Appearance
Spring In Action 6th:处理数据
1. 使用 JDBC 读写数据
在处理关系数据时,Java 开发人员有几种选择。最常见的两种选择是 JDBC 和 JPA。Spring 通过抽象支持这两者,使得与 JDBC 或 JPA 一起工作比在没有 Spring 的情况下更容易。
Spring JDBC 支持根植于 JdbcTemplate 类。JdbcTemplate 提供了一种方式,开发人员可以在与 JDBC 一起工作时执行 SQL 操作,而无需进行通常在使用 JDBC 时需要的所有仪式和样板。为了了解 JdbcTemplate 的作用,让我们首先看一个在没有 JdbcTemplate 的情况下执行简单查询的 Java 示例。
Java
@Override
public Optional<Ingredient> findById(String id) {
Connection connection = null;
PreparedStatement statement = null;
ResultSet resultSet = null;
try {
connection = dataSource.getConnection();
statement = connection.prepareStatement("select id, name, type from Ingredient where id=?");
statement.setString(1, id);
resultSet = statement.executeQuery();
Ingredient ingredient = null;
if (resultSet.next()) {
ingredient = new Ingredient(
resultSet.getString("id"),
resultSet.getString("name"),
Ingredient.Type.valueOf(resultSet.getString("type")));
}
return Optional.of(ingredient);
} catch (SQLException e) {
// ??? What should be done here ???
} finally {
if (resultSet != null) {
try {
resultSet.close();
} catch (SQLException e) {
}
}
if (statement != null) {
try {
statement.close();
} catch (SQLException e) {
}
}
if (connection != null) {
try {
connection.close();
} catch (SQLException e) {
}
}
}
return Optional.empty();
}相比上述示例,考虑下面使用 Spring 的 JdbcTemplate 的方法:
Java
private JdbcTemplate jdbcTemplate;
public Optional<Ingredient> findById(String id) {
List<Ingredient> results = jdbcTemplate.query(
"select id, name, type from Ingredient where id=?",
this::mapRowToIngredient,
id);
return results.size() == 0 ?
Optional.empty() :
Optional.of(results.get(0));
}
private Ingredient mapRowToIngredient(ResultSet row, int rowNum)
throws SQLException {
return new Ingredient(
row.getString("id"),
row.getString("name"),
Ingredient.Type.valueOf(row.getString("type")));
}以上代码明显比原始的 JDBC 示例简单得多,没有创建语句或连接。而且,在方法完成后,也没有对这些对象进行清理。最后,在不能在 catch 块中正确处理的异常上,也没有任何处理。剩下的是专注于执行查询(调用 JdbcTemplate 的 query() 方法)并将结果映射到 Ingredient 对象的代码(由 mapRowToIngredient() 方法处理)。
1.1. 为持久化改造领域实体
当将对象持久保存到数据库时,通常最好有一个字段来唯一标识对象。您的 Ingredient 类已经有一个 id 字段,但是您还需要为 Taco 和 TacoOrder 添加 id 字段。
此外,了解创建 Taco 和下订单的时间可能会很有用。您还需要为每个对象添加一个字段来捕获保存对象的日期和时间。以下是在 Taco 类中需要的新 id 和 createdAt 字段:
Java
@Data
public class Taco {
private Long id;
private Date createdAt = new Date();
...
}因为您使用 Lombok 在编译时自动生成访问器方法,所以除了声明 id 和 createdAt 属性之外,无需做任何其他事情。它们将在编译时根据需要生成适当的 Getter 和 Setter 方法。在 TacoOrder 类中也需要进行类似的更改,如下所示:
Java
@Data
public class TacoOrder implements Serializable {
private static final long serialVersionUID = 1L;
private Long id;
private Date placedAt;
...
}现在,您的领域类已准备好进行持久化。让我们看看如何使用 JdbcTemplate 将它们读取和写入数据库。
1.2. 使用 JdbcTemplate
在开始使用 JdbcTemplate 之前,您需要将其添加到项目的类路径中。您可以通过将 Spring Boot 的 JDBC starter 依赖项添加到构建中来轻松实现这一点,如下所示:
XML
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>您还需要一个数据库来存储数据。对于开发目的,嵌入式数据库就足够了。我倾向于使用 H2 嵌入式数据库,因此我已将以下依赖项添加到构建中:
XML
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<scope>runtime</scope>
</dependency>默认情况下,数据库名称是随机生成的。但是,如果出于某种原因,您需要使用 H2 控制台连接到数据库(Spring Boot DevTools 在 http://localhost:8080/h2-console 启用这个功能),那么很难确定数据库 URL。因此,通过在 application.properties 中设置一些属性来固定数据库名称是个好主意,如下所示:
Properties
spring.datasource.generate-unique-name=false
spring.datasource.name=tacocloud或者,如果您愿意,将 application.properties 重命名为 application.yml,并以 YAML 格式添加属性,如下所示:
YAML
spring:
datasource:
generate-unique-name: false
name: tacocloud属性文件格式和 YAML 格式之间的选择取决于您。Spring Boot 可以与两者一起正常工作。鉴于 YAML 的结构和可读性增强,我们将在后续使用 YAML 进行配置属性。
通过将 spring.datasource.generate-unique-name 属性设置为 false,我们告诉 Spring 不要为数据库名称生成唯一的随机值。相反,它应该使用 spring.datasource.name 属性设置的值。在这种情况下,数据库名称将是 tacocloud。因此,数据库 URL 将是 jdbc:h2:mem:tacocloud,您可以在 H2 控制台连接的 JDBC URL 中指定该值。
稍后,您将看到如何配置应用程序以使用外部数据库。但是现在,让我们继续编写一个获取和保存 Ingredient 数据的存储库。
1.2.1. 定义 JDBC 存储库
您的 Ingredient 存储库需要执行以下操作:
- 查询所有成分,返回
Ingredient对象的集合; - 根据
id查询单个Ingredient; - 保存
Ingredient对象;
以下 IngredientRepository 接口定义了这三个操作作为方法声明:
Java
package graceful.hello.spring.web.data;
import graceful.hello.spring.web.modules.Ingredient;
import java.util.Optional;
public interface IngredientRepository {
Iterable<Ingredient> findAll();
Optional<Ingredient> findById(String id);
Ingredient save(Ingredient ingredient);
}虽然该接口捕捉了您希望 Ingredient 存储库执行的操作的本质,但是您仍然需要编写一个使用 JdbcTemplate 来查询数据库的 IngredientRepository 实现。下面的代码是编写该实现的第一步:
Java
package graceful.hello.spring.web.data;
import graceful.hello.spring.web.modules.Ingredient;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Repository;
import java.util.Optional;
@Repository
public class JdbcIngredientRepository implements IngredientRepository {
private JdbcTemplate jdbcTemplate;
public JdbcIngredientRepository(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
...
