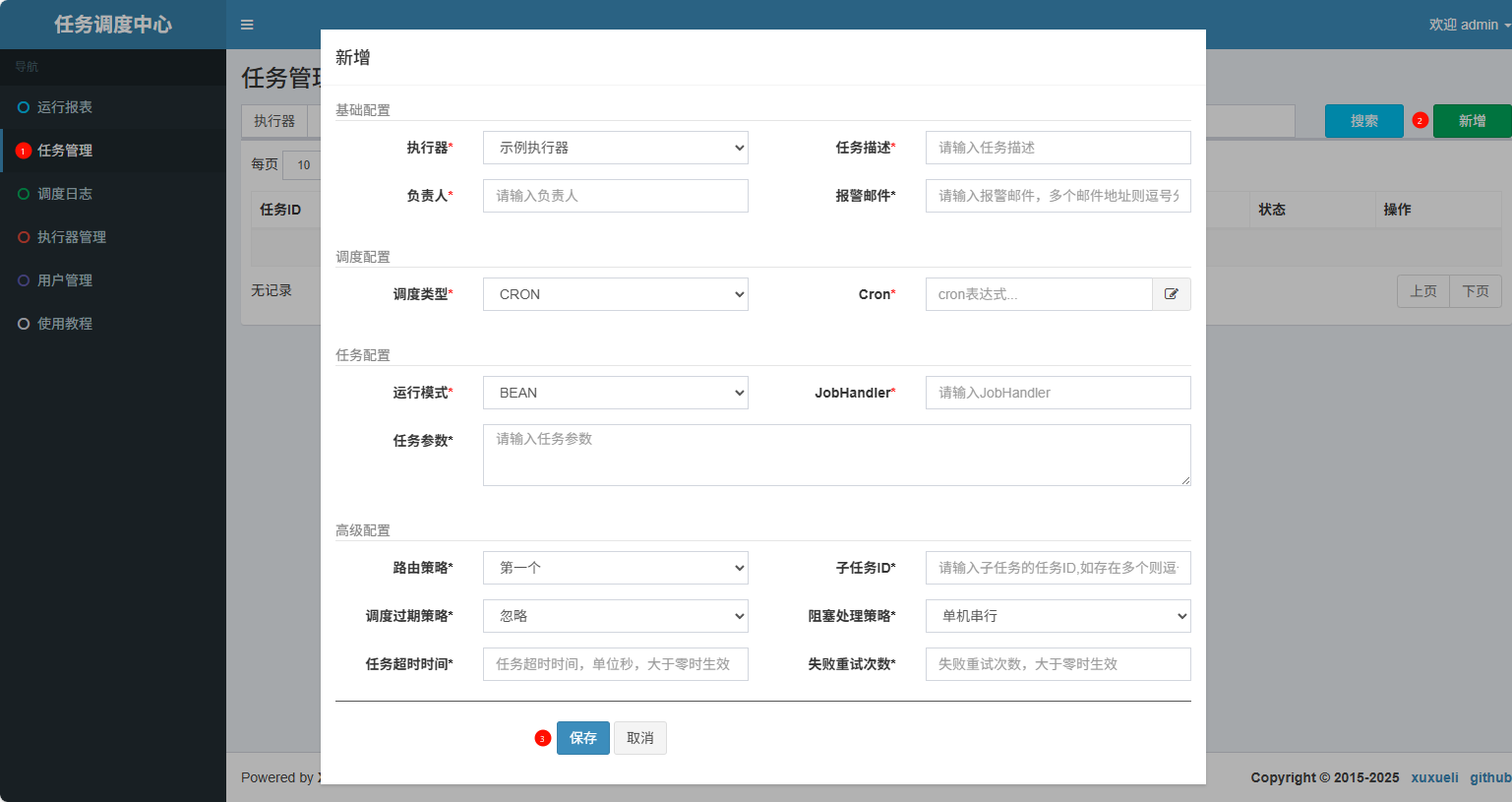
任务配置
新建任务
在调度中心控制台中新建任务:
启动任务
新建完成后回到任务管理列表,找到对应的任务点击右侧的「操作 > 启动」按钮,启动任务。
任务模式
Bean 模式(类形式)
Bean 任务模式,支持基于类的开发方式,每个任务对应一个 Java 类。
- 优点:兼容性好,无框架依赖(参考示例项目
xxl-job-executor-sample-frameless); - 缺点:
- 需要为每个任务单独编写一个 JobHandler 类;
- 需要手动注入,不支持自动扫描任务并注入到执行器容器。
实现步骤:
新建一个 JobHandler 类,继承自
com.xxl.job.core.handler.IJobHandler,并实现execute抽象方法;注册 JobHandler
JavaXxlJobExecutor.registJobHandler("demoJobHandler", new DemoJobHandler());
Bean 模式(方法形式)
Bean 任务模式,支持基于方法的开发方式,每个任务对应一个方法。
- 优点:
- 每个任务只需要开发一个方法,并添加
@XxlJob注解即可,更加方便、快速; - 支持自动扫描任务并注入到执行器容器。
- 每个任务只需要开发一个方法,并添加
- 缺点:依赖 Spring 框架。
信息
基于方法开发的任务,底层会生成 JobHandler 代理,和基于类的方式一样,任务也会以 JobHandler 的形式存在于执行器任务容器中。
实现步骤:为 Service Bean 的 Job 方法添加 @XxlJob 注解即可。
GLUE 模式
与 Bean 模式不同,GLUE 模式的任务实现代码在调度中心实现(Bean 模式在执行器中实现)。
- 优点:
- 无代码入侵,无需修改执行器项目的代码;
- 天然支持热更新;
- 支持版本回溯(30 个版本)。
实现步骤:
在调度中心控制台中新建任务时,运行模式选择 GLUE 相关的模式,以下以 GLUE(Java) 为例;
找到对应的任务点击右侧的「操作 > GLUE IDE」按钮,编写任务代码。
Groovypublic class DemoGlueJobHandler extends IJobHandler { @Override public void execute() throws Exception { XxlJobHelper.log("XXL-JOB, Hello World."); } }
GLUE(Java) 模式的任务实际上是一段继承自 IJobHandler 的 Java 类代码并以 Groovy 源码方式维护,它在执行器项目中运行,可使用 @Resource/@Autowire 注入执行器容器中的 Bean。
架构设计
设计思想
将调度行为抽象形成 “调度中心” 公共平台,而平台自身并不承担业务逻辑,“调度中心” 负责发起调度请求。
将任务抽象成分散的 JobHandler,交由 “执行器” 统一管理,“执行器” 负责接收调度请求并执行对应的 JobHandler 中的业务逻辑。
因此,“调度” 和 “任务” 两部分可以相互解耦,提高系统整体稳定性和扩展性;
系统组成
调度模块(调度中心)
负责管理调度信息,按照调度配置发出调度请求,自身不承担业务代码。调度系统与任务解耦,提高了系统可用性和稳定性,同时调度系统性能不再受限于任务模块。
