Appearance
Java 基础:集合
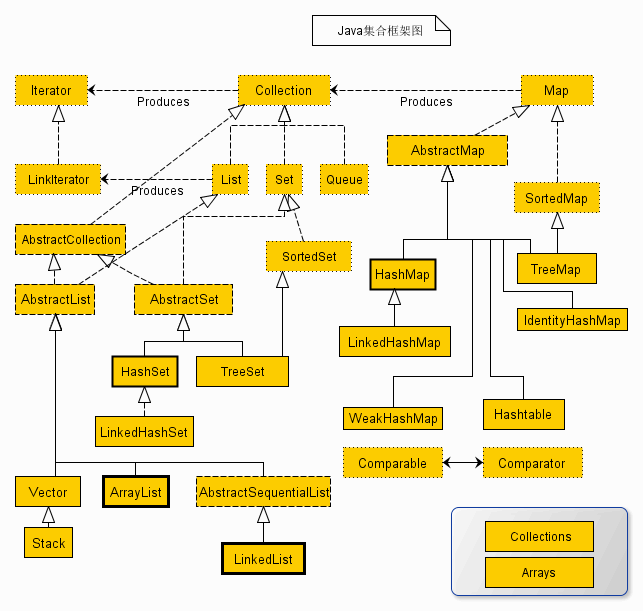
1. Java 集合框架
1.1. Iterator 接口
Java
public interface Iterator<E> {
E next();
boolean hasNext();
void remove();
default void forEachRemaining(Consumer<? super E> action);
}通过反复调用 next 方法,可以逐个访问集合中的每个元素,在到达集合末尾时,再调用 next 方法将抛出一个 NoSuchElementException。推荐的方式是,在每次调用 next 方法之前先用 hasNext 方法检测是否还有元素可以迭代。
可以使用 for each 循环迭代任何实现了 Iterable 接口的对象:
Java
public interface Iterable<E> {
Iterator<E> iterator();
}也可以不使用循环语句,而是调用 forEachRemaining 方法并提供一个 lambda 表达式。将对迭代器的每一个元素调用这个 lambda 表达式,直到再没有元素为止。
Java
iterator.forEachRemaining(element -> do something with element);Note:有些老手会注意到
Iterator接口的next和hasNext方法与Enumerator接口的nextElement和hasMoreElements方法的作用一样。Java 集合类库的设计者本来可以选择使用Enumerator接口,但是他们不喜欢这个接口累赘的方法名,于是引入了具有较短方法名的新接口。
Iterator 接口的 remove 方法将会删除上次调用 next 方法时返回的元素。如果调用 remove 之前没有调用 next,将会抛出一个 IllegalStateException 异常。并且,如果想要连续删除两个元素的话,也需要调用两次 next 方法。
Java
Iterator<String> it = c.iterator();
it.next();
it.remove(); // remove the first
it.next();
it.remove(); // remove the second1.2. ListIterator 接口
ListIterator 接口是 Iterator 的一个子接口,它支持从前后两个方向遍历集合中的元素:
Java
public interface ListIterator<E> extends Iterator<E> {
boolean hasNext();
E next();
boolean hasPrevious();
E previous();
int nextIndex();
int previousIndex();
void remove();
void set(E e);
void add(E e);
}Note 1:在
List接口中有两个名为listIterator的方法,用于返回一个ListIterator对象。List接口将在后续介绍。
Note 2:为了便于理解
next、previous、add、remove等方法对于ListIterator状态的影响,我们可以理解为它始终指向的是两个元素之间的位置。
与 Collection 的 add 方法不同,ListIterator 的 add 方法没有返回值,它假定 add 操作总会改变集合。add 方法依赖于迭代器的位置,它总是在当前位置之前添加元素。而 remove 方法依赖于迭代器的状态,remove 它总是删除上一次调用 next/previous 时返回的那个元素,不能连续调用两次 remove。
如果在某个迭代器修改集合时,另一个迭代器却在遍历这个集合,那么一定会出现混乱。例如,假设一个迭代器指向一个元素前面的位置,而另一个迭代器刚刚删除了这个元素,现在前一个迭代器就是无效的,并且不能再使用。链表迭代器设计为可以检测到这种修改。如果一个迭代器发现它的集合被另一个迭代器修改了,或是被该集合自身的某个方法修改了,就会抛出一个 ConcurrentModificationException 异常。例如,考虑下面这段代码:
Java
List<String> list = ...;
ListIterator<String> iter1 = list.listIterator();
ListIterator<String> iter2 = list.listIterator();
iter1.next();
iter1.remove();
iter2.next(); // throws ConcurrentModificationException有一种简单的方法可以检测到并发修改。集合可以跟踪更改操作(诸如添加或删除元素)的次数。每个迭代器都会为它负责的更改操作维护一个单独的更改操作数。在每个迭代器方法的开始处,迭代器会检查它自己的更改操作数是否与集合的更改操作数相等。如果不一致,就抛出一个 ConcurrentModificationException 异常。不过,对于并发修改的检测有一个奇怪的例外。链表只跟踪对列表的结构性修改,例如,添加和删除链接,set 方法不被视为结构性修改。
2. 集合框架中的接口
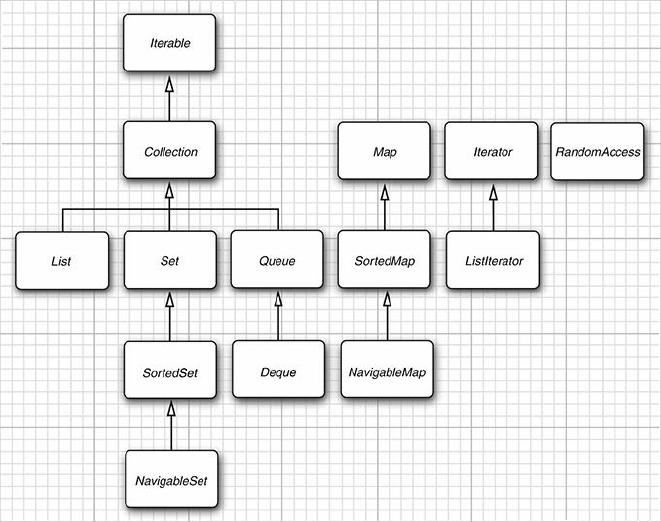
List 是一个有序集合(ordered collection)。元素会增加到容器中的特定位置。可以采用两种方式访问元素:使用迭代器访问,或者使用一个整数索引来访问。后面这种方法称为随机访问(random access),因为这样可以按任意顺序访问元素。
Set 接口等同于 Collection 接口,不过其方法的行为有更严谨的定义:
add:不允许增加重复的元素;equals:只要包含同样的元素就认为它们是相等的,不要求顺序;hashCode:要保证包含相同元素的Set会得到相同的散列码;
3. 具体集合
表 3.1 展示了 Java 类库中常见的集合(省略了线程安全集合)。除了以 Map 结尾的类之外,其他类都实现了 Collection 接口,而以 Map 结尾的类实现了 Map 接口。
| 集合类型 | 描述 |
|---|---|
ArrayList | 可以动态增长和缩减的一个索引序列 |
LinkedList | 可以在任何位置高效插入和删除的一个有序序列 |
ArrayDeque | 实现为循环数组的一个双端队列 |
HashSet | 没有重复元素的一个无序集合 |
TreeSet | 一个有序集 |
EnumSet | 一个包含枚举类型值的集 |
LinkedHashSet | 一个可以记住元素插入次序的集 |
PriorityQueue | 允许高效删除最小元素的一个集合 |
HashMap | 存储键/值关联的一个数据结构 |
TreeMap | 键有序的一个映射 |
EnumMap | 键属于枚举类型的一个映射 |