}正如您所看到的,JdbcIngredientRepository 带有 @Repository 注解。这个注解是 Spring 定义的一组几个原型注解之一,包括 @Controller 和 @Component。通过用 @Repository 注解 JdbcIngredientRepository,您声明它应该被 Spring 组件扫描自动发现,并在 Spring 应用程序上下文中实例化为一个 bean。
当 Spring 创建 JdbcIngredientRepository bean 时,它将注入 JdbcTemplate。这是因为当只有一个构造函数时,Spring 隐式地通过该构造函数的参数应用依赖项的自动装配。如果存在多个构造函数,或者如果只是想要明确声明自动装配,则可以使用 @Autowired 注解构造函数,如下所示:
Java
...
@Autowired
public JdbcIngredientRepository(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
...构造函数将 JdbcTemplate 赋值给一个实例变量,该变量将在其他方法中用于查询和插入数据库。说到这些其他方法,让我们看一下 findAll() 和 findById() 的实现:
Java
@Override
public Iterable<Ingredient> findAll() {
return jdbcTemplate.query(
"select id, name, type from Ingredient",
this::mapRowToIngredient);
}
@Override
public Optional<Ingredient> findById(String id) {
List<Ingredient> results = jdbcTemplate.query(
"select id, name, type from Ingredient where id=?",
this::mapRowToIngredient,
id);
return results.size() == 0 ?
Optional.empty() :
Optional.of(results.get(0));
}
private Ingredient mapRowToIngredient(ResultSet row, int rowNum)
throws SQLException {
return new Ingredient(
row.getString("id"),
row.getString("name"),
Ingredient.Type.valueOf(row.getString("type")));
}findAll() 和 findById() 都以类似的方式使用 JdbcTemplate。findAll() 方法期望返回一个对象集合,它使用 JdbcTemplate 的 query() 方法。query() 方法接受查询的 SQL 以及 Spring 的 RowMapper 的实现,用于将结果集中的每一行映射到一个对象。query() 还接受一个参数(或多个参数)列表,这些参数是查询中需要的任何参数。但在这种情况下,没有必需的参数。
相比之下,findById() 方法将需要在其查询中包含一个 where 子句,以将 id 列的值与传递给方法的 id 参数的值进行比较。因此,对 query() 的调用包括 id 参数作为其最后一个参数。当执行查询时,? 将被替换为此值。
findAll() 和 findById() 的 RowMapper 参数都以对 mapRowToIngredient() 方法的方法引用形式给出。以下是使用 lambda 来替代显式 RowMapper 实现的一个示例:
Java
@Override
public Optional<Ingredient> findById(String id) {
return Optional.ofNullable(jdbcTemplate.queryForObject(
"select id, name, type from Ingredient where id=?",
(rs, rowNum) -> new Ingredient(
rs.getString("id"),
rs.getString("name"),
Ingredient.Type.valueOf(rs.getString("type"))),
id));
}接下来让我们看看如何实现 save() 方法。
1.2.2. 插入一行
JdbcTemplate 的 update() 方法可用于在数据库中写入或更新数据的任何查询。正如下面的代码所示,它可以用于将数据插入数据库中。
Java
@Override
public Ingredient save(Ingredient ingredient) {
jdbcTemplate.update(
"insert into Ingredient (id, name, type) values (?, ?, ?)",
ingredient.getId(),
ingredient.getName(),
ingredient.getType().toString());
return ingredient;
}由于不需要将 ResultSet 数据映射到对象,因此 update() 方法比 query() 简单得多。它只需要一个包含要执行的 SQL 的字符串,以及要分配给任何查询参数的值。在这种情况下,查询有三个参数,这对应于 save() 方法的最后三个参数,提供了成分的 ID、名称和类型。
JdbcIngredientRepository 完成后,您现在可以将其注入到 DesignTacoController 中,并使用它提供 Ingredient 对象的列表,而不是使用硬编码的值。DesignTacoController 的更改如下:
Java
...
public class DesignTacoController {
private final IngredientRepository ingredientRepo;
addIngredientsToModel() 方法使用注入的 IngredientRepository 的 findAll() 方法从数据库中获取所有成分。然后,它将它们过滤成不同的成分类型,然后将它们添加到模型中。
现在我们有了一个 IngredientRepository,可以从中获取 Ingredient 对象,我们还可以简化 IngredientByIdConverter:
Java
...