支持可视化、简单且动态的管理调度信息,包括任务新建、更新、删除,GLUE 开发和任务报警等,所有上述操作都会实时生效,同时支持监控调度结果以及执行日志,支持执行器 Failover。
执行模块(执行器)
负责接收调度请求并执行任务逻辑。任务模块专注于任务的执行等操作,开发和维护更加简单和高效。
接收 “调度中心” 的执行请求、终止请求和日志请求等。
调度模块
调度中心集群
基于数据库的集群方案,数据库选用 MySQL。集群分布式并发环境中进行定时任务调度时,会在各个节点上报任务,存到数据库中,执行时会从数据库中取出触发器来执行,如果触发器的名称和执行时间相同,则只有一个节点去执行此任务。
调度线程池
调度采用线程池方式实现,避免单线程因阻塞而引起任务调度延迟。
并行调度
XXL-JOB 调度模块默认采用并行机制,在多线程调度的情况下,调度模块被阻塞的几率很低,大大提高了调度系统的承载量。
XXL-JOB 的不同任务之间并行调度、并行执行。
XXL-JOB 的单个任务,针对多个执行器是并行运行的,针对单个执行器是串行执行的。同时支持任务终止。
过期处理策略
任务调度错过触发时间时的处理策略:
- 可能原因:服务重启、调度线程被阻塞,线程被耗尽、上次调度持续阻塞,下次调度被错过;
- 处理策略:
- 过期超 5s:本次忽略,当前时间开始计算下次触发时间;
- 过期 5s 内:立即触发一次,当前时间开始计算下次触发时间。
日志回调服务
调度模块的 “调度中心” 作为 Web 服务部署时,一方面承担调度中心功能,另一方面也为执行器提供 API 服务。
调度中心提供的 “日志回调服务 API 服务” 代码位置如下:
Text
com.xxl.job.admin.controller.JobApiController.callback“执行器” 在接收到任务执行请求后,执行任务,在执行结束之后会将执行结果回调通知 “调度中心”:
任务 HA(Failover)
执行器如若集群部署,调度中心将会感知到在线的所有执行器,如 “127.0.0.1:9997, 127.0.0.1:9998, 127.0.0.1:9999”。
当任务 “路由策略” 选择 “故障转移(FAILOVER)” 时,当调度中心每次发起调度请求时,会按照顺序对执行器发出心跳检测请求,第一个检测为存活状态的执行器将会被选定并发送调度请求。
调度成功后,可在日志监控界面查看 “调度备注”。
“调度备注” 可以看出本地调度运行轨迹,执行器的 “注册方式”、“地址列表” 和任务的 “路由策略”。“故障转移(FAILOVER)” 路由策略下,调度中心首先对第一个地址进行心跳检测,心跳失败因此自动跳过,第二个依然心跳检测失败……直至心跳检测第三个地址 “127.0.0.1:9999” 成功,选定为 “目标执行器”。然后对 “目标执行器” 发送调度请求,调度流程结束,等待执行器回调执行结果。
调度日志
调度中心每次进行任务调度,都会记录一条任务日志,可以通过 “XxlJobHelper.log” 打印执行日志,“调度中心” 查看执行日志时将会加载对应的日志文件。
日志文件存放的位置可在 “执行器” 配置文件进行自定义,默认目录格式为:/data/applogs/xxl-job/jobhandler/格式化日期/数据库调度日志记录的主键 ID.log。
在 JobHandler 中开启子线程时,子线程将会把日志打印在父线程即 JobHandler 的执行日志中,方便日志追踪。
任务日志主要包括以下三部分内容:
- 任务信息:包括 “执行器地址”、“JobHandler” 和 “执行参数” 等属性,点击任务 ID 按钮可查看,根据这些参数,可以精确的定位任务执行的具体机器和任务代码;