LinkedHashMap | 可以记住键/值项添加次序的一个映射 |
WeakHashMap | 值不会在别处使用时就可以被垃圾回收的一个映射 |
IdentityHashMap | 用 == 而不是用 equals 比较键的一个映射 |
3.1. 链表
在 List 接口中我们可以看到它定义了许多用于随机访问的方法:
Java
void add(int index, E element);
E remove(int index);
E get(int index);
E set(int index, E element);
ListIterator<E> listIterator();
ListIterator<E> listIterator(int index);由数组支持的有序集合(如 ArrayList)可以快速地随机访问,因此适合使用 List 方法并提供一个整型数索引来访问。而链表(如 LinkedList)虽然也是有序的,但是随机访问很慢,所以最好使用迭代器来遍历。
为了避免对链表完成随机访问操作,Java 1.4 引入了一个标记接口 RandomAccess。这个接口不包含任何方法,不过可以用它来测试一个特定的集合是否支持高效的随机访问:
Java
if (c instanceof RandomAccess) {
use random access algorithm
} else {
use sequential access algorithm
}listIterator 方法返回一个 ListIterator 对象(关于 ListIterator 接口的介绍详见这里)。listIterator(int index) 方法返回的迭代器指向索引(index 参数)元素之前的位置。也就是说在获得迭代器后,立即调用它的 next() 方法与直接调用 list.get(n) 将获得同一个元素。
Note 1:在 Java 中,所有链表实际上都是双向链接的(doubly linked)—— 即每个链接还存放着其前驱的引用。
Note 2:如果你经常使用
LinkedList的get方法,这说明你可能使用了错误的数据结构。虽然通过索引来访问LinkedList效率较为低下,但它还是对get方法做了一个小的优化:如果索引大于等于size() / 2,就从列表尾端开始搜索元素。
3.2. 数组列表
集合类库提供了一种大家熟悉的 ArrayList 类,这个类也实现了 List 接口,并且它非常适用于 get、set 等操作的随机访问。ArrayList 封装了一个动态再分配的对象数组。
Note:对于一个老 Java 程序员来说,在需要动态数组时,可能会使用
Vector类。为什么要用ArrayList而不是Vector呢?原因很简单:Vector类的所有方法都是同步的。可以安全地从两个线程访问一个Vector对象。但是,如果只从一个线程访问Vector(这种情况更为常见),代码就会在同步操作上白白浪费大量的时间。而与之不同,ArrayList方法不是同步的,因此,建议在不需要同步时使用ArrayList,而不要使用Vector。
3.3. 散列集
在 Java 中,散列表用链表数组实现。每个列表被称为桶(bucket,参看图 3.1)。要想查找表中对象的位置,就要先计算它的散列码,然后与桶的总数取余,所得到的结果就是保存这个元素的桶的索引。例如,如果某个对象的散列码为 76268,并且有 128 个桶,那么这个对象应该保存在第 108 号桶中(因为 76268 % 128 的余数是 108)。或许很幸运,在这个桶中没有其他元素,此时将元素直接插入到桶中就可以了。当然,有时候会遇到桶已经被填充的情况。这种现象被称为散列冲突(hash collision)。这时,需要将新对象与桶中的所有对象进行比较,查看这个对象是否已经存在。如果散列码合理地随机分布,桶的数目也足够大,需要比较的次数就会很少。
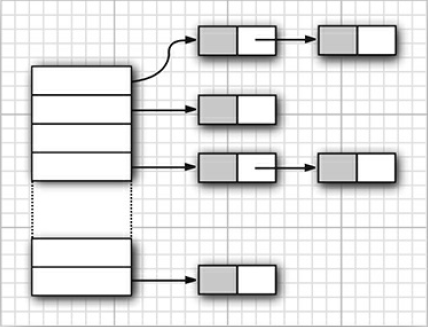
Tip:在 Java 8 中,桶满时会从链表变为平衡二又树。如果选择的散列函数不好,会产生很多冲突,或者如果有恶意代码试图在散列表中填充多个有相同散列码的值,这样改为平衡二叉树能提高性能。
通常,将桶数设置为预计元素个数的 75% ~ 150%。有些研究人员认为:最好将桶数设置为一个素数,以防止键的聚集。不过,对此并没有确凿的证据。标准类库使用的桶数是 2 的幂,默认值为 16(为表大小提供的任何值都将自动地转换为 2 的下一个幂值)。
如果散列表太满,就需要再散列(rehashed)。如果要对散列表再散列,就需要创建一个桶数更多的表,并将所有元素插入到这个新表中,然后丢弃原来的表。装填因子(load factor)可以确定何时对散列表进行再散列。例如,如果装填因子为 0.75(默认值),说明表中已经填满了 75% 以上,就会自动再散列,新表的桶数是原来的两倍。对于大多数应用程序来说,装填因子为 0.75 是合理的。
Java 集合类库提供了一个 HashSet 类,它实现了基于散列表的集。可以用 add 方法添加元素,contains 方法已经被重新定义,用来快速查找某个元素是否已经在集中。它只查看一个桶中的元素,而不必查看集合中的所有元素。散列集迭代器将依次访问所有的桶。由于散列将元素分散在表中,所以会以一种看起来随机的顺序访问元素。只有不关心集合中元素的顺序时才应该使用 HashSet。
Warning:
HashSet中元素的散列码应该是不可变的,否则当元素的散列码发生变化,便丢失了对于原始键对象的引用,这有时被称为集合中的内存泄露。
3.4. 树集
TreeSet 类与散列集十分类似,不过,它比散列集有所改进。树集是一个有序集合(sorted collection)。可以以任意顺序将元素插入到集合中。在对集合进行遍历时,值将自动地按照排序后的顺序呈现。正如 TreeSet 类名所示,排序是用一个树数据结构完成的,当前实现使用的是红黑树(red-black tree)。
Tip:树集中的元素必须实现
Comparable接口,或者构造集时必须提供一个Comparator。
将一个元素添加到树中会比添加到散列表中稍微慢一些(对比,见表 3.2),不过,与检查数组或链表中的重复元素相比,使用树还是会快很多。如果树中包含 n 个元素,查找新元素的正确位置平均需要 log2n 次比较。例如,如果一棵树包含了 1000 个元素,添加一个新元素大约需要比较 10 次。
| 文档 | 单词总数 | 不同单词的个数 | HashSet | TreeSet |
|---|---|---|---|---|
| Alice in Wonderland | 28,195 | 5,909 | 5 秒 | 7 秒 |
| The Count of Monte Cristo | 466,300 | 37,545 | 75 秒 | 98 秒 |