public class IngredientByIdConverter implements Converter<String, Ingredient> {
private IngredientRepository ingredientRepo;
您几乎已经准备好启动应用程序并尝试这些更改了。但在您可以开始从查询中引用的 Ingredient 表中读取数据之前,您可能应该创建该表并插入一些数据。
1.3. 定义 schema 并预加载数据
除了 Ingredient 表,您还需要一些保存订单和设计信息的表:
Taco_Order:保存订单的基本详细信息;Taco:保存关于 taco 设计的基本信息;Ingredient_Ref:保存 taco 映射到该 taco 成分的信息;Ingredient:保存成分信息;
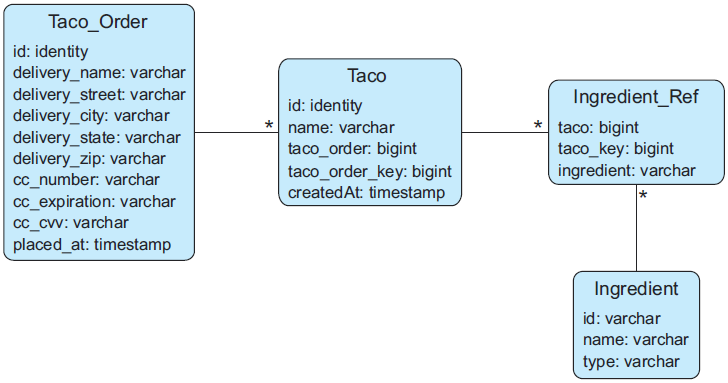
在我们的应用程序中,Taco 不能在没有 Taco_Order 的情况下存在。因此,Taco_Order 和 Taco 被视为聚合的成员,其中 Taco_Order 是聚合根。另一方面,Ingredient 对象是其自己聚合的唯一成员,并通过 Ingredient_Ref 由 Taco 引用。
Note:聚合和聚合根是领域驱动设计的核心概念,这是一种促进软件代码的结构和语言与业务领域相匹配的设计方法。尽管我们在 Taco Cloud 领域对象中应用了一些领域驱动设计(DDD),但 DDD 不仅仅是聚合和聚合根。关于这个主题的更多信息,请阅读这个领域的开创性作品,由 Eric Evans 著作的《Domain-Driven Design: Tackling Complexity in the Heart of Software》。
下面的代码显示了创建这些表的 SQL:
SQL
CREATE TABLE IF NOT EXISTS Taco_Order (
id IDENTITY
, delivery_Name VARCHAR(50) NOT NULL
, delivery_Street VARCHAR(50) NOT NULL
, delivery_City VARCHAR(50) NOT NULL
, delivery_State VARCHAR(2) NOT NULL
, delivery_Zip VARCHAR(10) NOT NULL
, cc_number VARCHAR(16) NOT NULL
, cc_expiration VARCHAR(5) NOT NULL
, cc_cvv VARCHAR(3) NOT NULL
, placed_at TIMESTAMP NOT NULL
);
CREATE TABLE IF NOT EXISTS Taco (
id IDENTITY
, name VARCHAR(50) NOT NULL
, taco_order BIGINT NOT NULL
, taco_order_key BIGINT NOT NULL
, created_at TIMESTAMP NOT NULL
);
CREATE TABLE IF NOT EXISTS Ingredient_Ref (
ingredient VARCHAR(4) NOT NULL
, taco BIGINT NOT NULL
, taco_key BIGINT NOT NULL
);
CREATE TABLE IF NOT EXISTS Ingredient (
id VARCHAR(4) NOT NULL
, name VARCHAR(25) NOT NULL
, type VARCHAR(10) NOT NULL
);
ALTER TABLE Taco ADD FOREIGN KEY (taco_order) REFERENCES Taco_Order (id);
-- There will be an error here, temporarily comment it out.
-- ALTER TABLE Ingredient_Ref ADD FOREIGN KEY (ingredient) REFERENCES Ingredient (id);如果在应用程序类路径的根目录中有一个名为 schema.sql 的文件,那么该文件中的 SQL 将在应用程序启动时对数据库执行。因此,您应该将上述 SQL 作为名为 schema.sql 的文件放置在 src/main/resources 文件夹中。
您还需要使用一些 Ingredient 数据预加载数据库。幸运的是,当应用程序启动时,Spring Boot 还将执行类路径根目录中名为 data.sql 的文件。因此,您可以使用下面清单中的插入语句在 src/main/resources/data.sql 中加载数据库的成分数据。
SQL
DELETE FROM Ingredient_Ref;
DELETE FROM Taco;
DELETE FROM Taco_Order;
DELETE FROM Ingredient;
INSERT INTO Ingredient (id, name, type) VALUES ('FLTO', 'Flour Tortilla', 'WRAP');
INSERT INTO Ingredient (id, name, type) VALUES ('COTO', 'Corn Tortilla', 'WRAP');
INSERT INTO Ingredient (id, name, type) VALUES ('GRBF', 'Ground Beef', 'PROTEIN');
INSERT INTO Ingredient (id, name, type) VALUES ('CARN', 'Carnitas', 'PROTEIN');
INSERT INTO Ingredient (id, name, type) VALUES ('TMTO', 'Diced Tomatoes', 'VEGGIES');
INSERT INTO Ingredient (id, name, type) VALUES ('LETC', 'Lettuce', 'VEGGIES');
INSERT INTO Ingredient (id, name, type) VALUES ('CHED', 'Cheddar', 'CHEESE');
INSERT INTO Ingredient (id, name, type) VALUES ('JACK', 'Monterrey Jack', 'CHEESE');
INSERT INTO Ingredient (id, name, type) VALUES ('SLSA', 'Salsa', 'SAUCE');
INSERT INTO Ingredient (id, name, type) VALUES ('SRCR', 'Sour Cream', 'SAUCE');即使您只为 Ingredient 数据开发了一个存储库,但此时您可以启动 Taco Cloud 应用程序并访问设计页面,以查看 JdbcIngredientRepository 的运行情况。
1.4. 插入数据
JdbcTemplate 如何使用来向数据库写入数据,您已经有所了解了。JdbcIngredientRepository 中的 save() 方法使用了 JdbcTemplate 的 update() 方法,将 Ingredient 对象保存到数据库中。
尽管那是一个不错的第一个示例,但可能有点太简单了。正如您很快会看到的,保存数据可能比 JdbcIngredientRepository 需要的更为复杂。
在我们的设计中,TacoOrder 和 Taco 是聚合的一部分,其中 TacoOrder 是聚合根。换句话说,Taco 对象在 TacoOrder 的上下文之外是不存在的。因此,目前我们只需要定义一个存储 TacoOrder 对象以及与其一起的 Taco 对象的仓库。这样的仓库可以在 OrderRepository 接口中定义,如下所示:
Java
package graceful.hello.spring.web.data;
import graceful.hello.spring.web.modules.TacoOrder;
public interface OrderRepository {
TacoOrder save(TacoOrder order);
}当您保存一个 TacoOrder 时,您还必须保存与其相关的 Taco 对象。而当您保存 Taco 对象时,您还需要保存表示构成 Taco 的每个 Ingredient 之间链接的对象。IngredientRef 类定义了 Taco 和 Ingredient 之间的链接,如下所示:
Java
package graceful.hello.spring.web.modules;
import lombok.Data;
@Data
public class IngredientRef {
private final String ingredient;
}save() 方法需要做的另一件事是确定保存后分配给订单的 ID。根据 schema.sql,Taco_Order 表上的 id 属性是一个标识,这意味着数据库将自动确定该值。但如果数据库为您确定了该值,那么您需要知道该值是什么,以便可以在从 save() 方法返回的 TacoOrder 对象中返回。幸运的是,Spring 提供了一个有用的 GeneratedKeyHolder 类型,可以帮助处理这个问题。但它涉及到使用预处理语句,如下所示的 save() 方法的实现:
Java
package graceful.hello.spring.web.data;
import graceful.hello.spring.web.modules.Taco;
import graceful.hello.spring.web.modules.TacoOrder;
import org.springframework.jdbc.core.JdbcOperations;
import org.springframework.jdbc.core.PreparedStatementCreator;
import org.springframework.jdbc.core.PreparedStatementCreatorFactory;
import org.springframework.jdbc.support.GeneratedKeyHolder;
import org.springframework.stereotype.Repository;
import org.springframework.transaction.annotation.Transactional;
import java.sql.Types;
import java.util.Arrays;
import java.util.Date;
import java.util.List;
@Repository
public class JdbcOrderRepository implements OrderRepository {
private JdbcOperations jdbcOperations;
public JdbcOrderRepository(JdbcOperations jdbcOperations) {
this.jdbcOperations = jdbcOperations;
}
@Override
@Transactional
public TacoOrder save(TacoOrder order) {
PreparedStatementCreatorFactory pscf =
new PreparedStatementCreatorFactory(
"insert into Taco_Order "
+ "(delivery_name, delivery_street, delivery_city, "
+ "delivery_state, delivery_zip, cc_number, "
+ "cc_expiration, cc_cvv, placed_at) "
+ "values (?,?,?,?,?,?,?,?,?)",
Types.VARCHAR, Types.VARCHAR, Types.VARCHAR,
Types.VARCHAR, Types.VARCHAR, Types.VARCHAR,
Types.VARCHAR, Types.VARCHAR, Types.TIMESTAMP
);
pscf.setReturnGeneratedKeys(true);
order.setPlacedAt(new Date());
PreparedStatementCreator psc =
pscf.newPreparedStatementCreator(
Arrays.asList(
order.getDeliveryName(),
order.getDeliveryStreet(),
order.getDeliveryCity(),
order.getDeliveryState(),
order.getDeliveryZip(),
order.getCcNumber(),
order.getCcExpiration(),
order.getCcCVV(),
order.getPlacedAt()));
GeneratedKeyHolder keyHolder = new GeneratedKeyHolder();
jdbcOperations.update(psc, keyHolder);
long orderId = keyHolder.getKey().longValue();
order.setId(orderId);
List<Taco> tacos = order.getTacos();
int i = 0;
for (Taco taco : tacos) {
saveTaco(orderId, i++, taco);
}
return order;
}
}在 save() 方法中似乎发生了很多事情,但我们可以将其分解为只有几个重要的步骤。首先,您创建一个 PreparedStatementCreatorFactory,描述插入查询以及查询输入字段的类型。因为您稍后需要获取保存的订单 ID,所以还需要调用 setReturnGeneratedKeys(true)。
在定义了 PreparedStatementCreatorFactory 后,您使用它创建一个 PreparedStatementCreator,传入将要持久化的 TacoOrder 对象的值。传递给 PreparedStatementCreator 的最后一个字段是订单创建的日期,您还需要将其设置在 TacoOrder 对象本身上,以便返回的 TacoOrder 将具有该信息。
现在您手头有了一个 PreparedStatementCreator,您可以通过调用 JdbcTemplate 上的 update() 方法实际保存订单数据,传入 PreparedStatementCreator 和一个 GeneratedKeyHolder。在保存订单数据后,GeneratedKeyHolder 将包含由数据库分配的 id 字段的值,并应将其复制到 TacoOrder 对象的 id 属性中。
此时,订单已保存,但您还需要保存与订单关联的 Taco 对象。您可以通过为订单中的每个 Taco 调用 saveTaco() 来实现这一点。
saveTaco() 方法与 save() 方法非常相似,如下所示:
Java
private long saveTaco(Long orderId, int orderKey, Taco taco) {
taco.setCreatedAt(new Date());
PreparedStatementCreatorFactory pscf =
new PreparedStatementCreatorFactory(
"insert into Taco "
+ "(name, created_at, taco_order, taco_order_key) "
+ "values (?, ?, ?, ?)",
Types.VARCHAR, Types.TIMESTAMP, Type.LONG, Type.LONG
);
pscf.setReturnGeneratedKeys(true);
PreparedStatementCreator psc =
pscf.newPreparedStatementCreator(
Arrays.asList(
taco.getName(),
taco.getCreatedAt(),
orderId,
orderKey));
GeneratedKeyHolder keyHolder = new GeneratedKeyHolder();
jdbcOperations.update(psc, keyHolder);
long tacoId = keyHolder.getKey().longValue();
taco.setId(tacoId);
saveIngredientRefs(tacoId, taco.getIngredients());
return tacoId;
}逐步而言,saveTaco() 的结构与 save() 相似,尽管它用于 Taco 数据而不是 TacoOrder 数据。最后,它调用 saveIngredientRefs() 来在 Ingredient_Ref 表中创建一行,将 Taco 行链接到 Ingredient 行。saveIngredientRefs() 方法如下:
Java
private void saveIngredientRefs(
long tacoId, List<Ingredient> ingredients) {
int key = 0;
for (Ingredient ingredient : ingredients) {
jdbcOperations.update(
"insert into Ingredient_Ref (ingredient, taco, taco_key) "
+ "values (?, ?, ?)",
ingredient.getId(), tacoId, key++);
}
}幸运的是,saveIngredientRefs() 方法要简单得多。它循环遍历 Ingredient 对象的列表,将每个对象保存到 Ingredient_Ref 表中。它还有一个本地的 key 变量,用作索引以确保成分的顺序保持不变。
在 OrderRepository 中需要做的就是将其注入到 OrderController 中,并在保存订单时使用它。以下清单显示了注入仓库所需的更改:
Java
...
