Appearance
Spring In Action 6th:处理非关系型数据
Spring Data 已经为许多 NoSQL 数据库提供了支持,包括 MongoDB、Cassandra、Couchbase、Neo4j、Redis 等等。而且,不管你选择哪个数据库,编程模型几乎是相同的。
在本章中,我们将以两个流行的 NoSQL 数据库为例 Cassandra 和 MongoDB 对其展开介绍。
1. 使用 Cassandra Repository
Cassandra 是一个分布式、高性能、始终可用、最终一致、分区列存储的 NoSQL 数据库。简单来说,Cassandra 处理写入表格的数据行,这些表格在一个到多个分布式节点上进行分区。没有单个节点携带所有数据,但任何给定的行可能在多个节点上复制,从而消除了任何单点故障。
Spring Data Cassandra 提供了对 Cassandra 数据库的自动 Repository 支持,这与 Spring Data JPA 为关系数据库提供的支持非常相似,但又有很大的不同。此外,Spring Data Cassandra 提供了用于将应用程序域类型映射到支持的数据库结构的注解。
在进一步探讨 Cassandra 之前,必须始终牢记一点,尽管 Cassandra 与关系数据库(如 Oracle 和 SQL Server)共享许多类似的概念,但 Cassandra 不是一个关系数据库,在许多方面都是一种完全不同的东西。我将解释 Cassandra 在与 Spring Data 一起工作时的特殊之处。但我鼓励你阅读 Cassandra 的官方文档,以深入了解它的运作方式。
1.1. 启用 Spring Data Cassandra
要开始使用 Spring Data Cassandra,你需要添加非响应式 Spring Data Cassandra 的 Spring Boot starter 依赖项。实际上,有两个单独的 Spring Data Cassandra starter 依赖项可供选择:一个用于响应式数据持久化,另一个用于标准的、非响应式的持久化。
我们将在后续更详细地讨论编写响应式仓库。但目前,我们将在构建中使用非响应式的 starter,如下所示:
XML
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-cassandra</artifactId>
</dependency>该依赖项取代了我们在《Spring In Action 6th:处理数据》中使用的 Spring Data JPA 或 Spring Data JDBC 依赖项。与使用 JPA 或 JDBC 将 Taco Cloud 数据持久化到关系数据库不同,你将使用 Spring Data 将数据持久化到 Cassandra 数据库。因此,你需要从构建中删除 Spring Data JPA 或 Spring Data JDBC 依赖项以及任何关系数据库依赖项(如 JDBC 驱动程序或 H2 依赖项)。
Spring Data Cassandra starter 依赖项将一些依赖项引入项目,具体来说,引入了 Spring Data Cassandra 库。由于 Spring Data Cassandra 在运行时类路径中,会触发用于创建 Cassandra 仓库的自动配置。这意味着你可以开始编写 Cassandra 仓库,而无需进行太多显式配置。
Cassandra 作为一个节点集群运行,共同作为一个完整的数据库系统。如果你还没有要使用的 Cassandra 集群,你可以使用 Docker 启动一个用于开发目的的单节点集群,如下所示:
Bash
$ docker network create cassandra-netBash
$ docker run --name my-cassandra \
--network cassandra-net \
-p 9042:9042 \
-d cassandra:latest这将启动单节点集群,并在主机上暴露节点的端口(9042),以便你的应用程序可以访问它。
然而,你仍然需要提供一些配置。至少,你需要配置一个键空间的名称,该键空间是你的仓库将在其中操作的区域。为此,你首先需要创建这样一个键空间。
Note:在 Cassandra 中,键空间是 Cassandra 节点中表的分组。它大致类似于关系数据库中的一个库。
虽然可以配置 Spring Data Cassandra 自动创建键空间,但通常手动创建它(或使用现有的键空间)会更容易。使用 Cassandra CQL(Cassandra 查询语言)shell,你可以为 Taco Cloud 应用程序创建一个键空间。你可以使用 Docker 命令 docker run -it --network cassandra-net --rm cassandra cqlsh my-cassandra 启动 CQL shell,如下所示:
Bash
$ docker run -it --network cassandra-net --rm cassandra cqlsh my-cassandra
Connected to Test Cluster at my-cassandra:9042
[cqlsh 6.1.0 | Cassandra 4.1.3 | CQL spec 3.4.6 | Native protocol v5]
Use HELP for help.