回头看表 3.2,你可能很想知道是否应该总是用树集而不是散列集。毕竟,添加一个元素所花费的时间看上去并不很长,而且元素是自动排序的。到底应该怎样做取决于所要收集的数据。如果不需要数据是有序的,就没有必要付出排序的开销。更重要的是,对于某些数据来说,对其进行排序要比给出一个散列函数更加困难。散列函数只需要将对象适当地打乱存放,而比较函数必须精确地区分各个对象。
Note:从 Java 6 起,
TreeSet类实现了NavigableSet接口,这个接口增加了几个查找元素以及反向遍历的便利方法。
3.5. 队列与双端队列
队列允许你高效地在尾部添加元素,并在头部删除元素。双端队列(即 deque)允许在头部和尾部都高效地添加或删除元素。不支持在队列中间添加元素。Java 6 中引入了 Deque 接口,ArrayDeque 和 LinkedList 类实现了这个接口。这两个类都可以提供双端队列,其大小可以根据需要扩展。在后续还将会看到限定队列和限定双端队列。
3.6. 优先队列
优先队列(priority queue)中的元素可以按照任意的顺序插入,但会按照有序的顺序进行检索。也就是说,无论何时调用 remove 方法,总会获得当前优先队列中最小的元素。不过,优先队列并没有对所有元素进行排序。如果迭代处理这些元素,并不需要对它们进行排序。优先队列使用了一个精巧且高效的数据结构,称为堆(heap)。堆是一个可以自组织的二叉树,其添加(add)和删除(remove)操作可以让最小的元素移动到根,而不必花费时间对元素进行排序。
与 TreeSet 一样,优先队列既可以保存实现了 Comparable 接口的类对象,也可以保存构造器中提供的 Comparator 对象。
4. 映射
4.1. 基本映射操作
Java 类库为映射提供了两个通用的实现:HashMap 和 TreeMap 这两个类都实现了 Map 接口。应该选择散列映射还是树映射呢?与集一样,散列稍微快一些,如果不需要按照有序的顺序访问键,最好选择散列映射。
如果映射中没有存储与给定键对应的信息,get 将返回 null。或者可以使用 getOrDefault 方法,当键在映射中不存在时,返回一个默认对象。键必须是唯一的。不能对同一个键存放两个值。如果对同一个键调用两次 put 方法,第二个值就会取代第一个值。实际上,put 将返回与这个键参数关联的上一个值。
通常情况下,我们可以先得到与一个键关联的原值,完成更新,再放回更新后的值。不过,当键第一次出现时,在这种情况下,get 会返回 null,因此稍有不慎就容易引发 NullPointerException 异常。一种简单的处理方法是使用 getOrDefault 方法:
Java
counts.put(word, counts.getOrDefault(word, 0) + 1);另外一种方法是首先调用 putIfAbsent 方法,只有当键原先不存在(或者映射到 null)时才会放入一个值。
Java
counts.putIfAbsent(word, 0);
counts.put(word, counts.get(word) + 1); // now we know that get will succeed不过更好的方式是使用 merge 方法:
Java
counts.merge(word, 1, Integer::sum);当 word 键原先不存在时,则将 word 与 1 关联,否则使用 Integer::sum 函数将原值与 1 相加,再用返回值进行更新。
4.2. 映射视图
Java 中不认为映射本身是一个集合(所以你会发现 Map 接口并没有实现 Iterable 接口,因此我们不能直接使用 for each 语句对其进行迭代)。不过,可以得到映射的视图(view)—— 这是实现了 Collection 接口或某个子接口的对象。有 3 种视图:键集、值集合(不是一个集)以及键值对集。键和键值对可以构成一个集,是因为映射中一个键只能有一个副本。方法如下:
Java
Set<K> keySet()
Collection<V> values()
Set<Map.Entry<K, V>> entrySet()Note:需要说明的是,
keySet不是HashSet或TreeSet,而是实现了Set接口的另外某个类的对象。
如果想同时查看键和值,可以通过枚举映射条目来避免查找值:
Java
for (Map.Entry<String, Employee> entry : staff.entrySet()) {
String k = entry.getKey();
Employee v = entry.getValue();
// do something with k, v
}或者更容易的方法是使用 forEach 方法:
Java
map.forEach((k, v) -> {
// do something with k, v
});Warning:如果在键集视图上调用迭代器的
remove方法,实际上会从映射中删除这个键和与它关联的值。不过,不能向键集视图中添加元素,如果试图调用add方法,它会抛出一个UnsupportedOperationException。映射条目集视图也有同样的限制,尽管理论上增加一个新的键/值对好像有意义。
4.3. 弱散列映射
WeakHashMap 使用弱引用(WeakReference)保存键。正常情况下,如果垃圾回收器发现某个特定的对象己经没有他人引用了,就将其回收。然而,如果某个对象只能由 WeakReference 引用,垃圾回收器也会将其回收,但会将引用这个对象的弱引用放入一个队列。WeakHashMap 将周期性地检查队列,以便找出新添加的弱引用。一个弱引用进入队列意味着这个键不再被他人使用,并且已经回收。于是,WeakHashMap 将删除相关联的映射条目。
4.4. 链接散列集与映射
LinkedHashSet 和 LinkedHashMap 类会记住插入元素项的顺序。这样就可以避免散列表中的项看起来顺序是随机的。在表中插入元素时,就会并入到双向链表中。
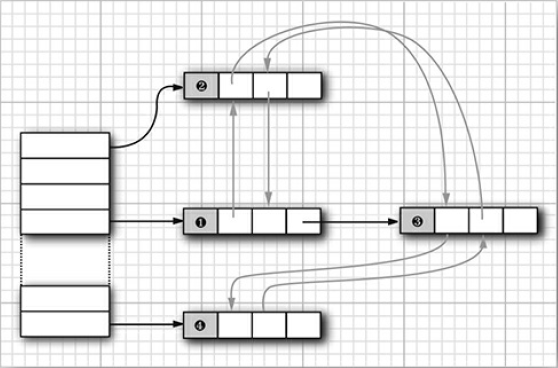
链接散列映射可以使用访问顺序而不是插入顺序来迭代处理映射条目。每次调用 get 或 put 时,受到影响的项将从当前的位置删除,并放到项链表的尾部(只影响项在链表中的位置,而散列表的桶不会受影响。映射条目总是在键散列码对应的桶中)。要构造这样一个散列映射,需要调用:
Java
LinkedHashMap<K, V>(initialCapacity, loadFactor, true)访问顺序对于实现缓存的 “最近最少使用” 原则十分重要。例如,你可能希望将访问频率高的元素放在内存中,而访问频率低的元素从数据库中读取。当在表中找不到元素项而且表已经相当满时,可以得到表的一个迭代器,并删除它枚举的前几个元素。这些项是近期最少使用的几个元素。甚至可以让这一过程自动化,构造 LinkedHashMap 的一个子类,然后覆盖下面这个方法:
Java
protected boolean removeEldestEntry(Map.Entry<K, V> eldest)每当你的方法返回 true 时,添加一个新映射条目就会导致删除 eldest 项。例如,下面的缓存最多可以存放 100 个元素:
Java
var cache = new LinkedHashMap<K, V>(128, 0.75F, true) {
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > 100;
}
};或者,还可以考虑 eldest 元素,来决定是否将它删除。例如,可以检查与这一项一起存储的时间戳。
4.5. 枚举集与映射
EnumSet 是一个枚举类型元素集的高效实现。由于枚举类型只有有限个实例,所以 EnumSet 内部用位序列实现。如果对应的值在集中,则相应的位被置为 1。EnumSet 类没有公共的构造器,要使用静态工厂方法构造这个集:
Java
enum Weekday { MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY, SATURDAY, SUNDAY };
EnumSet<Weekday> always = EnumSet.allOf(Weekday.class);
EnumSet<Weekday> never = EnumSet.noneOf(Weekday.class);
EnumSet<Weekday> workday = EnumSet.range(Weekday.MONDAY, Weekday.FRIDAY);
EnumSet<Weekday> mwf = EnumSet.of(Weekday.MONDAY, Weekday.WEDNESDAY, Weekday.FRIDAY);可以使用 Set 接口的常用方法来修改 EnumSet。
EnumMap 是一个键类型为枚举类型的映射。它可以直接且高效地实现为一个值数组。需要在构造器中指定键类型:
Java
var personInCharge = new EnumMap<Weekday, Employee>(Weekday.class);4.6. 标识散列映射
类 IdentityHashMap 有特殊的用途。在这个类中,键的散列值不是用 hashCode 函数计算的,而是用 System.identityHashCode 方法计算的。这是 Object.hashCode 根据对象的内存地址计算散列码时所使用的方法。而且,在对两个对象进行比较时,IdentityHashMap 类使用 ==,而不使用 equals。
也就是说,不同的键对象即使内容相同,也被视为不同的对象。在实现对象遍历算法(如对象串行化)时,这个类非常有用,可以用来跟踪哪些对象已经遍历过。
5. 视图与包装器
5.1. 小集合
Java 9 引入了一些静态方法,可以生成给定元素的集或列表,以及给定键/值对的映射。例如:
Java
List<String> names = List.of("Peter", "Paul", "Mary");
Set<Integer> numbers = Set.of(2, 3, 5);
Map<String, Integer> scores = Map.of("Peter", 2, "Paul", 3, "Mary", 5);Java
import static java.util.Map.*;
// ...
Map<String, Integer> scores = ofEntries(entry("Peter", 2), entry("Paul", 3), entry("Mary", 5));Tip:其中元素、键或值不能为
null。这些集合对象是不可修改的,如果试图改变它们的内容,会导致一个UnsupportedOperationException异常。之前有一个静态方法Arrays.asList, 它会返回一个可更改但是大小不可变的列表。也就是说,在这个列表上可以调用set,但是不能使用add或remove。另外还有遗留的方法Collections.emptySet和Collections.singleton。
Note:Java 没有
Pair类,有些程序员会使用Map.Entry(实现该接口的匿名类)作为对组(pair),但这种做法并不好。在 Java 9 之前,这会很麻烦,你必须使用new AbstractMap.SimpleImmutableEntry<>(first, second)构造对象。不过现在可以调用Map.entry(first, second),该方法返回一个实现了Map.Entry接口的不可变类对象。
5.2. 子范围
可以为很多集合建立子范围(subrange)视图。例如,假设有一个列表 staff,想从中取出第 10 个 ~ 第 19 个元素。可以使用 subList 方法来获得这个列表子范围的视图。
Java
List<Employee> group2 = staff.subList(10, 20);可以对子范围应用任何操作,而且操作会自动反映到整个列表。例如,可以删除整个子范围:
Java
group2.clear(); // staff reduction对于有序集和映射,可以使用排序顺序而不是元素位置建立子范围:
Java
SortedSet<E> subSet(E from, E to)
SortedSet<E> headSet(E to)
SortedSet<E> tailSet(E from)
SortedMap<K, V> subMap(K from, K to)
SortedMap<K, V> headMap(K to)
SortedMap<K, V> tailMap(K from)Java 6 引入的 NavigableSet 接口允许更多地控制这些子范围操作。可以指定是否包括边界:
Java
NavigableSet<E> subSet(E from, boolean fromInclusive, E to, boolean toInclusive)
NavigableSet<E> headSet(E to, boolean toInclusive)
NavigableSet<E> tailSet(E from, boolean fromInclusive)5.3. 不可修改的视图
Collections 类还有几个方法,可以生成集合的不可修改视图(unmodifiable view):
Text
Collections.unmodifiableCollection
Collections.unmodifiableList
Collections.unmodifiableSet
Collections.unmodifiableSortedSet
Collections.unmodifiableNavigableSet
Collections.unmodifiableMap
Collections.unmodifiableSortedMap
Collections.unmodifiableNavigableMap例如,假设想要让你的某些代码允许查看但不能修改一个集合的内容:
Java
var staff = new LinkedList<String>();
// ...