public class OrderController {
private OrderRepository orderRepo;
如您所见,构造函数将 OrderRepository 作为参数,并将其分配给将在 processOrder() 方法中使用的实例变量。说到 processOrder() 方法,它已更改为调用 OrderRepository 上的 save() 方法(第 20 行),而不再是通过日志输出 TacoOrder 对象。
Spring 的 JdbcTemplate 使与关系数据库的交互比使用普通的 JDBC 简单得多。但即使使用了 JdbcTemplate,有些持久性任务仍然具有挑战性,特别是在持久化聚合中的嵌套领域对象时。
2. 使用 Spring Data JDBC
Spring Data 项目是一个庞大的总项目,包括多个子项目,其中大多数专注于使用各种不同类型的数据库进行数据持久化。一些最受欢迎的 Spring Data 项目包括:
- Spring Data JDBC:针对关系数据库的 JDBC 持久化;
- Spring Data JPA:针对关系数据库的 JPA 持久化;
- Spring Data MongoDB:持久化到 Mongo 文档数据库;
- Spring Data Neo4j:持久化到 Neo4j 图数据库;
- Spring Data Redis:持久化到 Redis 键值存储;
- Spring Data Cassandra:持久化到 Cassandra 列存储数据库;
Spring Data 为所有这些项目提供的最有趣和有用的功能之一是能够根据存储库规范接口自动创建存储库。因此,使用 Spring Data 项目进行持久化几乎没有或根本没有持久化逻辑,并且只涉及编写一个或多个存储库接口。
2.1. 添加 Spring Data JDBC 到项目构建中
Spring Data JDBC 启动依赖项如下所示的代码片段:
XML
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jdbc</artifactId>
</dependency>此时我们不再需要 JdbcTemplate 的 JDBC 启动器,因此可以删除以下依赖:
XML
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>2.2. 定义 Repository 接口
幸运的是,我们已经创建了 IngredientRepository 和 OrderRepository,因此定义我们的存储库的大部分工作已经完成。但我们需要对它们进行微小的更改,以便在 Spring Data JDBC 中使用它们。
Spring Data 将在运行时自动为我们的存储库接口生成实现。但它只会对扩展 Spring Data 提供的存储库接口的接口执行此操作。至少,我们的存储库接口需要扩展 Repository,以便 Spring Data 知道自动创建实现。例如,以下是如何编写 IngredientRepository,使其扩展 Repository:
Java
package graceful.hello.spring.web.data;
import graceful.hello.spring.web.modules.Ingredient;
import org.springframework.data.repository.Repository;
import java.util.Optional;
public interface IngredientRepository
extends Repository<Ingredient, String> {
Iterable<Ingredient> findAll();
Optional<Ingredient> findById(String id);
Ingredient save(Ingredient ingredient);
}如您所见,Repository 接口是参数化的。第一个参数是此存储库将持久化的对象的类型,即 Ingredient。第二个参数是持久化对象的 ID 字段的类型。对于 Ingredient,这是 String。
虽然通过扩展 Repository,IngredientRepository 将按照此处所示的方式工作,但 Spring Data 也提供了 CrudRepository 作为常见操作的基本接口,包括我们在 IngredientRepository 中定义的三个方法。因此,与其扩展 Repository,通常更容易扩展 CrudRepository,如下所示:
Java
package graceful.hello.spring.web.data;
import graceful.hello.spring.web.modules.Ingredient;
import org.springframework.data.repository.CrudRepository;
public interface IngredientRepository
extends CrudRepository<Ingredient, String> {
}同样,我们的 OrderRepository 也改为扩展 CrudRepository:
Java
package graceful.hello.spring.web.data;
import graceful.hello.spring.web.modules.TacoOrder;
import org.springframework.data.repository.CrudRepository;
public interface OrderRepository
extends CrudRepository<TacoOrder, Long> {
}在这两种情况下,由于 CrudRepository 已经定义了所需的方法,因此无需在 IngredientRepository 和 OrderRepository 接口中显式定义它们。
现在您有了两个存储库。您可能会想到需要编写两个存储库的实现,包括 CrudRepository 中定义的十几个方法。但这就是 Spring Data 的好消息 —— 没有必要编写实现!当应用程序启动时,Spring Data 会自动在运行时动态生成实现。这意味着存储库可以从一开始就立即使用。只需将它们注入到控制器中,您就完成了。
而且,由于 Spring Data 在运行时自动创建这些接口的实现,您不再需要在 JdbcIngredientRepository 和 JdbcOrderRepository 中编写显式的实现。您可以删除这两个类!
2.3. 为持久化注解领域实体
唯一需要做的另一件事就是对我们的领域类进行注解,以便 Spring Data JDBC 知道如何持久化它们。通常,这意味着使用 @Id 对 ID 属性进行注解,以便 Spring Data 知道哪个字段表示对象的 ID,并且可以选择使用 @Table 对类进行注解。
例如,TacoOrder 类可能会使用如下代码所示的 @Table 和 @Id 进行注解:
Java
...
import org.springframework.data.annotation.Id;
import org.springframework.data.relational.core.mapping.Table;
...
@Data
@Table
public class TacoOrder implements Serializable {
private static final long serialVersionUID = 1L;
@Id
private Long id;
...
}@Table 注解是完全可选的。默认情况下,对象会根据领域类名映射到一个表。在这种情况下,TacoOrder 被映射到一个名为 Taco_Order 的表。如果这对您来说没问题,那么您可以完全省略 @Table 注解,或者在没有参数的情况下使用它。但如果您希望将其映射到不同的表名,则可以将表名作为参数指定给 @Table,如下所示:
Java
@Table("Taco_Cloud_Order")至于 @Id 注解,它将 id 属性指定为 TacoOrder 的标识。TacoOrder 中的所有其他属性将根据它们的属性名称自动映射到列。例如,deliveryName 属性将自动映射到名为 delivery_name 的列。但如果您想显式定义列名映射,可以使用 @Column 对属性进行注解,如下所示:
Java
@Column("customer_name")
@NotBlank(message="Delivery name is required")
private String deliveryName;您还需要将 @Table 和 @Id 应用于其他领域类。这包括 Ingredient:
Java
...
import lombok.AccessLevel;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.springframework.data.annotation.Id;
import org.springframework.data.domain.Persistable;
import org.springframework.data.relational.core.mapping.Table;
@Data
@Table
@AllArgsConstructor
@NoArgsConstructor(access = AccessLevel.PRIVATE, force = true)
public class Ingredient
implements Persistable<String> {
@Id
private final String id;
...
