Appearance
Java 基础:数据库编程
1. JDBC 配置
1.1. 数据库 URL
JDBC 使用了一种与普通 URL 相类似的语法来描述数据源。下面是这种语法的两个实例:
Text
jdbc:derby://localhost:1527/COREJAVA;create=true
jdbc:postgresql:COREJAVA上述 JDBC URL 指定了名为 COREJAVA 的一个 Derby 数据库和一个 PostgreSQL 数据库。
JDBC URL 的一般语法为:
EBNF
"jdbc:", subprotocol, ":", other stuff其中,subprotocol 用于选择连接到数据库的具体驱动程序。
other stuff 参数的格式随所使用的 subprotocol 不同而不同。如果要了解具体格式,你需要查阅数据库供应商提供的相关文档。
1.2. 驱动程序 JAR 文件
你需要获得包含了你所使用的数据库的驱动程序的 JAR 文件。如果你使用的是 Derby,那么就需要 derbyclient.jar。如果你使用的是其他的数据库,那么就需要去寻找恰当的驱动程序。例如,PostgreSQL 的驱动程序可以在 http://jdbc.postgresql.org 处找到。
在运行访问数据库的程序时,需要将驱动程序的 JAR 文件包括到类路径中(编译时并不需要这个 JAR 文件)。
在从命令行启动程序时,只需要使用下面的命令:
Bash
$ java -classpath driverPath:. ProgramName在 Windows 上,可以使用分号将当前路径(即由 . 字符表示的路径)与驱动程序 JAR 文件分隔开。
1.3. 注册驱动器类
许多 JDBC 的 JAR 文件(例如 Derby 驱动程序)会自动注册驱动器类,在这种情况下,可以跳过本节所描述的手动注册步骤。包含 METAINF/services/java.sql.Driver 文件的 JAR 文件可以自动注册驱动器类,解压缩驱动程序 JAR 文件就可以检查其是否包含该文件。
如果驱动程序 JAR 文件不支持自动注册,那就需要找出数据库提供商使用的 JDBC 驱动器类的名字。典型的驱动器名字如下:
Text
org.apache.derby.jdbc.ClientDriver
org.postgresql.Driver通过使用 DriverManager,可以用两种方式来注册驱动器。一种方式是在 Java 程序中加载驱动器类,例如:
Java
Class.forName("org.postgresql.Driver"); // force loading of driver class这条语句将使得驱动器类被加载,由此将执行可以注册驱动器的静态初始化器。
另一种方式是设置 jdbc.drivers 属性。可以用命令行参数来指定这个属性,例如:
Bash
$ java -Djdbc.drivers=org.postgresql.Driver ProgramName或者在应用中用下面这样的调用来设置系统属性:
Java
System.setProperty("jdbc.drivers", "org.postgresql.Driver");在这种方式中可以提供多个驱动器,用冒号将它们分隔开,例如:
Text
org.postgresql.Driver:org.apache.derby.jdbc.ClientDriver1.4. 连接到数据库
在 Java 程序中,我们可以用下面这样的代码打开一个数据库连接:
Java
String url = "jdbc:postgresql:COREJAVA";
String username = "dbuser";
String password = "secret";
Connection conn = DriverManager.getConnection(url, username, password);驱动管理器会遍历所有注册过的驱动程序,以便找到一个能够使用数据库 URL 中指定的子协议的驱动程序。
getConnection 方法返回一个 Connection 对象。在下一节中,我们将详细介绍如何使用 Connection 对象来执行 SQL 语句。
Note:在默认情况下,Derby 允许我们使用任何用户名进行连接,并且不检查密码。它会为每个用户生成一个单独的表集合,而默认的用户名是
app。
以下测试程序将所有这些步骤放到了一起:它从名为 database.properties 的文件中加载连接参数,并连接到数据库。示例代码中提供的 database.properties 文件包含的是关于 Derby 数据库的连接信息,如果使用其他的数据库,则需要将与数据库相关的连接信息放到这个文件中。下面是一个用于连接到 PostgreSQL 数据库的示例:
Properties
jdbc.drivers=org.postgresql.Driver
jdbc.url=jdbc:postgresql:COREJAVA
jdbc.username=dbuser
jdbc.password=secret要运行这个测试程序,需要先启动数据库,并像下面这样启动这个程序:
Bash
$ java -classpath .:driverJAR test.TestDBNote:Windows 用户需要注意,用
;代替:来分隔路径元素。
Tip:调试与 JDBC 相关的问题时,有种方法是启用 JDBC 的跟踪机制。调用
DriverManager.setLogWriter方法可以将跟踪信息发送给PrintWriter,而PrintWriter将输出 JDBC 活动的详细列表。大多数 JDBC 驱动程序的实现都提供了用于跟踪的附加机制,例如,在使用 Derby 时,可以在 JDBC 的 URL 中添加traceFile选项,如jdbc:derby://localhost:1527/COREJAVA;create=true;traceFile=trace.out。
Java
package test;
import java.nio.file.*;
import java.sql.*;
import java.io.*;
import java.util.*;
/**
* This program tests that the database and the JDBC driver are correctly configured.
*
* @author Cay Horstmann
* @version 1.03 2018-05-01
*/
public class TestDB {
public static void main(String args[]) throws IOException {
try {
runTest();
} catch (SQLException ex) {
for (Throwable t : ex)
t.printStackTrace();
}
}
/**
* Runs a test by creating a table, adding a value, showing the table contents, and
* removing the table.
*/
public static void runTest() throws SQLException, IOException {
try (Connection conn = getConnection();
Statement stat = conn.createStatement()) {
stat.executeUpdate("CREATE TABLE Greetings (Message CHAR(20))");
stat.executeUpdate("INSERT INTO Greetings VALUES ('Hello, World!')");
try (ResultSet result = stat.executeQuery("SELECT * FROM Greetings")) {
if (result.next())
System.out.println(result.getString(1));
}
stat.executeUpdate("DROP TABLE Greetings");
}
}
/**
* Gets a connection from the properties specified in the file database.properties.