cqlsh>Note:如果此命令启动 CQL shell 失败,并显示 “Unable to connect to any servers” 的错误,请等待一两分钟,然后重试。在 CQL shell 能够连接到 Cassandra 集群之前,你需要确保 Cassandra 集群已完全启动。
当 shell 准备好后,使用以下命令创建键空间:
Bash
cqlsh> create keyspace tacocloud
... with replication={'class':'SimpleStrategy', 'replication_factor':1}
... and durable_writes=true;简而言之,这将创建一个名为 tacocloud 的键空间,具有简单的复制和持久化写入。通过将复制因子设置为 1,你要求 Cassandra 保留每行的一个副本。复制策略决定了复制的处理方式。SimpleStrategy 复制策略适用于单个数据中心的使用(以及演示代码),但如果你的 Cassandra 集群跨多个数据中心,你可能要考虑 NetworkTopologyStrategy。我建议你查阅 Cassandra 文档,以了解复制策略的工作原理和创建键空间的其他替代方法的详细信息。
现在你已经创建了一个键空间,需要配置 spring.data.cassandra.keyspace-name 属性,告诉 Spring Data Cassandra 使用该键空间,如下所示:
YAML
spring:
data:
cassandra:
keyspace-name: tacocloud
schema-action: recreate
local-datacenter: datacenter1在这里,你还将 spring.data.cassandra.schema-action 设置为 recreate。这个设置在开发过程中非常有用,因为它确保每次应用程序启动时都会删除并重新创建任何表和用户定义的类型。默认值 none 对架构不采取任何操作,在生产设置中很有用,因为你可能不希望每次应用程序启动时都删除所有表。
最后,spring.data.cassandra.local-datacenter 属性用于标识本地数据中心的名称,以设置 Cassandra 的负载平衡策略。在单节点设置中,datacenter1 是要使用的值。有关 Cassandra 负载平衡策略以及如何设置本地数据中心的更多信息,请参阅 DataStax Cassandra 驱动程序的参考文档。
这些是在本地运行的 Cassandra 数据库中工作所需的唯一属性。除了这两个属性之外,根据你配置 Cassandra 集群的方式,你可能还希望设置其他属性。
默认情况下,Spring Data Cassandra 假定 Cassandra 在本地运行,并在端口 9042 上进行监听。如果不是这种情况,例如在生产设置中,你可能希望设置 spring.data.cassandra.contact-points 和 spring.data.cassandra.port 属性,如下所示:
YAML
spring:
data:
cassandra:
...
contact-points:
- casshost-1.tacocloud.com
- casshost-2.tacocloud.com
- casshost-3.tacocloud.com
port: 9042请注意,spring.data.cassandra.contact-points 属性是你标识 Cassandra 主机名的地方。联系点是运行 Cassandra 节点的主机。默认情况下,它设置为 localhost,但你可以将其设置为主机名列表。它将尝试每个联系点,直到能够连接到一个。这是为了确保 Cassandra 集群中没有单一故障点,并且应用程序将能够通过给定的联系点之一与集群连接。
你可能还需要为 Cassandra 集群指定用户名和密码。可以通过设置 spring.data.cassandra.username 和 spring.data.cassandra.password 属性来实现,如下所示:
YAML
spring:
data:
cassandra:
...
username: tacocloud
password: s3cr3tP455w0rd这些是在本地运行的 Cassandra 数据库中工作所需的唯一属性。除了这两个属性之外,根据你配置 Cassandra 集群的方式,你可能还希望设置其他属性。
现在,Spring Data Cassandra 已经在项目中启用并配置好了,你几乎可以开始将领域类型映射到 Cassandra 表并编写仓库了。但首先,让我们退后一步,考虑一下 Cassandra 数据建模的一些基本要点。
1.2. 理解 Cassandra 数据模型
正如我之前提到的,Cassandra 与关系数据库相差甚远。在你开始将领域类型映射到 Cassandra 表之前,了解一下 Cassandra 数据建模与在关系数据库中持久化数据的方式有一些不同是很重要的。
以下是关于 Cassandra 数据建模的一些最重要的事项:
Cassandra 表可以有任意数量的列,但不一定所有行都会使用所有这些列;
Cassandra 数据库分布在多个分区中。给定表中的任何行都可能由一个或多个分区管理,但不太可能所有分区都包含所有行;
Cassandra 表有两种键:分区键和聚簇键。对每行的分区键执行哈希操作,以确定该行将由哪个分区(或多个分区)管理。聚簇键确定在分区内维护行的顺序(不一定是查询结果中它们可能出现的顺序)。有关 Cassandra 数据建模的更详细解释,包括分区、簇和它们各自的键,请参阅 Cassandra 文档;
Cassandra 对读操作进行了高度优化。因此,对于高度反规范化的表和跨多个表复制的数据来说,这是很常见和可取的(例如,客户信息可能存储在客户表中,并在包含客户下订单的表中重复);