@Override
public boolean isNew() {
return true;
}
...
}关于 Persistable<ID> 接口的介绍可以参考 Spring 官方文档。这里我们实现了该接口的 boolean isNew() 方法,该方法返回一个 boolean 值,用来指示实体对象是否已经持久化到数据库中。CrudRepository 会根据该值来判断是需要执行更新还是插入操作。
Taco:
Java
...
import org.springframework.data.annotation.Id;
import org.springframework.data.relational.core.mapping.Table;
...
@Data
@Table
public class Taco {
@Id
private Long id;
...
}至于 IngredientRef,它将自动映射到名为 Ingredient_Ref 的表,这对我们的应用程序来说非常完美。如果您愿意,可以使用 @Table 对其进行注解,但这不是必需的。Ingredient_Ref 表没有标识列,因此在 IngredientRef 中没有必要使用 @Id 进行注解。
通过这些小的更改,更不用说完全删除了 JdbcIngredientRepository 和 JdbcOrderRepository 类,您现在拥有的持久性代码要少得多。即便如此,由 Spring Data 在运行时生成的存储库实现仍然执行了使用 JdbcTemplate 的存储库所做的一切。实际上,它们有可能做得更多,因为这两个存储库接口都扩展了 CrudRepository,该接口提供了大约十几个用于创建、读取、更新和删除对象的操作。
2.4. 使用 CommandLineRunner 预加载数据
在使用 JdbcTemplate 进行工作时,我们使用 data.sql 预加载了应用程序启动时的 Ingredient 数据,该脚本在创建数据源 bean 时针对数据库执行。这种方法在使用 Spring Data JDBC 时同样适用。实际上,对于其支持的任何持久性机制,只要后备数据库是关系数据库,都可以使用相同的方法。但让我们看看另一种在启动时填充数据库的方法,它提供了更多的灵活性。
Spring Boot 提供了两个有用的接口,用于在应用程序启动时执行逻辑:CommandLineRunner 和 ApplicationRunner。这两个接口非常相似。两者都是功能接口,要求实现一个 run() 方法。在应用程序启动时,实现 CommandLineRunner 或 ApplicationRunner 的应用程序上下文中的任何 bean 在应用程序上下文和所有 bean 都被连接起来之后将调用它们的 run() 方法,但在发生任何其他事情之前。这为将数据加载到数据库中提供了一个便捷的地方。
由于 CommandLineRunner 和 ApplicationRunner 都是功能接口,因此可以在配置类中声明它们,使用 @Bean 注解的方法返回一个 lambda 函数。例如,以下是如何创建一个数据加载的 CommandLineRunner bean:
Java
@Bean
public CommandLineRunner dataLoader(IngredientRepository repo) {
return args -> {
repo.save(new Ingredient("FLTO", "Flour Tortilla", Type.WRAP));
repo.save(new Ingredient("COTO", "Corn Tortilla", Type.WRAP));
repo.save(new Ingredient("GRBF", "Ground Beef", Type.PROTEIN));
repo.save(new Ingredient("CARN", "Carnitas", Type.PROTEIN));
repo.save(new Ingredient("TMTO", "Diced Tomatoes", Type.VEGGIES));
repo.save(new Ingredient("LETC", "Lettuce", Type.VEGGIES));
repo.save(new Ingredient("CHED", "Cheddar", Type.CHEESE));
repo.save(new Ingredient("JACK", "Monterrey Jack", Type.CHEESE));
repo.save(new Ingredient("SLSA", "Salsa", Type.SAUCE));
repo.save(new Ingredient("SRCR", "Sour Cream", Type.SAUCE));
};
}在这里,IngredientRepository 被注入到 bean 方法中,并在 lambda 中使用它来创建 Ingredient 对象。CommandLineRunner 的 run() 方法接受一个参数,该参数是一个包含运行应用程序的所有命令行参数的 String 可变参数。我们不需要这些参数来将成分加载到数据库中,因此忽略了 args 参数。
或者,我们可以将数据加载程序 bean 定义为 ApplicationRunner 的 lambda 实现,如下所示:
Java
@Bean
public ApplicationRunner dataLoader(IngredientRepository repo) {
return args -> {
repo.save(new Ingredient("FLTO", "Flour Tortilla", Type.WRAP));
repo.save(new Ingredient("COTO", "Corn Tortilla", Type.WRAP));
repo.save(new Ingredient("GRBF", "Ground Beef", Type.PROTEIN));
repo.save(new Ingredient("CARN", "Carnitas", Type.PROTEIN));
repo.save(new Ingredient("TMTO", "Diced Tomatoes", Type.VEGGIES));
repo.save(new Ingredient("LETC", "Lettuce", Type.VEGGIES));
repo.save(new Ingredient("CHED", "Cheddar", Type.CHEESE));
repo.save(new Ingredient("JACK", "Monterrey Jack", Type.CHEESE));
repo.save(new Ingredient("SLSA", "Salsa", Type.SAUCE));
repo.save(new Ingredient("SRCR", "Sour Cream", Type.SAUCE));
};
}CommandLineRunner 和 ApplicationRunner 之间的关键区别在于传递给相应 run() 方法的参数。CommandLineRunner 接受一个 String 可变参数,这是命令行上传递的参数的原始表示。但 ApplicationRunner 接受一个 ApplicationArguments 参数,该参数提供了访问参数的方法,作为命令行的解析组件。
例如,假设我们希望我们的应用程序接受一个命令行参数,如 --version 1.2.3,并且需要在我们的加载程序 bean 中考虑该参数。如果使用 CommandLineRunner,我们需要在数组中搜索 --version,然后从数组中取下一个值。但使用 ApplicationRunner,我们可以查询给定的 ApplicationArguments 来获取 --version 参数,如下所示:
Java
public ApplicationRunner dataLoader(IngredientRepository repo) {
return args -> {
List<String> version = args.getOptionValues("version");
...