*
* @return the database connection
*/
public static Connection getConnection() throws SQLException, IOException {
var props = new Properties();
try (InputStream in = Files.newInputStream(Paths.get("database.properties"))) {
props.load(in);
}
String drivers = props.getProperty("jdbc.drivers");
if (drivers != null) System.setProperty("jdbc.drivers", drivers);
String url = props.getProperty("jdbc.url");
String username = props.getProperty("jdbc.username");
String password = props.getProperty("jdbc.password");
return DriverManager.getConnection(url, username, password);
}
}2. 使用 JDBC 语句
2.1. 执行 SQL 语句
在执行 SQL 语句之前,首先需要创建一个 Statement 对象。要创建 Statement 对象,需要使用调用 DriverManager.getConnection 方法所获得的 Connection 对象。
Java
Statement stat = conn.createStatement();接着,把要执行的 SQL 语句放入字符串中,例如:
Java
String command = "UPDATE Books"
+ " SET Price = Price - 5.00"
+ " WHERE Title NOT LIKE ‘%Introduction%’";然后,调用 Statement 接口中的 executeUpdate 方法:
Java
stat.executeUpdate(command);executeUpdate 方法将返回受 SQL 语句影响的行数,或者对不返回行数的语句返回 0。例如,在先前的例子中调用 executeUpdate 方法将返回那些降价 5 美元的行数。
executeUpdate 方法既可以执行诸如 INSERT、UPDATE 和 DELETE 之类的操作,也可以执行诸如 CREATE TABLE 和 DROP TABLE 之类的数据定义语句。但是,执行 SELECT 查询时必须使用 executeQuery 方法。另外还有一个 execute 语句可以执行任意的 SQL 语句,此方法通常只用于由用户提供的交互式查询。
当我们执行查询操作时,通常感兴趣的是查询结果。executeQuery 方法会返回一个 ResultSet 类型的对象。可以通过它来每次一行地迭代遍历所有查询结果。
Java
ResultSet rs = stat.executeQuery("SELECT * FROM Books");
while (rs.next()) {
// look at a row of the result set
}Tip:
ResultSet接口的迭代协议与java.util.Iterator接口稍有不同。对于ResultSet接口,迭代器初始化时被设定在第一行之前的位置,必须调用next方法将它移动到第一行。另外,它没有hasNext方法,我们需要不断地调用next,直至该方法返回false。
结果集中行的顺序是任意排列的。除非使用 ORDER BY 子句指定行的顺序,否则不能为行序强加任何意义。
查看每一行时,可能希望知道其中每一列的内容,有许多访问器(accessor)方法可以用于获取这些信息。
Java
String isbn = rs.getString(1);
double price = rs.getDouble("Price");不同的数据类型有不同的访问器,比如 getString 和 getDouble。每个访问器都有两种形式,一种接受数字型参数,另一种接受字符串参数。当使用数字型参数时,我们指的是该数字所对应的列。例如,rs.getString(1) 返回的是当前行中第一列的值。
Tip:与数组的索引不同,数据库的列序号是从 1 开始计算的。
当使用字符串参数时,指的是结果集中以该字符串为列名的列。例如,rs.getDouble("Price") 返回列名为 Price 的列所对应的值。使用数字型参数效率更高一些,但是使用字符串参数可以使代码易于阅读和维护。
当 get 方法的类型和列的数据类型不一致时,每个 get 方法都会进行合理的类型转换。例如,调用 rs.getString("Price") 时,该方法会将 Price 列的浮点值转换成字符串。
2.2. 管理连接、语句和结果集
每个 Connection 对象都可以创建一个或多个 Statement 对象。同一个 Statement 对象可以用于多个不相关的命令和查询。但是,一个 Statement 对象最多只能有一个打开的结果集。如果需要执行多个查询操作,且需要同时分析查询结果,那么必须创建多个 Statement 对象。
需要说明的是,每个链接上的语句数是有限制的。使用 DatabaseMetaData 接口中的 getMaxStatements 方法可以获取 JDBC 驱动程序支持的同时打开的语句对象的总数。
实际上,我们通常并不需要同时处理多个结果集。如果结果集相互关联,我们可以使用组合查询,这样就只需要分析一个结果。对数据库进行组合查询比使用 Java 程序遍历多个结果集要高效得多。
我们应该确保在一个 Statement 对象上触发新的查询或更新语句之前结束对所有结果集的处理,因为前序查询的所有结果集都会被自动关闭。
使用完 ResultSet、Statement 或 Connection 对象后,应立即调用 close 方法。这些对象都使用了规模较大的数据结构,它们会占用数据库存服务器上的有限资源。
Statement 对象的 close 方法将自动关闭所有与其相关联的结果集。同样地,调用 Connection 类的 close 方法将关闭该连接上的所有语句。
反过来的情况是,可以在 Statement 上调用 closeOnCompletion 方法,在其所有结果集都被关闭后,该语句会立即被自动关闭。
如果所用连接都是短时的,那么无须操心语句和结果集的关闭。只需使用 try-with-resources 语句,确保连接对象不可能继续保持打开状态即可。
Java
try (Connection conn = ...) {
Statement stat = conn.createStatement();
ResultSet result = stat.executeQuery(queryString);
// process query result
}2.3. 分析 SQL 异常
每个 SQLException 都有一个由多个 SQLException 对象构成的链,这些对象可以通过 getNextException 方法获取。这个异常链是每个异常都具有的由 Throwable 对象构成的 “成因” 链之外的异常链,因此,我们需要用两个嵌套的循环来完整枚举所有的异常。幸运的是,SQLException 类得到了增强,实现了 Iterable<Throwable> 接口,其 iterator() 方法可以产生一个 Iterator<Throwable>,这个迭代器可以迭代这两个链,首先迭代第一个 SQLException 的成因链,然后迭代下一个 SQLException,以此类推。我们可以直接使用下面这个改进的 for 循环:
Java
for (Throwable t : sqlException) {
// do something with t
}可以在 SQLException 上调用 getSQLState 和 getErrorCode 方法来进一步分析它,其中第一个方法将产生符合 X/Open 或 SQL:2003 标谁的字符串(调用 DatabaseMetaData 接口的 getSQLStateType 方法可以查出驱动程序所使用的标准)。而错误代码是与具体的提供商相关的。
SQL 异常按照层次结构树的方式组织到了一起(如图 2.1 所示)。这使得我们可以按照与提供商无关的方式来捕获具体的错误类型。
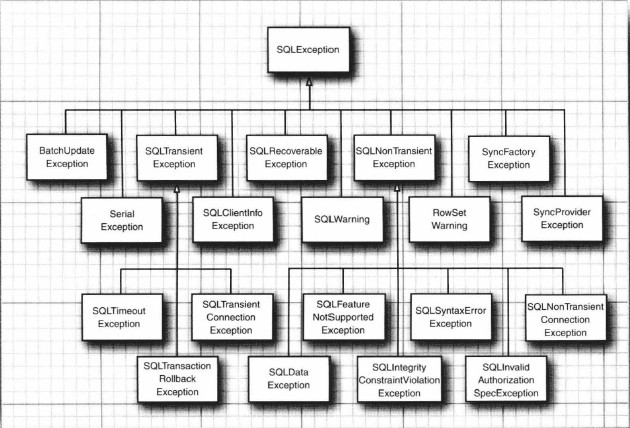
另外,数据库驱动程序可以将非致命问题作为警告报告,我们可以从连接、语句和结果集中获取这些警告。SQLWarning 类是 SQLException 的子类(尽管 SQLWarning 不会被当作异常抛出), 我们可以调用 getSQLState 和 getErrorCode 来获取有关警告的更多信息。与 SQL 异常类似,警告也是串成链的。要获得所有的警告,可以使用下面的循环:
Java
SQLWarning w = stat.getWarning();
while (w != null) {
// do something with
w = w.nextWarning();
}当数据从数据库中读出并意外被截断时,SQLWarning 的 DataTruncation 子类就派上用场了。如果数据截断发生在更新语句中,那么 DataTruncation 对象将会被当作异常抛出。
2.4. 示例:从文件中读取 SQL 并执行
以下是一个从文件中读取 SQL 并执行的示例:
Java
package exec;
import java.io.*;
import java.nio.charset.*;
import java.nio.file.*;
import java.util.*;
import java.sql.*;
/**
* Executes all SQL statements in a file. Call this program as <br>
* java -classpath driverPath:. ExecSQL commandFile
*
* @author Cay Horstmann
* @version 1.33 2018-05-01
*/
class ExecSQL {
public static void main(String args[]) throws IOException {
try (Scanner in = args.length == 0 ? new Scanner(System.in) : new Scanner(Paths.get(args[0]), StandardCharsets.UTF_8)) {
try (Connection conn = getConnection();