总之,将 Taco Cloud 中的实体类型适配成以 Cassandra 存储,不只是简单地把几个 JPA 注解替换成 Cassandra 注解的问题。您需要考虑如何对实体数据进行重新建模。
1.3. Cassandra 持久化实体映射
在之前的代码中使用了 JPA 规范提供的注解标记了领域类型(Taco、Ingredient、TacoOrder 等)。这些注解将你的领域类型映射为要持久化到关系数据库的实体。虽然这些注解对于 Cassandra 持久性是行不通的,但 Spring Data Cassandra 提供了其自己的一套映射注解,用于类似的目的。
让我们从 Ingredient 类开始,因为它对于 Cassandra 映射来说最简单。新的适用于 Cassandra 的 Ingredient 类如下所示:
Java
package graceful.hello.spring.web.modules;
import lombok.AccessLevel;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.springframework.data.cassandra.core.mapping.PrimaryKey;
import org.springframework.data.cassandra.core.mapping.Table;
@Data
@AllArgsConstructor
@NoArgsConstructor(access = AccessLevel.PRIVATE, force = true)
@Table("ingredient")
public class Ingredient {
@PrimaryKey
private String id;
private String name;
private Type type;
public enum Type {
WRAP, PROTEIN, VEGGIES, CHEESE, SAUCE
}
}Ingredient 类似乎与我关于只需交换一些注解的说法相矛盾。与为 JPA 持久性所做的 @Entity 注解不同,它使用 @Table 注解来表示应将 ingredients 持久化到名为 ingredients 的表中。而且不是用 @Id 注解 id 属性,这一次它用 @PrimaryKey 进行了注解。到目前为止,似乎你只是在交换一些注解。
但是不要被 Ingredient 映射给迷惑了。Ingredient 类是你最简单的域类型之一。当你为 Cassandra 持久性映射 Taco 类时,事情会变得更有趣,如下面的示例所示:
Java
@Data
@Table("tacos")
public class Taco {
@PrimaryKeyColumn(type = PrimaryKeyType.PARTITIONED)
private UUID id = Uuids.timeBased();
@NotNull
@Size(min = 5, message = "Name must be at least 5 characters long")
private String name;
@PrimaryKeyColumn(type = PrimaryKeyType.CLUSTERED, ordering = Ordering.DESCENDING)
private Date createdAt = new Date();
@Size(min = 1, message = "You must choose at least 1 ingredient")
@Column("ingredients")
private List<IngredientUDT> ingredients = new ArrayList<>();
public void addIngredient(Ingredient ingredient) {
this.ingredients.add(TacoUDRUtils.toIngredientUDT(ingredient));
}
}如你所见,映射 Taco 类要复杂一些。与 Ingredient 类似,@Table 注解用于标识 tacos 作为应该写入的表的名称。但这是与 Ingredient 相似的唯一部分。
id 属性仍然是主键,但它是两个主键列中的一个。更具体地说,id 属性使用 @PrimaryKeyColumn 进行注解,其类型为 PrimaryKeyType.PARTITIONED。这指定 id 属性作为分区键,用于确定每行 taco 数据将写入哪个 Cassandra 分区。
你还会注意到,id 属性现在是 UUID,而不是 Long。虽然不是必需的,但通常用于保存生成的 ID 值的属性的类型是 UUID。此外,UUID 使用基于时间的值初始化,用于新的 Taco 对象(但在从数据库中读取现有 Taco 时可能被覆盖)。
稍微往下看,你会看到 createdAt 属性,它被映射为另一列主键。但在这种情况下,@PrimaryKeyColumn 的 type 属性设置为 PrimaryKeyType.CLUSTERED,这将 createdAt 属性指定为聚簇键。如前所述,聚簇键用于确定分区内行的排序。更具体地说,排序设置为降序 —— 因此,在给定分区中,较新的行首先出现在 tacos 表中。
最后,ingredients 属性现在是 IngredientUDT 对象的列表,而不是 Ingredient 对象的列表。正如你记得的那样,Cassandra 表高度去规范化,可能包含从其他表复制的数据。尽管 ingredients 表将作为所有可用 ingredient 的记录表,但每个 taco 的 ingredient 会在 ingredients 中重复出现。而不仅仅是引用 Ingredient 表中的一个或多个行,ingredients 属性将包含每个选择的成分的完整数据。
但为什么需要引入一个新的 IngredientUDT 类呢?为什么不能简单地重用 Ingredient 类?简而言之,包含数据集合的列(例如 ingredients 列)必须是基本类型(整数、字符串等)或用户定义的类型的集合。