lookAt(Collections.unmodifiableList(staff));Warning
unmodifiableCollection方法(以及synchronizedCollection和checkedCollection方法)将返回一个集合,它的equals方法不调用底层集合的equals方法。实际上,它继承了Object类的equals方法,这个方法只是检测两个对象是否是同一个对象。如果将集或列表转换成集合,就再也无法检测其内容是否相同了。视图就采用这种工作方式,因为相等性检测在层次结构的这一层上没有明确定义。视图将以同样的方式处理hashCode方法。不过,
unmodifiableSet和unmodifiableList方法会使用底层集合的equals方法和hashCode方法。
5.4. 同步视图
类库的设计者使用视图机制来确保常规集合是线程安全的,而没有实现线程安全的集合类。例如,Collections 类的静态 synchronizedMap 方法可以将任何一个映射转换成有同步访问方法的 Map:
Java
var map = Collections.synchronizedMap(new HashMap<String, Employee>());5.5. 检查型视图
“检查型” 视图用来对泛型类型可能出现的问题提供调试支持。例如,将错误类型的元素混入泛型集合中的情况极有可能发生:
Java
var strings = new ArrayList<String>();
ArrayList rawList = strings; // warning only, not an error,
// for compatibility with legacy code
rawList.add(new Date()); // now strings contains a Date object!这个错误的 add 命令在运行时检测不到,只有当另一部分代码调用 get 方法,并将结果强制转换为 String 时,才会出现一个类强制转换异常。检查型视图可以探测这类问题:
Java
List<String> safeStrings = Collections.checkedList(strings, String.class);这个视图的 add 方法将检查插入的对象是否属于给定的类。如果不属于给定的类,就立即抛出一个 ClassCastException。这样做的好处是会在正确的位置报告错误。
Warning:检查型视图受限于虚拟机可以完成的运行时检查。例如,对于
ArrayList<Pair<String>>,由于虚拟机有一个 “原始”Pair类,所以无法阻止插入Pair<Date>。
6. 算法
6.1. 为什么使用泛型算法
泛型集合接口有一个很大的优点,即算法只需要实现一次。例如,要计算集合中最大元素的简单算法。
对于数组我们可能会这样写:
Java
if (a.length == 0) throw new NoSuchElementException();
T largest = a[0];
for (int i = 1; i < a.length; i++)
if (largest.compareTo(a[i]) < 0)
largest = a[i];对于数组列表可能会这样写:
Java
if (v.size() == 0) throw new NoSuchElementException();
T largest = v.get(0);
for (int i = 1; i < v.size(); i++)
if (largest.compareTo(v.get(i)) < 0)
largest = v.get(i);对于链表我们可能又会这样写:
Java
if (l.isEmpty()) throw new NoSuchElementException();
Iterator<T> iter = l.iterator();
T largest = iter.next();
while (iter.hasNext()) {
T next = iter.next();
if (largest.compareTo(next) < 0)
largest = next;
}在计算链表中最大元素的过程中已经看到,这项任务并不需要随机访问。可以直接迭代处理元素来得出最大元素。因此,可以将 max 方法实现为能够接收任何实现了 Collection 接口的对象:
Java
public static <T extends Comparable> T max(Collection<T> c) {
if (c.isEmpty()) throw new NoSuchElementException();
Iterator<T> iter = c.iterator();
T largest = iter.next();
while (iter.hasNext()) {
T next = iter.next();
if (largest.compareTo(next) < 0)
largest = next;
}
return largest;
}6.2. 排序与混排
Collections 类中的 sort 方法可以对实现了 List 接口的集合进行排序,这个方法假定列表元素实现了 Comparable 接口。如果想采用其他方式对列表进行排序,可以使用 List 接口的 sort 方法并传入一个 Comparator 对象:
Java
var staff = new LinkedList<String>();
// fill collection
Collections.sort(staff);
// or
staff.sort(Comparator.comparingDouble(Employee::getSalary));如果想按照降序对列表进行排序,可以使用静态的 Collections.reverseOrder() 方法,或 Comparator 实例对象的 reversed 方法:
Java
staff.sort(Comparator.reverseOrder()) // equivalent to the Collections.reverseOrder() method
staff.sort(Comparator.comparingDouble(Employee::getSalary).reversed())人们可能会对 sort 方法如何排序感到好奇。通常,在查看有关算法书籍中的排序算法时,会发觉介绍的都是有关数组的排序算法,而且使用的是随机访问方式。但是,链表的随机访问效率很低。实际上,可以使用一种归并排序对链表高效地排序。不过,Java 程序设计语言并不是这样做的。它只是将所有元素转入一个数组,对数组进行排序,然后,再将排序后的序列复制回列表。
集合类库中使用的排序算法比快速排序要慢一些,快速排序(QuickSort)是通用排序算法的传统选择。但是,归并排序有一个主要的优点:归并排序是稳定的,也就是说,它不会改变相等元素的顺序。
Collections 类有一个算法 shuffle,其功能与排序刚好相反,它会随机地混排列表中元素的顺序。
6.3. 二分查找
Collections 类的 binarySearch 方法实现了二分查找算法。注意,集合必须是有序的,否则算法会返回错误的答案。要想查找某个元素,必须提供集合(这个集合要实现 List 接口)以及要查找的元素。如果集合没有采用 Comparable 接口的 compareTo 方法进行排序,那么还要提供一个比较器对象。
binarySearch 方法如果返回负值,则表示没有匹配的元素。不过,还是可以利用这个返回值来计算应该将元素插入到集合的哪个位置,以保持集合的有序性。插入的位置是:
Java
insertionPoint = -i - 1; // i must be less than 0只有采用随机访问,二分查找才有意义。如果必须利用迭代方式查找链表的一半元素来找到中间元素,二分查找就完全失去了优势。因此,如果为 binarySearch 方法提供一个链表,它将自动地退化为线性查找。
6.4. 简单算法
下面是 java.util.Collections 中常用的一些简单方法:
Java
static <T extends Comparable<? super T>> T min(Collection<T> elements)
static <T extends Comparable<? super T>> T max(Collection<T> elements)
static <T> min(Collection<T> elements, Comparator<? super T> c)
static <T> max(Collection<T> elements, Comparator<? super T> c)
static <T> void copy(List<? super T> to, List<T> from)
static <T> void fill(List<? super T> l, T value)
static <T> boolean addAll(Collection<? super T> c, T... values)
static <T> boolean replaceAll(List<T> l, T oldValue, T newValue)
static int indexOfSubList(List<?> l, List<?> s)
static int lastIndexOfSubList(List<?> l, List<?> s)