- 调度信息:包括 “调度时间”、“调度结果” 和 “调度日志” 等,根据这些参数,可以了解 “调度中心” 发起调度请求时的具体情况;
- 执行信息:包括 “执行时间”、“执行结果” 和 “执行日志” 等,根据这些参数,可以了解在 “执行器” 端任务执行的具体情况。
调度日志,针对单次调度,属性说明如下:
- 执行器地址:任务执行的机器地址;
- JobHandler:Bean 模式表示任务执行的 JobHandler 名称;
- 任务参数:任务执行的入参;
- 调度时间:调度中心,发起调度的时间;
- 调度结果:调度中心,发起调度的结果,SUCCESS 或 FAIL;
- 调度备注:调度中心,发起调度的备注信息,如地址心跳检测日志等;
- 执行时间:执行器,任务执行结束后回调的时间;
- 执行结果:执行器,任务执行的结果,SUCCESS 或 FAIL;
- 执行备注:执行器,任务执行的备注信息,如异常日志等;
- 执行日志:任务执行过程中,业务代码中打印的完整执行日志。
任务依赖
原理:XXL-JOB 中每个任务都对应有一个任务 ID,同时,每个任务支持设置属性 “子任务 ID”,因此,通过 “任务 ID” 可以匹配任务依赖关系。
当父任务执行结束并且执行成功时,将会根据 “子任务 ID” 匹配子任务依赖,如果匹配到子任务,将会主动触发一次子任务的执行。
在任务日志界面,点击任务的 “执行备注” 的 “查看” 按钮,可以看到匹配子任务以及触发子任务执行的日志信息,如无信息则表示未触发子任务执行。
全异步化 & 轻量级
- 全异步化设计:XXL-JOB 系统中业务逻辑在远程执行器执行,触发流程全异步化设计。相比直接在调度中心内部执行业务逻辑,极大的降低了调度线程占用时间;
- 异步调度:调度中心每次任务触发时仅发送一次调度请求,该调度请求首先推送 “异步调度队列”,然后异步推送给远程执行器;
- 异步执行:执行器会将请求存入 “异步执行队列” 并且立即响应调度中心,异步运行。
- 轻量级设计:XXL-JOB 调度中心中每个 JOB 逻辑非常 “轻”,在全异步化的基础上,单个 JOB 一次运行平均耗时基本在 “10ms” 之内(基本为一次请求的网络开销);因此,可以保证使用有限的线程支撑大量的 JOB 并发运行。
得益于上述两点优化,理论上默认配置下的调度中心,单机能够支撑 5000 任务并发运行稳定运行。
实际场景中,由于调度中心与执行器网络 ping 延迟不同、DB 读写耗时不同、任务调度密集程度不同,会导致任务量上限上下波动。
如若需要支撑更多的任务量,可以通过 “调大调度线程数”、“降低调度中心与执行器 ping 延迟” 和 “提升机器配置” 几种方式优化。
均衡调度
调度中心在集群部署时会自动进行任务平均分配,触发组件每次获取与线程池数量(调度中心支持自定义调度线程池大小)相关数量的任务,避免大量任务集中在单个调度中心集群节点;
通讯模块剖析
一次完整的任务调度通讯流程
- “调度中心” 向 “执行器” 发送 http 调度请求:“执行器” 中接收请求的服务,实际上是一台内嵌 Server,默认端口 9999;
- “执行器” 执行任务逻辑;
- “执行器” http 回调 “调度中心” 调度结果:“调度中心” 中接收回调的服务,是针对执行器开放一套 API 服务。
通讯数据加密
调度中心向执行器发送的调度请求时使用 RequestModel 和 ResponseModel 两个对象封装调度请求参数和响应数据,在进行通讯之前底层会将上述两个对象对象序列化,并进行数据协议以及时间戳检验,从而达到数据加密的功能。