Statement stat = conn.createStatement()) {
while (true) {
if (args.length == 0) System.out.println("Enter command or EXIT to exit:");
if (!in.hasNextLine()) return;
String line = in.nextLine().trim();
if (line.equalsIgnoreCase("EXIT")) return;
if (line.endsWith(";")) // remove trailing semicolon
line = line.substring(0, line.length() - 1);
try {
boolean isResult = stat.execute(line);
if (isResult) {
try (ResultSet rs = stat.getResultSet()) {
showResultSet(rs);
}
} else {
int updateCount = stat.getUpdateCount();
System.out.println(updateCount + "rows updated");
}
} catch (SQLException e) {
for (Throwable t : e)
t.printStackTrace();
}
}
}
} catch (SQLException e) {
for (Throwable t : e)
t.printStackTrace();
}
}
/**
* Gets a connection from the properties specified in the file database.properties
*
* @return the database connection
*/
public static Connection getConnection() throws SQLException, IOException {
var props = new Properties();
try (InputStream in = Files.newInputStream(Paths.get("database.properties"))) {
props.load(in);
}
3. 执行查询操作
3.1. 预备语句
接下来我们准备使用一个新的特性,即预备语句(prepared statements)。如果我们要查询某个出版社的所有图书而不考虑具体的作者,那么该查询的 SQL 语句如下:
SQL
SELECT Books.Price, Books
FROM Books, Publishers
WHERE Books.Publisher_Id = Publishers.Publisher_Id AND Publishers.Name = the name from the list box我们没有必要在每次触发一个这样的查询时都建立新的查询语句,而是可以准备一个带有宿主变量的查询语句,每次查询时只需为该变量填入不同的字符串就可以反复多次地使用该语句。这一技术改进了查询性能,每当数据库执行一个查询时,它总是首先通过计算来确定查询策略,以便高效地执行查询操作。通过事先准备好查询并多次重用它,我们就可以确保查询所需的准备步骤只被执行一次。
在预备查询语句中,每个宿主变量都用 ? 来表示。如果存在一个以上的变量,那么在设置变量值时必须注意 ? 的位置。例如,如果我们的预备查询为如下形式:
Java
String publisherQuery
= "SELECT Books.Price, Books"
+ " FROM Books, Publishers"
+ " WHERE Books.Publisher_Id = Publishers.Publisher_Id AND Publishers.Name = ?";
PreparedStatement stat = conn.prepareStatement(publisherQuery);在执行预备语句之前,必须使用 set 方法将变量绑定到实际的值上。和 ResultSet 接口中的 get 方法类似,针对不同的数据类型也有不同的 set 方法。在本例中,我们为出版社名称设置了一个字符串值。
Java
stat.setString(1, publisher);第一个参数指的是需要设置的宿主变量的位置,位置 1 表示第一个 ?。第二个参数指的是赋予宿主变量的值。
如果想要重用已经执行过的预备查询语句,那么除非使用 set 方法或调用 clearParameters 方法,否则所有宿主变量的绑定都不会改变。这就意味着,在从一个查询到另一个查询的过程中,只需使用 setXxx 方法重新绑定那些需要改变的变量即可。
一旦为所有变量都绑定了具体的值,就可以执行预备语句了:
Java
ResultSet rs = stat.executeQuery();
// or
int r = stat.executeUpdate();Tip:在相关的
Connection对象关闭之后,PreparedStatement对象也就变得无效了。不过,许多数据库通常都会自动缓存预备语句。如果相同的查询被预备两次,数据库通常会直接重用查询策略。因此,无须过多考虑调用prepareStatement的开销。
以下是一个 PreparedStatement 的使用示例:
Java
package query;
import java.io.*;
import java.nio.file.*;
import java.sql.*;
import java.util.*;
/**
* This program demonstrates several complex database queries.
*
* @author Cay Horstmann
* @version 1.31 2018-05-01
*/
public class QueryTest {
private static final String allQuery = "SELECT Books.Price, Books.Title FROM Books";
private static final String authorPublisherQuery = "SELECT Books.Price, Books.Title"
+ " FROM Books, BooksAuthors, Authors, Publishers"
+ " WHERE Authors.Author_Id = BooksAuthors.Author_Id AND BooksAuthors.ISBN = Books.ISBN"
+ " AND Books.Publisher_Id = Publishers.Publisher_Id AND Authors.Name = ?"
+ " AND Publishers.Name = ?";
private static final String authorQuery
= "SELECT Books.Price, Books.Title FROM Books, BooksAuthors, Authors"
+ " WHERE Authors.Author_Id = BooksAuthors.Author_Id"
+ " AND BooksAuthors.ISBN = Books.ISBN"
+ " AND Authors.Name = ?";
private static final String publisherQuery
= "SELECT Books.Price, Books.Title FROM Books, Publishers"
+ " WHERE Books.Publisher_Id = Publishers.Publisher_Id AND Publishers.Name = ?";
private static final String priceUpdate = "UPDATE Books SET Price = Price + ? "
+ " WHERE Books.Publisher_Id = (SELECT Publisher_Id FROM Publishers WHERE Name = ?)";
private static Scanner in;
private static ArrayList<String> authors = new ArrayList<>();
private static ArrayList<String> publishers = new ArrayList<>();
public static void main(String[] args) throws IOException {
try (Connection conn = getConnection()) {
in = new Scanner(System.in);
authors.add("Any");
publishers.add("Any");
try (Statement stat = conn.createStatement()) {
// Fill the authors array list
var query = "SELECT Name FROM Authors";
try (ResultSet rs = stat.executeQuery(query)) {
while (rs.next())
authors.add(rs.getString(1));
}
// Fill the publishers array list
query = "SELECT Name FROM Publishers";
try (ResultSet rs = stat.executeQuery(query)) {
while (rs.next())
publishers.add(rs.getString(1));
}
}
var done = false;
while (!done) {
System.out.print("Q)uery C)hange prices E)xit: ");
String input = in.next().toUpperCase();
if (input.equals("Q"))
executeQuery(conn);
else if (input.equals("C"))
changePrices(conn);
else
done = true;
}
} catch (SQLException e) {
for (Throwable t : e)
System.out.println(t.getMessage());
}
}
/**
* Executes the selected query.