static void swap(List<?> l, int i, int j)
static void reverse(List<?> l)
static void rotate(List<?> l, int d)
static int frequency(Collection<?> c, Object o)
boolean disjoint(Collection<?> c1, Collection<?> c2)java.util.Collection<T>:
Java
default boolean removeIf(Predicate<? super E> filter)java.util.List<E>:
Java
default void replaceAll(UnaryOperator<E> op)6.5. 批操作
从 coll1 中删除 coll2 中出现的所有元素(差集):
Java
coll1.removeAll(coll2);从 coll1 中删除所有未在 coll2 中出现的元素(交集):
Java
coll1.retainAll(coll2);
// or
new HashSet<String>(firstSet).retainAll(secondSet);或者在映射当中,我们还可以利用视图,批量删除记录:
Java
Map<String, Employee> staffMap = ...;
Set<String> terminatedIDs = ...;
staffMap.keySet().removeAll(terminatedIDs);再或者利用子范围,把一个列表的前 10 个元素增加到另一个容器:
Java
relocated.addAll(staff.subList(0, 10));这个子范围还可以完成更改操作:
Java
staff.subList(0, 10).clear();6.6. 集合与数组的转换
如果需要把一个数组转换为集合,可以使用 List.of 包装器:
Java
String[] values = ...;
var staff = new HashSet<>(List.of(values));从集合得到数组会稍微麻烦一些,如果直接使用无参的 toArray() 方法,只会得到一个 Object[],而且不能对其使用强制转换:
Java
String[] values = (String[]) staff.toArray(); // ERROR可以用 toArray 方法的一个变体,提供一个指定类型而且长度为 0 的数组:
Java
String[] values = staff.toArray(new String[0]);如果愿意,可以构造一个大小正确的数组,在这种情况下,不会创建新数组:
Java
staff.toArray(new String[staff.size()]);7. 遗留的集合
7.1. Hashtable 以及 Vector 类
经典的 Hashtable 类与 HashMap 类的作用一样,实际上,接口也基本相同。与 Vector 类的方法一样,Hashtable 方法也是同步的。如果对与遗留代码的兼容性没有任何要求,就应该使用 HashMap。如果需要并发访问,则要使用 ConcurrentHashMap。
7.2. Enumeration 接口
遗留的集合使用 Enumeration 接口遍历元素序列。Enumeration 接口有两个方法,即 hasMoreElements 和 nextElement。这两个方法完全类似于 Iterator 接口的 hasNext 方法和 next 方法。
如果发现遗留的类实现了这个接口,可以使用 Collections.list 将元素收集到一个 ArrayList 中。例如,LogManager 类只是将登录者的名字提供为一个 Enumeration。可以如下得到所有登录者的名字:
Java
ArrayList<String> loggerNames = Collections.list(LogManager.getLoggerNames());或者,在 Java 9 中,可以把一个枚举转换为一个迭代器:
Java
LogManager.getLoggerNames().asIterator().forEachRemaining(n -> { ... });有时还会遇到遗留的方法希望得到枚举参数。静态方法 Collections.enumeration 将产生一个枚举对象,枚举集合中的元素。例如:
Java
List<InputStream> streams = ...;
var in = new SequenceInputStream(Collections.enumeration(streams));
// the SequenceInputStream constructor expects an enumeration7.3. Properties 类
属性映射(property map)是一个特殊类型的映射结构。它有下面 3 个特性:
- 键与值都是字符串;
- 这个映射可以很容易地保存到文件以及从文件加载;
- 有一个二级表存放默认值;
实现属性映射的 Java 平台类名为 Properties。属性映射对于指定程序的配置选项很有用。可以使用 store 方法将属性映射列表保存到一个文件中。在这里,我们将属性映射保存在文件 program.properties 中。第二个参数是包含在这个文件中的注释:
Java
var settings = new Properties();
settings.setProperty("width", "600.0");
settings.setProperty("filename", "/home/cay/books/cj11/code/v1ch11/raven.html");
var out = new FileOutputStream("program.properties");
settings.store(out, "Program Properties");Properties
#Program Properties
#Sun Dec 31 12:54:19 PST 2017
top=227.0
left=1286.0
width=423.0
height=547.0
filename=/home/cay/books/cj11/code/v1ch11/raven.html要从文件加载属性,可以使用以下调用:
Java
var in = new FileInputStream("program.properties");
settings.load(in);Note:在 Java 9 之前,属性文件使用 7 位 ASCII 编码,如今则使用 UTF-8。
System.getProperties 方法会生成 Properties 对象描述系统信息。例如,主目录包含键 user.home。可以用 getProperties 方法读取这个信息,它将键作为一个字符串返回:
Java
String userDir = System.getProperty("user.home");Note:出于历史方面的原因,
Properties类实现了Map<Object, Object>。因此,可以使用Map接口的get和put方法。不过,get方法返回类型为Object,而put方法允许插入任意的对象。所以最好坚持使用处理字符串而不是对象的getProperty和setProperty方法。
要得到虚拟机的 Java 版本,可以查找 java.version 属性。你会得到一个诸如 9.0.1(或者对应 Java 8 为 1.8.0)的字符串。
Properties 类有两种提供默认值的机制。第一种方法是,只要查找一个字符串的值,可以指定一个默认值,这样当键不存在时就会自动使用这个默认值。
Java
// If there is a "filename" property in the property map,
// filename is set to that string. Otherwise, filename is
// set to the empty string.
String filename = settings.getProperty("filename", "");第二种方法是,可以把所有默认值都放在一个二级属性映射中,并在主属性映射的构造器中提供这个二级映射:
Java
var defaultSettings = new Properties();
defaultSettings.setProperty("width", "600");
defaultSettings.setProperty("height", "400");
defaultSettings.setProperty("filename", "");
// ...
var settings = new Properties(defaultSettings);Properties 是没有层次结构的简单表格,通常会用类似 window.main.color、window.main.title 等引入一个假想的层次结构。Properties 类没有方法来帮助组织这样一个层次结构。如果要存储复杂的配置信息,就应该改为使用 Preferences 类。
7.4. 栈
从 1.0 版开始,标准类库中就包含了 Stack 类,其中有大家熟悉的 push 方法和 pop 方法。但是,Stack 类扩展了 Vector 类,从理论角度看,Vector 类并不太令人满意,你甚至可以使用并非栈操作的 insert 和 remove 方法在任何地方插入和删除值,而不只是在栈顶。