};
}getOptionValues() 方法返回一个 List<String>,允许多次指定选项参数。
使用 CommandLineRunner 或 ApplicationRunner 进行初始数据加载的好处在于,它们使用存储库来创建持久化对象,而不是使用 SQL 脚本。这意味着它们对关系数据库和非关系数据库都能同样有效。在下一章中,当我们看到如何使用 Spring Data 持久化到非关系数据库时,这将非常有用。
但在继续之前,让我们来看看另一个用于在关系数据库中持久化数据的 Spring Data 项目:Spring Data JPA。
3. 使用 Spring Data JPA 持久化数据
Spring Data JPA 提供了一种使用 JPA 进行持久化的方法,类似于 Spring Data JDBC 为 JDBC 提供的方法。
3.1. 添加 Spring Data JPA 到工程中
Spring Data JPA 可以通过 JPA 启动器提供给 Spring Boot 应用程序。此启动器依赖项不仅引入了 Spring Data JPA,而且通过传递性包含了 Hibernate 作为 JPA 实现,如下所示:
XML
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>如果要使用不同的 JPA 实现,那么您至少需要排除 Hibernate 依赖项并包含您选择的 JPA 库。例如,要使用 EclipseLink 而不是 Hibernate,您需要修改构建如下:
XML
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
<exclusions>
<exclusion>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.eclipse.persistence</groupId>
<artifactId>org.eclipse.persistence.jpa</artifactId>
<version>2.7.6</version>
</dependency>请注意,根据您选择的 JPA 实现,可能需要进行其他更改。请查阅您选择的 JPA 实现的文档以获取详细信息。现在让我们重新审视您的领域对象,并为 JPA 持久性对其进行注解。
3.2. 注解领域实体
正如您已经在 Spring Data JDBC 中看到的那样,Spring Data 在创建存储库方面表现得相当出色。但不幸的是,在使用 JPA 映射注解对领域对象进行注解时,它并没有提供太多帮助。您需要打开 Ingredient、Taco 和 TacoOrder 类,并加入一些注解。首先是 Ingredient 类,如下所示:
Java
...
import javax.persistence.Entity;
import javax.persistence.Id;
...
@Data
@Entity
@AllArgsConstructor
@NoArgsConstructor(access = AccessLevel.PRIVATE, force = true)
public class Ingredient {
@Id
private String id;
private String name;
private Type type;
public enum Type {
WRAP, PROTEIN, VEGGIES, CHEESE, SAUCE
}
}要将其声明为 JPA 实体,Ingredient 必须使用 @Entity 进行注解。并且必须使用 @Id 对其 id 属性进行注解,以将其指定为在数据库中唯一标识实体的属性。请注意,此 @Id 注解是来自 javax.persistence 包的 JPA 类型,而不是 Spring Data 在 org.springframework.data.annotation 包中提供的 @Id。
还请注意,我们不再需要 @Table 注解或需要实现 Persistable<ID>。虽然我们仍然可以在这里使用 @Table,但在使用 JPA 时是不必要的,它默认为类的名称(在这种情况下为 Ingredient)。至于 Persistable<ID>,它只在 Spring Data JDBC 中是必需的,用于确定是否要创建新实体或更新现有实体;而 JPA 会自动解决这个问题。
除了 JPA 特定的注解之外,您还会注意到您在类级别添加了 @NoArgsConstructor 注解。JPA 要求实体具有无参构造函数,因此 Lombok 的 @NoArgsConstructor 为您提供了这个构造函数。但您不希望能够使用它,因此通过将 access 属性设置为 AccessLevel.PRIVATE 将其设为私有。由于必须设置 final 属性,因此还将 force 属性设置为 true,这会导致 Lombok 生成的构造函数将其设置为 null、0 或 false 的默认值,具体取决于属性类型。
您还将添加 @AllArgsConstructor,以便轻松创建具有所有属性初始化的 Ingredient 对象。
现在让我们继续处理 Taco 类,并看看如何将其注解为 JPA 实体:
Java
...
import javax.persistence.*;
...
@Data
@Entity
public class Taco {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@NotNull
@Size(min = 5, message = "Name must be at least 5 characters long")
private String name;
private Date createdAt = new Date();
@Size(min = 1, message = "You must choose at least 1 ingredient")
@ManyToMany
private List<Ingredient> ingredients = new ArrayList<>();
public void addIngredient(Ingredient ingredient) {
this.ingredients.add(ingredient);
}
}与 Ingredient 一样,Taco 类现在使用 @Entity 进行注解,并且其 id 属性使用 @Id 进行了注解。因为您依赖数据库自动生成 ID 值,所以还使用 @GeneratedValue 对 id 属性进行注解,指定策略为 AUTO。
为了声明 Taco 与其关联的 Ingredient 列表之间的关系,您使用 @ManyToMany 对 ingredients 进行注解。一个 Taco 可以有多个 Ingredient 对象,而一个 Ingredient 可以是多个 Taco 的一部分。
最后,让我们将 TacoOrder 对象注解为实体:
Java
...
import javax.persistence.*;
...
@Data
@Entity
public class TacoOrder implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
...