*
* @param conn the database connection
*/
private static void executeQuery(Connection conn) throws SQLException {
String author = select("Authors:", authors);
String publisher = select("Publishers:", publishers);
PreparedStatement stat;
if (!author.equals("Any") && !publisher.equals("Any")) {
stat = conn.prepareStatement(authorPublisherQuery);
stat.setString(1, author);
stat.setString(2, publisher);
} else if (!author.equals("Any") && publisher.equals("Any")) {
stat = conn.prepareStatement(authorQuery);
stat.setString(1, author);
} else if (author.equals("Any") && !publisher.equals("Any")) {
stat = conn.prepareStatement(publisherQuery);
stat.setString(1, publisher);
} else
stat = conn.prepareStatement(allQuery);
try (ResultSet rs = stat.executeQuery()) {
while (rs.next())
System.out.println(rs.getString(1) + ", " + rs.getString(2));
}
}
/**
* Executes an update statement to change prices.
*
* @param conn the database connection
*/
public static void changePrices(Connection conn) throws SQLException {
String publisher = select("Publishers:", publishers.subList(1, publishers.size()));
System.out.print("Change prices by: ");
double priceChange = in.nextDouble();
PreparedStatement stat = conn.prepareStatement(priceUpdate);
stat.setDouble(1, priceChange);
stat.setString(2, publisher);
int r = stat.executeUpdate();
System.out.println(r + " records updated.");
}
/**
* Asks the user to select a string.
*
* @param prompt the prompt to display
* @param options the options from which the user can choose
* @return the option that the user chose
*/
public static String select(String prompt, List<String> options) {
while (true) {
System.out.println(prompt);
for (int i = 0; i < options.size(); i++)
System.out.printf("%2d) %s%n", i + 1, options.get(i));
int sel = in.nextInt();
if (sel > 0 && sel <= options.size())
return options.get(sel - 1);
}
}
/**
* Gets a connection from the properties specified in the file database.properties.
*
* @return the database connection
*/
public static Connection getConnection() throws SQLException, IOException {
var props = new Properties();
try (InputStream in = Files.newInputStream(Paths.get("database.properties"))) {
props.load(in);
}
String drivers = props.getProperty("jdbc.drivers");
if (drivers != null) System.setProperty("jdbc.drivers", drivers);
String url = props.getProperty("jdbc.url");
String username = props.getProperty("jdbc.username");
String password = props.getProperty("jdbc.password");
return DriverManager.getConnection(url, username, password);
}
}Note:许多程序员都不喜欢使用上述如此复杂的 SQL 语句。比较常见的方法是使用大量的 Java 代码来迭代多个结果集,但是这种方法效率非常低。通常,使用数据库的查询代码要比使用 Java 程序好得多一一这是数据库的核心竞争力之一。一般而言,可以使用 SQL 解决的问题,就不要使用 Java 程序。
3.2. 读写 LOB
除了数字、字符串和日期之外,许多数据库还可以存储大对象,例如图片或其他数据。在 SQL 中,二进制大对象称为 BLOB, 字符型大对象称为 CLOB。
要读取 LOB,需要执行 SELECT 语句,然后在 ResultSet 上调用 getBlob 或 getClob 方法,这样就可以获得 Blob 或 Clob 类型的对象。要从 Blob 中获取二进制数据,可以调用 getBytes 或 getBinaryStream。例如,如果你有一张保存图书封面图像的表,那么就可以像下面这样获取一张图像:
Java
PreparedStatement stat = conn.prepareStatement("SELECT Cover FROM BookCovers WHERE ISBN=?");
...
stat.set(1, isbn);
try (ResultSet result = stat.executeQuery()) {
if (result.next()) {
Blob coverBlob = result.getBlob(1);
Image coverImage = ImageIO.read(coverBlob.getBinaryStream());
}
}类似地,如果获取了 Clob 对象,那么就可以通过调用 getSubString 或 getCharacterStream 方法来获取其中的字符数据。
要将 LOB 置于数据库中,需要在 Connection 对象上调用 createBlob 或 createClob,然后获取一个用于该 LOB 的输出流或写出器,写出数据,并将该对象存储到数据库中。例如,下面展示了如何存储一张图像:
Java
Blob coverBlob = connection.createBlob();
int offset = 0;
OutputStream out = coverBlob.setBinaryStream(offset);
ImageIO.write(coverImage, "PNG", out);
PreparedStatement stat = conn.prepareStatement("INSERT INTO Cover VALUES (?, ?)");
stat.set(1, isbn);
stat.set(2, coverBlob);
stat.executeUpdate();3.3. SQL 转义
“转义” 语法是各种数据库普遍支持的特性,但是数据库使用的是与数据库相关的语法变体,因此,将转义语法转译为特定数据库的语法是 JDBC 驱动程序的任务之一。
转义主要用下列场景:
日期和时间字面常量:
日期和时间字面常量随数据库的不同而变化很大。要嵌入日期或时间字面常量,需要按照 ISO 8601 格式 https://www.cl.cam.ac.uk/~mgk25/iso-time.html 指定它的值,之后驱动程序会将其转译为本地格式。应该使用