7.5. 位集
Java 平台的 BitSet 类用于存储一个位序列(它不是数学上的集,如果称为位向量或位数组可能更为合适)。如果需要高效地存储位序列(例如,标志),就可以使用位集。由于位集将位包装在字节里,所以使用位集要比使用 Boolean 对象的 ArrayList 高效得多。
BitSet 类提供了一个便于读取、设置或重置各个位的接口。使用这个接口可以避免掩码和其他调整位的操作,如果将位存储在 int 或 long 变量中就必须做这些烦琐的操作。
Java
bucketOfBits.get(i) // returns true if the i-th bit is on
bucketOfBits.set(i) // turns the i-th bit on
bucketOfBits.clear(i) // turns the i-th bit off8. 线程安全的集合
8.1. 阻塞队列
BlockingQueue<E> 接口要求其实现类是线程安全的。
| 方法 | 正常动作 | 特殊情况下的动作 |
|---|---|---|
add | 添加一个元素 | 如果队列满,则抛出 IllegalStateException 异常 |
remove | 移除并返回队头元素 | 如果队列空,则抛出 NoSuchElementException 异常 |
element | 返回队头元素 | 如果队列空,则抛出 NoSuchElementException 异常 |
offer | 添加一个元素并返回 true | 如果队列满,则返回 false |
poll | 移除并返回队头元素 | 如果队列空,则返回 null |
peek | 返回队头元素 | 如果队列空,则返回 null |
put | 添加一个元素 | 如果队列满,则阻塞 |
take | 移除并返回队头元素 | 如果队列空,则阻塞 |
Warning:
poll和peek方法返回null来指示失败。因此,向这些队列中插入null值是非法的。
还有带有超时时间的 offer 方法和 poll 方法:
Java
boolean success = q.offer(x, 100, TimeUnit.MILLISECONDS);
Object head = q.poll(100, TimeUnit.MILLISECONDS);put、take 方法与不带超时参数的 offer、poll 方法等效。
java.util.concurrent 包提供了阻塞队列的几个变体:
LinkedBlockingQueue默认情况下,
LinkedBlockingQueue的容量没有上界,但是,也可以选择指定一个最大容量。LinkedBlockingQueue是一个双端队列。ArrayBlockingQueueArrayBlockingQueue在构造时需要指定容量,并且有一个可选的参数来指定是否需要公平性若设置了公平参数,那么等待了最长时间的线程会优先得到处理。通常,公平性会降低性能,只有在确实非常需要时才使用公平参数。PriorityBlockingQueuePriorityBlockingQueue是一个优先队列,而不是先进先出队列。元素按照它们的优先级顺序移除。这个队列没有容量上限,但是,如果队列是空的,获取元素的操作会阻塞。有关优先队列的详细内容参看这里。DelayQueueDelayQueue包含实现了Delayed接口的对象:Javainterface Delayed extends Comparable<Delayed> { long getDelay(TimeUnit unit); }getDelay方法返回对象的剩余延迟。负值表示延迟已经结束。元素只有在延迟结束的情况下才能从DelayQueue移除。还需要实现compareTo方法。DelayQueue使用该方法对元素排序。LinkedTransferQueueJava 7 增加了一个
TransferQueue接口(LinkedTransferQueue类实现了这个接口),允许生产者线程等待,直到消费者准备就绪可以接收元素。如果生产者调用:Javaq.transfer(item);这个调用会阻塞,直到另一个线程将元素
item删除。
8.2. 高效的映射、集和队列
java.util.concurrent 包提供了映射、有序集和队列的高效实现:ConcurrentHashMap、ConcurrentSkipListMap、ConcurrentSkipListSet 和 ConcurrentLinkedQueue。这些集合使用复杂的算法,通过允许并发地访问数据结构的不同部分尽可能减少竞争。
与大多数集合不同,这些类的 size 方法不一定在常量时间内完成操作。确定这些集合的当前大小通常需要遍历。
Note:有些应用使用庞大的并发散列映射,这些映射太过庞大,以至于无法用
size方法得到它的大小(因为这个方法只能返回int)。如果一个映射包含超过 20 亿个条目,则应该使用mappingCount方法,它返回long。
集合返回弱一致性(weakly consistent)的迭代器。这意味着迭代器不一定能反映出它们构造之后的所有更改,但是,它们不会将同一个值返回两次,也不会抛出 ConcurrentModificationException 异常。
并发散列映射可以高效地支持大量阅读器和一定数量的书写器。默认情况下认为可以有至多 16 个同时运行的书写器线程。当然可以有更多的书写器线程,但是,同一时间如果多于 16 个,其他线程将暂时阻塞。可以在构造器中指定更大数目,不过,通常都没有这种必要。
Note:在较新的 Java 版本中,并发散列映射将桶组织为树,而不是列表,键类型实现
Comparable,从而可以保证性能为。
8.3. 映射条目的原子更新
ConcurrentHashMap 原来的版本只有为数不多的方法可以实现原子更新,这使得编程有些麻烦。假如,我们想统计单词出现的频率。一种方法是使用 replace 方法,它会以原子方式用一个新值替换原值。通常这样的代码会包含一个循环:
Java
do {
oldValue = map.get(word);
newValue = oldValue == null ? 1 : oldValue + 1;
} while (!map.replace(word, oldValue, newValue));或者,改用 ConcurrentHashMap<String, AtomicLong> 类型:
Java
map.putIfAbsent(word, new AtomicLong());
map.get(word).incrementAndGet();这样每次都会构造一个非必要的 AtomicLong 对象。
如今,Java API 提供了一些新方法,可以更方便地完成原子更新。调用 compute 方法(类似的还有 merge 方法)时可以提供一个键和一个计算新值的函数。这个函数接收键和相关联的值(如果没有值,则为 null),它会计算新值。例如,可以如下更新一个整数计数器的映射:
Java
map.compute(word, (k, v) -> v == null ? 1 : v + 1);Warning:
ConcurrentHashMap中不允许有null值。很多方法都使用null值来指示映射中某个给定的键不存在。
Tip:如果传入
compute或merge的函数返回null,将从映射中删除现有的条目。
对于 ConcurrentHashMap<String, LongAdder> 类型,我们可以使用 computeIfAbsent(类似的还有 computeIfPresent 方法):
Java
map.computeIfAbsent(word, k -> new LongAdder()).increment();这与之前看到的 putIfAbsent 调用几乎是一样的,不过 LongAdder 构造器只在确实需要一个新的计数器时才会调用。
8.4. 对并发散列映射的批操作
Java API 为并发散列映射提供了批操作,即使有其他线程在处理映射,这些操作也能安全地执行。批操作会遍历映射,处理遍历过程中找到的元素。这里不会冻结映射的当前快照。除非你恰好知道批操作运行时映射不会被修改,否则就要把结果看作是映射状态的一个近似。
3 种不同的操作:
search(搜索):为每个键或值应用一个函数,直到函数生成一个非null的结果。然后搜索终止,返回这个函数的结果;reduce(归约):组合所有键或值,这里要使用所提供的一个累加函数;forEach:为所有键或值应用一个函数;
每个操作都有 4 个版本:
operationKeys:处理键;operationValues:处理值;operation:处理键和值;operationEntries:处理Map.Entry对象;
对于上述各个操作,需要指定一个参数化阈值(parallelism threshold)。如果映射包含的元素多于这个阈值,就会并行完成批操作。如果希望批操作在一个线程中运行,可以使用阈值 Long.MAX_VALUE,如果希望用尽可能多的线程运行批操作,可以使用阈值 1。
search下面先来看
search方法。有以下版本:JavaU searchKeys(long threshold, BiFunction<? super K, ? extends U> f) U searchValues(long threshold, BiFunction<? super V, ? extends U> f) U search(long threshold, BiFunction<? super K, ? super V,? extends U> f) U searchEntries(long threshold, BiFunction<Map.Entry<K, V>, ? extends U> f)例如,假设我们希望找出第一个出现次数超过 1000 次的单词。需要搜索键和值:
JavaString result = map.search(threshold, (k, v) -> v > 1000 ? k : null);result会设置为第一个匹配的单词,或者如果搜索函数对所有输入都返回null, 则返回null。forEachforEach方法有两种形式。第一种形式只对各个映射条目应用一个消费者函数,例如:Javamap.forEach(threshold, (k, v) -> System.out.println(k + " -> " + v));第二种形式还有一个额外的转换器函数作为参数,要先应用这个函数,其结果会传递到消费者:
Javamap.forEach(threshold, (k, v) -> k + " -> " + v, // transformer System.out::println); // consumer转换器可以用作一个过滤器。只要转换器返回
null,这个值就会被悄无声息地跳过。例如,下面只打印值很大的条目:Javamap.forEach(threshold, (k, v) -> v > 1000 ? k + " -> " + v : null, // filter and transformer System.out::println); // the nulls are not passed to the consumerreducereduce操作用一个累加函数组合其输入。例如,可以如下计算所有值的总和:JavaLong sum = map.reduceValues(threshold, Long::sum);与
forEach类似,也可以提供一个转换器函数。可以如下计算最长的键的长度:JavaInteger maxlength = map.reduceKeys(threshold, String::length, // transformer Integer::max); // accumulator转换器可以作为一个过滤器,通过返回
null来排除不想要的输入。在这里,我们要统计多少个条目的值 > 1000:JavaLong count = map.reduceValues(threshold, v -> v > 1000 ? 1L : null, Long::sum);Tip:如果映射为空,或者所有条目都被过滤掉,
reduce操作会返回null。如果只有一个元素,则返回其转换结果,不会应用累加器。对于
int、long和double输出还有相应的特殊化操作,分别有后缀ToInt、ToLong和ToDouble。需要把输入转换为一个基本类型值,并指定一个默认值和一个累加器函数。映射为空时返回默认值。Javalong sum = map.reduceValuesToLong(threshold, Long::longValue, // transformer to primitive type 0, // default value for empty map Long::sum); // primitive type accumulatorTip:当只有一个元素时,这些特殊化版本与对象版本的行为有所不同。特殊化的版本不会直接返回转换后的值,而会先将转换后的值与提供的默认值应用累加器后再返回。
8.5. 并发集视图
假设你想要的是一个很大的线程安全的集而不是映射。实际上并没有 ConcurrentHashSet 类。当然,可以使用包含 “假” 值的 ConcurrentHashMap,不过这会得到一个映射而不是集,而且不能应用 Set 接口的操作。
静态 newKeySet 方法会生成一个 set<K>,这实际上是一个 ConcurrentHashMap<K, Boolean> 的键集视图。
Java
Set<String> words = ConcurrentHashMap.<String>newKeySet();当然,如果原来有一个映射,keySet 方法可以生成这个映射的键集。这个集是可更改的如果删除这个集的元素,键(以及相应的值)也会从映射中删除。不过,向键集增加元素没有意义,因为没有相应的值可以增加,因此会引发一个 UnsupportedOperationException 异常。ConcurrentHashMap 还有第二个 keySet 方法,它包含一个默认值,当需要为集增加元素时可以使用这个方法来创建集:
Java
Set<String> words = map.keySet(1L); // specify a default value
words.add("Java");8.6. 写数组的拷贝
CopyOnWriteArrayList 和 CopyOnWriteArraySet 是线程安全的集合,其中所有更改器会建立底层数组的一个副本。如果迭代访问集合的线程数超过更改集合的线程数,这样的安排是很有用的。当构造一个迭代器的时候,它包含当前数组的一个引用。如果这个数组后来被更改了,迭代器仍然引用旧数组,但是,集合的数组已经替换。因而,原来的迭代器可以访问一致的(但可能过时的)视图,而且不存在任何同步开销。
8.7. 并行数组算法
Arrays 类提供了大量并行化操作。静态 Arrays.parallelSort 方法可以对一个基本类型值或对象的数组排序。例如:
Java
var contents = new String(Files.readAllBytes(
Path.of("alice.txt")), StandardCharsets.UTF_8); // read file into string
String[] words = contents.split("[\\P{L}]+"); // split along nonletters
Arrays.parallelSort(words);对对象排序时,可以提供一个 Comparator:
Java
Arrays.parallelSort(words, Comparator.comparing(String::length));对于所有方法都可以提供一个范围的边界,如:
Java
values.parallelSort(values.length / 2, values.length); // sort the upper halfNote:乍一看,这些方法名中的
parallel可能有些奇怪,因为用户不用关心排序具体怎样完成。不过,API 设计者希望清楚地指出这里的排序是并行化的。这样一来,用户就会注意避免使用有副作用的比较器。
parallelSetAll 方法会用由一个函数计算得到的值填充一个数组。这个函数接收元素索引,然后计算相应位置上的值:
Java
Arrays.parallelSetAll(values, i -> i % 10);
// fills values with 0 1 2 3 4 5 6 7 8 9 0 1 2 ...最后还有一个 parallelPrefix 方法,它会用一个给定结合操作的相应前缀的累加结果替换各个数组元素。这是什么意思?这里给出一个例子。考虑数组 [1, 2, 3, 4, ...] 和 × 操作。执行 Arrays.parallelPrefix(values, (x, y) -> x * y) 之后,数组将包含:

看起来可能很奇怪,不过这个计算确实可以并行化。首先,结合相邻元素,如下所示:

灰值保持不变。显然,可以在不同的数组区中并行完成这个计算。下一步中,更新所指示的元素,为此将它与下面一个或两个位置上的元素相乘:

这同样可以并行完成。
8.8. 较早的线程安全集合
从 Java 的初始版本开始,Vector 和 HashTable 类就提供了动态数组和散列表的线程安全的实现。现在这些类被认为已经过时,而被 ArrayList 和 HashMap 类所取代。不过,那些类不是线程安全的,实际上,集合库中提供了一种不同的机制。任何集合类都可以通过使用同步包装器(synchronization wrapper)变成线程安全的:
Java
List<E> synchArrayList = Collections.synchronizedList(new ArrayList<E>());
Map<K, V> synchHashMap = Collections.synchronizedMap(new HashMap<K, V>());结果集合的方法使用锁加以保护,可以提供线程安全的访问。
应该确保没有任何线程通过原始的非同步方法访问数据结构。要确保这一点,最容易的方法是确定不保存原始对象的任何引用,简单地构造一个集合并立即传递给包装器,像我们的例子中所做的那样。
如果希望迭代访问一个集合,同时存在另一个线程有机会更改这个集合的风险,那么仍然需要使用 “客户端” 锁定:
Java
synchronized (synchHashMap) {
Iterator<K> iter = synchHashMap.keySet().iterator();
while (iter.hasNext()) ...;
}通常最好使用 java.util.concurrent 包中定义的集合,而不是同步包装器。特别是,ConcurrentHashMap 经过了精心实现,假如多个线程访问的是不同的桶,它们都能访问 ConcurrentHashMap 而不会相互阻塞。经常更改的数组列表是一个例外。在这种情况下,同步的 ArrayList 要胜过 CopyOnWriteArrayList。