任务注册、任务自动发现
自 v1.5 版本之后,任务取消了 “任务执行机器” 属性,改为通过任务注册和自动发现的方式,动态获取远程执行器地址并执行。
AppName:每个执行器机器集群的唯一标示,任务注册以 “执行器” 为最小粒度进行注册;每个任务通过其绑定的执行器可感知对应的执行器机器列表。
注册表:见 xxl_job_registry 表,“执行器” 在进行任务注册时将会周期性维护一条注册记录,即机器地址和 AppName 的绑定关系;“调度中心” 从而可以动态感知每个 AppName 在线的机器列表。
执行器注册:任务注册 Beat 周期默认 30s;执行器以一倍 Beat 进行执行器注册,调度中心以一倍 Beat 进行动态任务发现;注册信息的失效时间为三倍 Beat。
执行器注册摘除:执行器销毁时,将会主动上报调度中心并摘除对应的执行器机器信息,提高心跳注册的实时性。
为保证系统 “轻量级” 并且降低学习部署成本,没有采用 Zookeeper 作为注册中心,采用 DB 方式进行任务注册发现。
任务执行结果
自 v1.6.2 之后,任务执行结果通过 IJobHandler 的返回值 ReturnT 进行判断。
当返回值符合 ReturnT#code == 200 时表示任务执行成功,否则表示任务执行失败,而且可以通过 ReturnT#msg 回调错误信息给调度中心。
从而,在任务逻辑中可以方便的控制任务执行结果。
分片广播 & 动态分片
执行器集群部署时,任务路由策略选择 “分片广播” 情况下,一次任务调度将会广播触发对应集群中所有执行器执行一次任务,同时系统自动传递分片参数;可根据分片参数开发分片任务。
“分片广播” 以执行器为维度进行分片,支持动态扩容执行器集群从而动态增加分片数量,协同进行业务处理;在进行大数据量业务操作时可显著提升任务处理能力和速度。
“分片广播” 和普通任务开发流程一致,不同之处在于可以获取分片参数,获取分片参数进行分片业务处理。
Java 语言任务获取分片参数方式:BEAN、GLUE 模式(Java)
Java// 可参考 Sample 示例执行器中的示例任务 ShardingJobHandler 了解试用 int shardIndex = XxlJobHelper.getShardIndex(); int shardTotal = XxlJobHelper.getShardTotal();脚本语言任务获取分片参数方式:GLUE 模式(Shell)、GLUE 模式(Python)、GLUE 模式(Nodejs)
Bash# 脚本任务入参固定为三个,依次为:任务传参、分片序号、分片总数。以 Shell 模式任务为例,获取分片参数代码如下 echo "分片序号 index = $2" echo "分片总数 total = $3"
分片参数属性说明:
index:当前分片序号(从 0 开始),执行器集群列表中当前执行器的序号;total:总分片数,执行器集群的总机器数量。
该特性适用场景如:
- 分片任务场景:10 个执行器的集群来处理 10w 条数据,每台机器只需要处理 1w 条数据,耗时降低 10 倍;
- 广播任务场景:广播执行器机器运行 shell 脚本、广播集群节点进行缓存更新等。
访问令牌(AccessToken)
为提升系统安全性,调度中心和执行器进行安全性校验,双方 AccessToken 匹配才允许通讯;
调度中心和执行器,可通过配置项 xxl.job.accessToken 进行 AccessToken 的设置。
调度中心和执行器,如果需要正常通讯,只有两种设置:
- 调度中心和执行器,均不设置 AccessToken,关闭安全性校验;
- 调度中心和执行器,设置了相同的 AccessToken。
故障转移 & 失败重试
一次完整任务流程包括 “调度(调度中心)+ 执行(执行器)” 两个阶段。
- “故障转移” 发生在调度阶段,在执行器集群部署时,如果某一台执行器发生故障,该策略支持自动进行 Failover 切换到一台正常的执行器机器并且完成调度请求流程;
- “失败重试” 发生在 “调度 + 执行” 两个阶段,支持通过自定义任务失败重试次数,当任务失败时将会按照预设的失败重试次数主动进行重试。
执行器灰度上线
调度中心与业务解耦,只需部署一次后常年不需要维护。但是,执行器中托管运行着业务作业,作业上线和变更需要重启执行器,尤其是 Bean 模式任务。
执行器重启可能会中断运行中的任务。但是,XXL-JOB 得益于自建执行器与自建注册中心,可以通过灰度上线的方式,避免因重启导致的任务中断的问题。
步骤如下:
- 执行器改为手动注册,下线一半机器列表(A 组),线上运行另一半机器列表(B 组);
- 等待 A 组机器任务运行结束并编译上线,执行器注册地址替换为 A 组;
- 等待 B 组机器任务运行结束并编译上线,执行器注册地址替换为 A 组 +B 组。
任务执行结果说明
系统根据以下标准判断任务执行结果,可参考之。
| Bean/Glue(Java) | Glue(Shell) 等脚本任务 | |
|---|---|---|
| 成功 | IJobHandler.SUCCESS | 0 |
| 失败 | IJobHandler.FAIL | -1(非 0 状态码) |
任务超时控制
支持设置任务超时时间,任务运行超时的情况下,将会主动中断任务。
需要注意的是,任务超时中断时与任务终止机制类似,也是通过 “interrupt” 中断任务,因此业务代码需要将 InterruptedException 外抛,否则功能不可用。
任务失败告警
默认提供邮件失败告警,可扩展短信、钉钉等方式。如果需要新增一种告警方式,只需要新增一个实现 com.xxl.job.admin.core.alarm.JobAlarm 接口的告警实现即可。可以参考默认提供邮箱告警实现 EmailJobAlarm。
避免任务重复执行
调度密集或者耗时任务可能会导致任务阻塞,集群情况下调度组件小概率情况下会重复触发。
针对上述情况,可以通过结合 “单机路由策略(如:第一台、一致性哈希)” + “阻塞策略(如:单机串行、丢弃后续调度)” 来规避,最终避免任务重复执行。
命令行任务
原生提供通用命令行任务 Handler(Bean 任务);业务方只需要提供命令行即可,命令及参数之间通过空格隔开。
如任务参数 ls la 或 pwd 将会执行命令并输出数据。
日志自动清理
XXL-JOB 日志主要包含如下两部分,均支持日志自动清理,说明如下:
- 调度中心日志表数据:可借助配置项
xxl.job.logretentiondays设置日志表数据保存天数,过期日志自动清理; - 执行器日志文件数据:可借助配置项
xxl.job.executor.logretentiondays设置日志文件数据保存天数,过期日志自动清理。
调度结果丢失处理
执行器因网络抖动回调失败或宕机等异常情况,会导致任务调度结果丢失。由于调度中心依赖执行器回调来感知调度结果,因此会导致调度日志永远处于 “运行中” 状态。
针对该问题,调度中心提供内置组件进行处理,逻辑为:调度记录停留在 “运行中” 状态超过 10min,且对应执行器心跳注册失败不在线,则将本地调度主动标记失败。