d、t、ts来表示DATE、TIME和TIMESTAMP值:Text{d '2008-01-24'} {t '23:59:59'} {ts '2008-01-24 23:59:59.999'}调用标量函数:
标量函数(scalar function)是指仅返回单个值的函数。在数据库中包含大量的函数,但是不同的数据库中这些函数名存在着差异。JDBC 规范提供了标准的名字,并将其转译为数据库相关的名字。要调用函数,需要像下面这样嵌入标准的函数名和参数:
Text{fn left(?, 20)} {fn user()}在 JDBC 规范中可以找到它支持的函数名的完整列表。
调用存储过程:
存储过程(stored procedure)是在数据库中执行的用数据库相关的语言编写的过程。要调用存储过程,需要使用
call转义命令,在存储过程没有任何参数时,可以不用加上括号。另外,应该用=来捕获存储过程的返回值:Text{call PROC1(?, ?)} {call PROC2} {call ? = PROC3(?)}外连接:
两个表的外连接(outer join)并不要求每个表的所有行都要根据连接条件进行匹配,例如,假设有如下的查询:
SQLSELECT * FROM {oj Books LEFT OUTER JOIN Publishers ON Books.Publisher_Id = Publisher.Publisher_Id}这个查询的执行结果中将包含有
Publisher_Id在Publishers表中没有任何匹配的书,其中,Publisher_Id为NULL值的行,就表示不存在任何匹配。如果应该使用RIGHT OUTER JOIN,就可以囊括没有任何匹配图书的出版商,而使用FULL OUTER JOIN可以同时返回这两类没有任何匹配的信息。由于并非所有的数据库对于这些连接都使用标准的写法,因此需要使用转义语法。在
LIKE子句中的转义字符:_和%字符在LIKE子句中其有特殊含义,用来匹配一个字符或一个字符序列。目前并不存在任何在字面上使用它们的标谁方式,所以如果想要匹配所有包含_字符的字符串,就必须使用下面的结构:SQL... WHERE ? LIKE %!_% {escape '!'}这里我们将
!定义为转义字符,而!_组合表示字面常量下划线。
3.4. 多结果集
在执行存储过程,或者在使用允许在单个查询中提交多个 SELECT 语句的数据库时,一个查询有可能会返回多个结果集。下面是获取所有结果集的步骤:
- 使用
execute方法来执行 SQL 语句; - 获取第一个结果集或更新计数;
- 重复调用
getMoreResults方法以移动到下一个结果集; - 当不存在更多的结果集或更新计数时,完成操作;
如果由多结果集构成的链中的下一项是结果集,execute 和 getMoreResults 方法将返回 true,而如果在链中的下一项不是更新计数,getUpdateCount 方法将返回 -1。
下面的循环可以遍历所有的结果:
Java
boolean isResult = stat.execute(command);
boolean done = false;
while (!done) {
if (isResult) {
ResultSet result = stat.getResultSet();
// do something with result
} else {
int updateCount = stat.getUpdateCount();
if (updateCount >= 0)
// do something with updateCount
else
done = true;
}
if (!done) isResult = stat.getMoreResults();
}3.5. 获取自动生成的键
大多数数据库都支持某种在数据库中对行自动编号的机制。但是,不同的提供商所提供的机制之间存在着很大的差异,而这些自动编号的值经常用作主键。尽管 JDBC 没有提供独立于提供商的自动生成键的解决方案,但是它提供了获取自动生成键的有效途径。当我们向数据表中插入一个新行,且其键自动生成时,可以用下面的代码来获取这个键:
Java
stat.executeUpdate(insertStatement, Statement.RETURN_GENERATED_KEYS);
ResultSet rs = stat.getGeneratedKeys();
if (rs.next()) {
int key = rs.getInt(1);
...
}4. 可滚动和可更新的结果集
4.1. 可滚动的结果集
默认情况下,结果集是不可滚动和不可更新的。为了从查询中获取可滚动的结果集,必须使用下面的方法得到一个不同的 Statement 对象:
Java
Statement stat = conn.createStatement(type, concurrency);如果要获得预备语句,请调用下面的方法:
Java
PreparedStatement stat = conn.prepareStatement(command, type, concurrency);表 4.1 和表 4.2 列出了 type 和 concurrency 的所有可能值,可以有以下几种选择:
- 是否希望结果集是可滚动的?如果不需要,则使用
ResultSet.TYPE_FORWARD_ONLY; - 如果结果集是可滚动的,且数据库在查询生成结果集之后发生了变化,那么是否希望结果集反映出这些变化;
- 是否希望通过编辑结果集就可以更新数据库?(详细说明请参见可更新的结果集小节。);
| 值 | 解释 |
|---|---|
TYPE_FORWARD_ONLY | 结果集不能滚动(默认值) |
TYPE_SCROLL_INSENSITIVE | 结果集可以滚动,但对数据库变化不敏感 |
TYPE_SCROLL_SENSITIVE | 结果集可以滚动,但对数据库变化敏感 |
ResultSet 类的 type 值| 值 | 解释 |
|---|---|
CONCUR_READ_ONLY | 结果集不能用于更新数据库(默认值) |
CONCUR_UPDATABLE | 结果集可以用于更新数据库 |
ResultSet 类的 concurrency 值例如,如果只想滚动遍历结果集,而不想编辑它的数据,那么可以使用以下语句:
Java
Statement stat = conn.createStatement(ResultSet.TYPE_SCROLL_INSENSITIVE, ResultSet.CONCUR_READ_ONLY);现在,通过调用以下方法获得的所有结果集都将是可滚动的。
Java
ResultSet rs = stat.executeQuery(query);可滚动的结果集有一个游标,用以指示当前位置。
Tip:并非所有的数据库驱动程序都支持可滚动和可更新的结果集。使用
DatabaseMetaData接口中的supportsResultSetType和supportsResultSetConcurrency方法,我们可以获知在使用特定的驱动程序时,某个数据库究竟支持哪些结果集类型以及哪些并发模式。即便是数据库支持所有的结果集模式,某个特定的查询也可能无法产生带有所要求的所有属性的结果集。例如,一个复杂查询的结果集就有可能是不可更新的结果集。在这种情况下,executeQuery方法将返回一个功能较少的ResultSet对象,并添加一个SQLWarning到连接对象中。可以使用ResultSet接口中的getType和getConcurrency方法查看结集实际支持的模式。如果不检查结果集的功能就发起一个不支持的擬作,比如对不可滚动的结果集调用previous方法,那么该操作将抛出一个SQLException异常。
在结果集上滚动是非常简单的,可以使用:
Java
if (rs.previous()) ...;向后滚动。如果游标位于一个实际的行上,那么该方法将返回 true;如果游标位于第一行之前,那么返回 false。
可以使用以下调用将游标向后或向前移动多行:
Java
rs.relative(n);或者,还可以将游标设置到指定的行号上:
Java
rs.absolute(n);调用以下方法将返回当前行的行号:
Java
int currentRow = rs.getRow();结果集中第一行的行号为 1。如果返回值为 0,那么游标当前不在任何行上,它要么位于第一行之前,要么位于最后一行之后。
first、last、beforeFirst 和 afterLast 这些简便方法用于将游标移动到第一行、最后一行、第一行之前或最后一行之后。isFirst、isLast、isBeforeFirst 和 isAfterLast 用于测试游标是否位于这些特殊位置上。
使用可滚动的结果集是非常简单的,将查询数据放入缓存中的复杂工作是由数据库驱动程序在后台完成的。
4.2. 可更新的结果集
如果希望编辑结果集中的数据,并且将结果集上的数据变更自动反映到数据库中,那么就必须使用可更新的结果集。可更新的结果集并非必须是可滚动的,但如果将数据提供给用户去编辑,那么通常也会希望结果集是可滚动的。
如果要获得可更新的结果集,应该使用以下方法创建一条语句:
Java
Statement stat = conn.createStatement(ResultSet.TYPE_SCROLL_INSENSITIVE, ResultSet.CONCUR_UPDATABLE);Note:并非所有的查询都会返回可更新的结果集。如果查询涉及多个表的连接操作,那么它所产生的结果集将是不可更新的。如果查询只涉及一个表,或者在查询时是使用主键连接多个表的,那么它所产生的结果集将是可更新的结果集。可以调用
ResultSet接口中的getConcurrency方法来确定结果集是否是可更新的。
例如,假设想提高某些图书的价格,但是在执行 UPDATE 语句时又没有一个简单的提价标准。此时,就可以根据任意设定的条件,迭代遍历所有的图书并更新它们的价格。
Java
String query = "SELECT * FROM Books";
ResultSet rs = stat.executeQuery(query);
while (rs.next()) {
if (...) {
double increase = ...;
double price = rs.getDouble("Price");
rs.updateDouble("Price", price + increase);
rs.updateRow(); // make sure to call updateRow after updating fields
}
}所有对应于 SQL 类型的数据类型都配有 updateXxx 方法,比如 updateDouble、updateString 等。与 getXxx 方法相同,在使用 updateXxx 方法时必须指定列的名称或序号,然后给该字段设置新的值。
updateXxx 方法改变的只是结果集中的行值,而非数据库中的值。当更新完行中的字段值后,必须调用 updateRow 方法,这个方法将当前行中的所有更新信息发送给数据库。如果没有调用 updateRow 方法就将游标移动到其他行上,那么对此行所做的所有更新都将被丢弃,而且永远也不会被传递给数据库。还可以调用 cancelRowUpdates 方法来取消对当前行的更新。
我们在前面的例子中已经介绍过如何修改一个现有的行。如果想在数据库中添加一条新的记录,首先需要使用 moveToInsertRow 方法将游标移动到特定的位置,我们称之为插入行(insert row)。然后,调用 updateXxx 方法在插入行的位置上创建一个新的行。在上述操作全部完成之后,还需要调用 insertRow 方法将新建的行发送给数据库。完成插入操作后,再调用 moveToCurrentRow 方法将游标移回到调用 moveToInsertRow 方法之前的位置。下面是一段示例程序:
Java
rs.moveToInsertRow();
rs.updateString("Title", title);
rs.updateString("ISBN", isbn);
rs.updateString("Publisher_Id", pubid);
rs.updateDouble("Price", price);
rs.insertRow();
rs.moveToCurrentRow();Note:请注意,你无法控制在结果集或数据库中添加新数据的位置。
对于在插入行中没有指定值的列,将被设置为 SQL 的 NULL。但是,如果这个列有 NOT NULL 约束,那么将会抛出异常,而这一行也无法插入。
最后需要说明的是,你可以使用以下方法删除游标所指的行。
Java
rs.deleteRow();deleteRow 方法会立即将该行从结果集和数据库中删除。
ResultSet 接口中的 updateRow、insertRow 和 deleteRow 方法的执行效果等同于 SQL 命令中的 UPDATE、INSERT 和 DELETE。不过,习惯于 Java 编程语言的程序员通常会觉得使用结果集来操控数据库要比使用 SQL 语句自然得多。
Note:如果不小心处理的话,就很有可能在使用可更新的结果集时编写出非常低效的代码。执行
UPDATE语句,要比建立一个查询,然后一边遍历一边修改数据显得高效得多。对于用户能够任意修改数据的交互式程序来说,使用可更新的结果集是非常有意义的。但是相对于大多数通过程序进行修改的情况,使用 SQL 的UPDATE语句更合适一些。
Tip:JDBC 2 对结果集做了进一步的改进,例如,如果数据被其他的并发数据库连接所修改,那么它可以用最新的数据来更新结果集。JDBC 3 添加了另一种优化,可以指定结果集在事务提交时的行为。但是,这些高级特性超出了本文的范围。可以参考 Maydene Fisher、Jon Ellis 和 Jonathan Bruce 所著的《JDBC API Tutorial and Reference, Third Edition(Addison-Wesley 出版社 2003 年出版)》和 JDBC 规范,以了解更多的信息。
5. 行集
可滚动的结果集虽然功能强大,却有一个重要的缺陷:在与用户的整个交互过程中,必须始终与数据库保持连接。用户也许会离开电脑旁很长一段时间,而在此期间却始终占有着数据库连接。这种方式存在很大的问题,因为数据库连接属于稀有资源。在这种情况下,我们可以使用行集。RowSet 接口扩展自 ResultSet 接口,却无须始终保持与数据库的连接。
行集还适用于将查询结果移动到复杂应用的其他层,或者是诸如手机之类的其他设备中。你可能永远都不会考虑移动一个结果集,因为它的数据结构可能非常庞大,且依赖于数据库连接。
5.1. 构建行集
以下为 javax.sql.rowset 包提供的接口,它们都扩展了 RowSet 接口:
CachedRowSet允许在断开连接的状态下执行相关操作,我们将在被缓存的行集中对其进行讨论。WebRowSet对象代表了一个被缓存的行集,该行集可以保存为 XML 文件。该文件可以移动到 Web 应用的其他层中,只要在该层中使用另一个WebRowSet对象重新打开该文件即可。FilteredRowSet和JoinRowSet接口支持对行集的轻量级操作,它们等同于 SQL 中的SELECT和JOIN操作。这两个接口的操作对象是存储在行集中的数据,因此运行时无须建立数据库连接。JdbcRowSet是ResultSet接口的一个瘦包装器。它在RowSet接口中添加了一些有用的方法。
在 Java 7 中,有一种获取行集的标准方式:
Java
RowSetFactory factory = RowSetProvider.newFactory();
CachedRowSet crs = factory.createCachedRowSet();获取其他行集类型的对象也有类似的方法。
5.2. 被缓存的行集
一个被缓存的行集中包含了一个结果集中所有的数据。CachedRowSet 是 ResultSet 接口的子接口,所以你完全可以像使用结果集一样来使用被缓存的行集。被缓存的行集有一个非常重要的优点:断开数据库连接后仍然可以使用行集。你将在下方的示例程序中看到,这种做法大大简化了交互式应用的实现。在执行每个用户命令时,我们只需打开数据库连接、执行查询操作、将查询结果放入被缓存的行集,然后关闭数据库连接即可。
我们甚至可以修改被缓存的行集中的数据。当然,这些修改不会立即反馈到数据库中。相反,必须发起一个显式的请求,以便让数据库真正接受所有修改。此时 CachedRowSet 类会重新连接到数据库,并通过执行 SQL 语句向数据库中写入所有修改后的数据。
可以使用一个结果集来填充 CachedRowSet 对象:
Java
ResultSet result = ...;
RowSetFactory factory = RowSetProvider.newFactory();
CachedRowSet crs = factory.createCachedRowSet();
crs.populate(result);
conn.close(); // now OK to close the database connection或者,也可以让对象自动建立一个数据库连接。首先,设置数据库参数:
Java
crs.setURL("jdbc:derby://localhost:1527/COREJAVA");
crs.setUsername("dbuser");
crs.setPassword("secret");然后,设置查询语句和所有参数:
Java
crs.setCommand("SELECT * FROM Books WHERE Publisher_ID = ?");
crs.setString(1, publisherId);最后,将查询结果填充到行集中:
Java
crs.execute();这个方法调用会建立数据库连接、执行查询操作、填充行集,最后断开连接。
如果查询结果非常大,那我们肯定不想将其全部放入行集中。毕竟,用户可能只是想浏览其中的几行而已。在这种情况下,可以指定每一页的尺寸:
Java
CachedRowSet crs = ...;
crs.setCommand(command);
crs.setPageSize(20);
...