@OneToMany(cascade = CascadeType.ALL)
private List<Taco> tacos = new ArrayList<>();
public void addTaco(Taco taco) {
this.tacos.add(taco);
}
}正如您所看到的,对 TacoOrder 的更改与对 Taco 的更改非常相似。值得注意的一个重要事项是,与 Taco 对象列表的关系使用 @OneToMany 进行了注解,表示这些 Taco 对象都属于此订单。此外,cascade 属性设置为 CascadeType.ALL,这样如果删除订单,则相关的 Taco 对象也将被删除。
3.3. 声明 JPA Repository
在创建了使用 JdbcTemplate 的存储库版本时,您明确声明了存储库应提供的方法。但是对于 Spring Data JDBC,您可以摒弃显式实现类,而是扩展了 CrudRepository 接口。实际上,CrudRepository 对于 Spring Data JPA 同样有效。例如,以下是新的 IngredientRepository 接口:
Java
public interface IngredientRepository
extends CrudRepository<Ingredient, String> {
}实际上,我们将与 Spring Data JPA 一起使用的 IngredientRepository 接口与我们为 Spring Data JDBC 定义的接口相同。CrudRepository 接口通常在 Spring Data 的许多项目中使用,而不管底层的持久性机制是什么。同样,您可以为 Spring Data JPA 定义与 Spring Data JDBC 相同的 OrderRepository,如下所示:
Java
public interface OrderRepository
extends CrudRepository<TacoOrder, Long> {
}CrudRepository 提供的方法非常适用于实体的通用持久性。但如果您有一些超出基本持久性的要求呢?让我们看看如何定制存储库以执行特定的查询。
3.4. 自定义 Repository
假设除了 CrudRepository 提供的基本 CRUD 操作之外,您还需要获取发送到特定邮政编码的所有订单。事实证明,通过在 OrderRepository 中添加以下方法声明,这可以很容易地解决:
Java
List<TacoOrder> findByDeliveryZip(String deliveryZip);在生成存储库实现时,Spring Data 检查存储库接口中的每个方法,解析方法名称,并尝试了解方法在持久化对象(在这种情况下为 TacoOrder)的上下文中的目的。实质上,Spring Data 定义了一种迷你领域特定语言(DSL),其中在存储库方法签名中表达了持久性详细信息。
Spring Data 知道此方法旨在查找订单,因为您已经使用 TacoOrder 对 CrudRepository 进行了参数化。方法名称 findByDeliveryZip() 明确表明,此方法应查找所有 TacoOrder 实体,通过将其 deliveryZip 属性与作为参数传递给方法的值进行匹配。
findByDeliveryZip() 方法足够简单,但是 Spring Data 也可以处理更有趣的方法名称。存储库方法由动词、可选主语、单词 By 和谓词组成。在 findByDeliveryZip() 的情况下,动词是 find,谓词是 DeliveryZip;主语未指定,被隐含为 TacoOrder。
让我们考虑另一个更复杂的例子。假设您需要查询在给定日期范围内交付到特定邮政编码的所有订单。在这种情况下,向 OrderRepository 添加以下方法可能会很有用:
Java
List<TacoOrder> readOrdersByDeliveryZipAndPlacedAtBetween(
String deliveryZip, Date startDate, Date endDate);图 3.1 说明了当生成存储库实现时 Spring Data 如何解析和理解 readOrdersByDeliveryZipAndPlacedAtBetween() 方法。正如您所看到的,readOrdersByDeliveryZipAndPlacedAtBetween() 中的动词是 read。Spring Data 还理解 find、read 和 get 作为获取一个或多个实体的同义词。或者,如果您希望该方法仅返回匹配实体的计数 int,则还可以使用 count 作为动词。
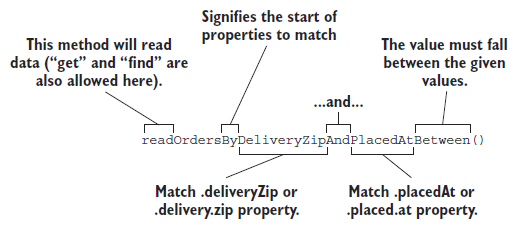
尽管方法的主语是可选的,在这里它说的是 Orders。Spring Data 忽略主语中的大多数词语,因此您可以将方法命名为 readPuppiesBy...,它仍然会找到 TacoOrder 实体,因为 CrudRepository 的参数化类型就是 TacoOrder。
谓词跟随在方法名称中的 By 之后,是方法签名中最有趣的部分。在这种情况下,谓词涉及两个 TacoOrder 属性:deliveryZip 和 placedAt。deliveryZip 属性必须等于传递给方法的第一个参数的值。关键字 Between 表示 deliveryZip 的值必须在方法的最后两个参数传递的值之间。
除了隐式的 Equals 操作和 Between 操作之外,Spring Data 方法签名还可以包括以下任意运算符:
IsAfter、After、IsGreaterThan、GreaterThan;IsGreaterThanEqual、GreaterThanEqual;IsBefore、Before、IsLessThan、LessThan;IsLessThanEqual、LessThanEqual;IsBetween、Between;IsNull、Null;IsNotNull、NotNull;IsIn、In;IsNotIn、NotIn;IsStartingWith、StartingWith、StartsWith;IsEndingWith、EndingWith、EndsWith;IsContaining、Containing、Contains;IsLike、Like;IsNotLike、NotLike;IsTrue、True;IsFalse、False;Is、Equals;IsNot、Not;IgnoringCase、IgnoresCase;
作为对 IgnoringCase 和 IgnoresCase 的替代,您还可以将 AllIgnoringCase 或 AllIgnoresCase 放置在方法上,以忽略所有字符串比较的大小写。例如,考虑以下方法:
Java
List<TacoOrder> findByDeliveryToAndDeliveryCityAllIgnoresCase(
String deliveryTo, String deliveryCity);最后,您还可以在方法名称的末尾放置 OrderBy,以按指定列对结果进行排序。例如,要按 deliveryTo 属性排序,请使用以下代码:
Java
List<TacoOrder> findByDeliveryCityOrderByDeliveryTo(String city);尽管命名约定对于相对简单的查询可能很有用,但可以想象对于更复杂的查询,方法名称可能会变得很复杂。在这种情况下,请随意命名方法,并使用 @Query 进行注释,以显式指定在调用方法时要执行的查询,如下例所示:
Java
@Query("Order o where o.deliveryCity='Seattle'")
List<TacoOrder> readOrdersDeliveredInSeattle();在这个简单的 @Query 使用中,您请求所有在西雅图交付的订单。但是您可以使用 @Query 执行几乎任何您可以想象的 JPA 查询,即使按照命名约定很难或不可能实现查询。
自定义查询方法也适用于 Spring Data JDBC,但有以下关键区别:
所有自定义查询方法都需要
@Query。这是因为,与 JPA 不同,Spring Data JDBC 没有映射元数据来帮助自动从方法名称中推断查询;@Query中指定的所有查询必须是 SQL 查询,而不是 JPA 查询;
后续我们将扩展我们对 Spring Data 的使用,以处理非关系型数据库。在那时,您将看到自定义查询方法工作方式非常相似,尽管 @Query 中使用的查询语言将特定于底层数据库。
4. 总结
Spring 的
JdbcTemplate大大简化了使用 JDBC 的工作;当您需要知道数据库生成的 ID 的值时,可以将
PreparedStatementCreator和KeyHolder结合使用;Spring Data JDBC 和 Spring Data JPA 使得与关系型数据的工作就像编写存储库接口一样简单;