crs.execute();现在就能只获得 20 行了。要获取下一批数据,可以调用:
Java
crs.nextPage();可以使用与结果集中相同的方法来查看和修改行集中的数据。如果修改了行集中的内容,那么必须调用以下方法将修改写回到数据库中:
Java
crs.acceptChanges(conn);
// or
crs.acceptChanges();只有在行集中设置了连接数据库所需的信息(如 URL、用户名和密码)时,上述第二个方法调用才会有效。
在可更新的结果集小节中,我们曾经介绍过,并非所有的结果集都是可更新的。同样,如果一个行集包含的是复杂查询的查询结果,那么我们就无法将对该行集数据的修改写回到数据库中。不过,如果行集上的数据都来自同一张数据库表,我们就可以安全地写回数据。
Tip:如果是使用结果集来填充行集,那么行集就无从获知需要更新数据的数据库表名。此时,必须调用
setTable方法来设置表名称。
另一个导致问题复杂化的情况是:在填充了行集之后,数据库中的数据发生了改变,这显然容易产生数据不一致性。为了解决这个问题,参考实现会首先检查行集中的原始值(即,修改前的值)是否与数据库中的当前值一致。如果一致,那么修改后的值将覆盖数据库中的当前值。否则,将抛出 SyncProviderException 异常,且不向数据库写回任何值。在实现行集接口时其他实现也可以采用不同的同步策略。
6. 元数据
其实,JDBC 还可以提供关于数据库及其表结构的详细信息。例如,可以获取某个数据库的所有表的列表,也可以获得某个表中所有列的名称及其数据类型。如果是在开发业务应用时使用事先定义好的数据库,那么数据库结构和表信息就不是非常有用了。毕竟,在设计数据库表时,就已经知道了它们的结构。但是,对于那些编写数据库工具的程序员来说,数据库的结构信息却是极其有用的。
在 SQL 中,描述数据库或其组成部分的数据称为元数据(区别于那些存在数据库中的实际数据)。我们可以获得三类元数据:关于数据库的元数据、关于结果集的元数据以及关于预备语句参数的元数据。
如果要了解数据库的更多信息,可以从数据库连接中获取一个 DatabaseMetaData 对象:
Java
DatabaseMetaData meta = conn.getMetaData();现在就可以获取某些元数据了。例如,调用
Java
ResultSet mrs = meta.getTables(null, null, null, new String[] { "TABLE" });将返回一个包含所有数据库表信息的结果集。该结果集中的每一行都包含了数据库中一张表的详细信息,其中,第三列是表的名称。下面的循环可以获取所有的表名:
Java
while (mrs.next())
tableNames.addItem(mrs.getString(3));Note
DatabaseMetaData的getTables方法定义如下:JavaResultSet getTables(String catalog, String schemaPattern, String tableNamePattern, String types[])返回某个目录(catalog)中所有表的描述,该目录必须匹配给定的模式(schema)、表名字模式以及类型标准。模式用于描述一组相关的表和访问权限,而目录描述的是一组相关的模式,这些概念对组织大型数据库非常重要。
catalog和schemaPattern参数可以为"",用于检索那些没有目录或模式的表。如果不想考虑目录和模式,也可以将上述参数设为null。
types数组包含了所需的表类型的名称,通常表类型有TABLE、VIEW、SYSTEM TABLE、GLOBAL TEMPORARY、LOCAL TEMPORARY、ALIAS和SYNONYM。如果types为null,则返回所有类型的表。返回的结果集共有 5 列,均为String类型。
序号 名称 解释 1 TABLE_CAT表目录(可以为 null)2 TABLE_SCHEM表模式(可以为 null)3 TABLE_NAME表名称 4 TABLE_TYPE表类型 5 REMARKS关于表的注释
数据库元数据还有第二个重要应用。数据库是非常复杂的,SQL 标准为数据库的多样性提供了很大的空间。DatabaseMetaData 接口中有上百个方法可以用于查询数据库的相关信息,包括一些使用奇特的名字进行调用的方法,如:
Java
meta.supportsCatalogsInPrivilegeDefinitions()和
Java
meta.nullPlusNonNullIsNull()显然,这些方法主要是针对有特殊要求的高级用户的,尤其是那些需要编写涉及多个数据库且具有高可移植性的代码的编程人员。
DatabaseMetaData 接口用于提供有关数据库的数据,第二个元数据接口 ResultSetMetaData 则用于提供结果集的相关信息。每当通过查询得到一个结果集时,我们都可以获取该结果集的列数以及每一列的名称、类型和字段宽度。下面是一个典型的循环:
Java
ResultSet rs = stat.executeQuery("SELECT * FROM " + tableName);
ResultSetMetaData meta = rs.getMetaData();
for (int i = 1; i <= meta.getColumnCount(); i++) {
String columnName = meta.getColumnLabel(i);
int columnWidth = meta.getColumnDisplaySize(i);
...
}7. 事务
7.1. 用 JDBC 对事务编程
默认情况下,数据库连接处于自动提交模式(autocommit mode),即每个 SQL 语句一旦被执行便被提交给数据库。一旦命令被提交,就无法对它进行回滚操作。在使用事务时,需要关闭这个默认值:
Java
conn.setAutoCommit(false);现在可以按照通常的方式创建一个语句对象:
Java
Statement stat = conn.createStatement();然后任意多次地调用 executeUpdate 方法:
Java
stat.executeUpdate(command);
stat.executeUpdate(command);
stat.executeUpdate(command);如果执行了所有命令之后没有出错,则调用 commit 方法:
Java
conn.commit();如果出现错误,则调用:
Java
conn.rollback();此时,程序将自动撤销自上次提交以来的所有语句。当事务被 SQLException 异常中断时,典型的办法就是发起回滚操作。
7.2. 保存点
在使用某些驱动程序时,使用保存点(save points)可以更细粒度地控制回滚操作。创建一个保存点意味着稍后只需返回到这个点,而非放弃整个事务。例如:
Java
Statement stat = conn.createStatement(); // start transaction; rollback() goes here
stat.executeUpdate(command1);
Savepoint svpt = conn.setSavepoint(); // set savepoint; rollback(svpt) goes here
stat.executeUpdate(command2);
if (...) conn.rollback(svpt); // undo effect of command2
...
conn.commit();当不再需要保存点时,应该释放它:
Java
conn.releaseSavepoint(svpt);7.3. 批量更新
假设有一个程序需要执行许多 INSERT 语句,以便将数据填入数据库表中,此时可以使用批量更新的方法来提高程序性能。在使用批量更新(batch update)时,一个语句序列作为一批操作将同时被收集和提交。
Note:使用
DatabaseMetaData接口中的supportsBatchUpdates方法可以获知数据库是否支持这种特性。
处于同一批中的语句可以是 INSERT、UPDATE 或 DELETE 等操作,也可以是数据库定义语句,如 CREATE TABLE 或 DROP TABLE。但是,在批量处理中添加 SELECT 语句会抛出异常(从概念上讲,批量处理中的 SELECT 语句没有意义,因为它会返回结果集,而并不更新数据库)。
为了执行批量处理,首先必须使用通常的办法创建一个 Statement 对象:
Java
Statement stat = conn.createStatement();现在,应该调用 addBatch 方法,而非 executeUpdate 方法:
Java
String command = "CREATE TABLE ..."
stat.addBatch(command);
while (...) {
command = "INSERT INTO ... VALUES (" + ... + ")";
stat.addBatch(command);
}最后,提交整个批量更新语句:
Java
int[] counts = stat.executeBatch();调用 executeBatch 方法将为所有已提交的语句返回一个记录数的数组。
为了在批量模式下正确地处理错误,必须将批量执行的操作视为单个事务。如果批量更新在执行过程中失败,那么必须将它回滚到批量操作开始之前的状态。
首先,关闭自动提交模式,然后收集批量操作,执行并提交该操作,最后恢复最初的自动提交模式:
Java
boolean autoCommit = conn.getAutoCommit();
conn.setAutoCommit(false);
Statement stat = conn.createStatement();
...
// keep calling stat.addBatch(...);
...
stat.executeBatch();
conn.commit();
conn.setAutoCommit(autoCommit);7.4. 高级 SQL 类型
表 7.1 列举了 JDBC 支持的 SQL 数据类型以及它们在 Java 语言中对应的数据类型。
| SQL 数据类型 | Java 数据类型 |
|---|---|
INTEGER, INT | int |
SMALLINT | short |
NUMERIC(m, n), DECIMAL(m, n), DEC(m, n) | java.math.BigDecimal |
FLOAT(n) | double |
REAL | float |
DOUBLE | double |
CHARACTER(n), CHAR(n) | String |
VARCHAR(n), LONG VARCHAR | String |
BOOLEAN | boolean |
DATE | java.sql.Date |
TIME | java.sql.Time |
TIMESTAMP | java.sql.Timestamp |
BLOB | java.sql.Blob |
CLOB | java.sql.Clob |
ARRAY | java.sql.Array |
ROWID | java.sql.RowId |
NCHAR(n), NVARCHAR(n), LONG NVARCHAR | String |
NCLOB | java.sql.NClob |
SQLXML | java.sql.SQLXML |
从数据库中获得一个 LOB 或数组并不等于获取了它的实际内容,只有在访问具体的值时它们才会从数据库中被读取出来。这对改善性能非常有好处,因为通常这些数据的数据量都非常大。
8. Web 与企业应用中的连接管理
使用 database.properties 文件可以对数据库连接进行非常简单的设置。这种方法适用于小型的测试程序,但是不适用于规模较大的应用。当将一个 JDBC 应用程序部署在 Web 或企业环境中时,数据库连接的管理与 JNDI 集成在一起。整个企业的数据源属性可以存储在一个目录中。使用目录可以实现对用户名、密码、数据库名称和 JDBC URL 的集中管理。在这样的环境中,可以使用下列代码创建数据库连接:
Java
var jndiContext = new InitialContext();
var source = (DataSource) jndiContext.lookup("java:comp/env/jdbc/corejava");
Connection conn = source.getConnection();请注意,我们不再使用 DriverManager,而是使用 JNDI 服务来定位数据源。数据源是一个能够提供简单的 JDBC 连接和更多高级服务的接口,比如执行涉及多个数据库的分布式事务。javax.sql 标准扩展包定义了 DataSource 接口。
Note
在 Java EE 的容器中,甚至不必编程进行 JNDI 查找,只需在
DataSource域上使用Resource注解,当加载应用时,这个数据源引用将被设置:Java@Resource(name="jdbc/corejava") private DataSource source;
当然,我们必须在某个地方配置数据源。如果你编写的数据库程序将在 Servlet 容器中运行,比如 Apache Tomcat,或在应用服务器中运行,比如 GlassFish,那么必须将数据库配置信息(包括 JNDI 名字、JDBC URL、用户名和密码)放置在配置文件中,或者在管理员 GUI 中进行设置。
用户名管理和登录管理只是众多需要特别关注的问题之一。另一个重要问题则涉及建立数据库连接所需的开销。不论是在开头建立了到数据库的单个连接,并在程序结尾处关闭它,还是在每次需要时都打开一个新连接。这两种方式都不令人满意:因为数据库连接是有限的资源,如果用户要离开应用一段时间,那么他占用的连接就不应该保持打开状态;另一方面,每次查询都获取连接并在随后关闭它的代价也是相当高的。
解决上述问题的方法是建立数据库连接池(pool)。这意味着数据库连接在物理上并未被关闭,而是保留在一个队列中并被反复重用。连接池是一种非常重要的服务,JDBC 规范为实现者提供了用以实现连接池服务的手段。不过,JDK 本身并未实现这项服务,数据库供应商提供的 JDBC 驱动程序中通常也不包含这项服务。相反,Web 容器和应用服务器的开发商通常会提供连接池服务的实现。
连接池的使用对程序员来说是完全透明的,可以通过获取数据源并调用 getConnection 方法来得到连接池中的连接。使用完连接后,需要调用 close 方法。该方法并不会在物理上关闭连接,而只是告诉连接池已经使用完该连接。连接池通常还会将池机制作用于预备语句上。