在 Cassandra 中,用户定义的类型使您能够声明比简单基本类型更丰富的表列。它们通常被用作关系外键的非规范化模拟。与仅保存对另一张表中行的引用的外键不同,具有用户定义类型的列实际上携带可能从另一张表中的行复制过来的数据。对于 tacos 表的 ingredients 列,它将包含定义成分本身的数据结构的集合。
你不能将 Ingredient 类用作用户定义的类型,因为 @Table 注解已经将其映射为 Cassandra 中持久性的实体。因此,你必须创建一个新类来定义成分将如何存储在 taco 表的 ingredients 列中。IngredientUDT(其中 UDT 意味着用户定义的类型)正是这项工作的类,如下所示:
Java
package graceful.hello.spring.web.udts;
import graceful.hello.spring.web.modules.Ingredient;
import lombok.AccessLevel;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.RequiredArgsConstructor;
import org.springframework.data.cassandra.core.mapping.UserDefinedType;
@Data
@RequiredArgsConstructor
@NoArgsConstructor(access = AccessLevel.PRIVATE, force = true)
@UserDefinedType("ingredient")
public class IngredientUDT {
private final String name;
private final Ingredient.Type type;
}虽然 IngredientUDT 看起来很像 Ingredient,但它的映射要求要简单得多。它用 @UserDefinedType 进行注解,以在 Cassandra 中标识它为用户定义的类型。但除此之外,它是一个简单的类,具有一些属性。
你还会注意到 IngredientUDT 类不包括 id 属性。虽然它可以包含源 Ingredient 的 id 属性的副本,但这并不是必需的。实际上,用户定义的类型可以包含任何你希望的属性 —— 它不需要与任何表定义进行一对一的映射。
意识到你现在可能没有一个清晰的完整视图,来理解用户自定义类型中的数据是如何关联,并持久化到库中的。图 1.1 显示了整个 Taco Cloud 的数据模型,包括用户自定义的类型:
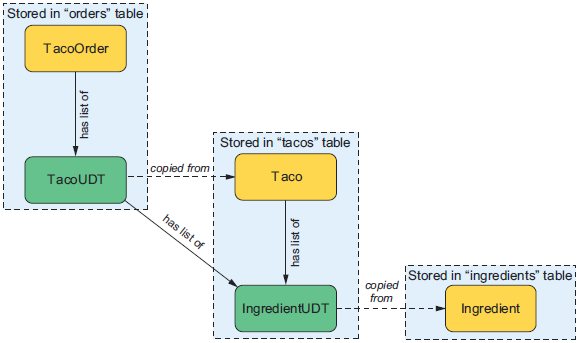
针对你刚刚创建的用户定义类型,注意 Taco 具有一个 IngredientUDT 对象的列表,该列表包含从 Ingredient 对象复制的数据。当持久化 Taco 时,将 Taco 对象和 IngredientUDT 对象的列表持久化到 tacos 表中。IngredientUDT 对象的列表完全存储在 ingredients 列中。
另一种看待这个问题的方式可能有助于你理解用户定义类型的使用,那就是查询来自 tacos 表的行。使用 CQL 和随 Cassandra 附带的 cqlsh 工具,你会看到以下结果:
Bash
$ cqlsh:tacocloud> select id, name, createdAt, ingredients from tacos;
id | name | createdat | ingredients
---------+-----------+-----------+----------------------------------------
827390...| Carnivore | 2018-04...| [{name: 'Flour Tortilla', type: 'WRAP'},
{name: 'Carnitas', type: 'PROTEIN'},
{name: 'Sour Cream', type: 'SAUCE'},
{name: 'Salsa', type: 'SAUCE'},
{name: 'Cheddar', type: 'CHEESE'}]
(1 rows)正如你所看到的,id、name 和 createdat 列包含简单的值。在这方面,它们与对关系数据库进行类似查询时所期望的并没有太大的不同。但 ingredients 列有点不同。因为它被定义为包含用户定义的成分类型(由 IngredientUDT 定义),其值显示为一个填充有 JSON 对象的 JSON 数组。
你可能在图 1.1 中注意到了其他用户定义的类型。随着你继续将领域映射到 Cassandra 表,你肯定会创建一些其他的用户定义类型,其中包括一些将被 TacoOrder 类使用的类型。下面的示例展示了已修改为支持 Cassandra 持久性的 TacoOrder 类:
Java
@Data
@Table("orders")
public class TacoOrder implements Serializable {
private static final long serialVersionUID = 1L;
@PrimaryKey
private UUID id = Uuids.timeBased();
private Date placedAt = new Date();
...
@Column("tacos")
private List<TacoUDT> tacos = new ArrayList<>();
public void addTaco(TacoUDT taco) {
this.tacos.add(taco);
}
}@Table 用于将 TacoOrder 映射到 orders 表,与之前使用 @Table 的方式相同。在这种情况下,你不关心排序,因此 id 属性只是用 @PrimaryKey 进行注解,将其指定为分区键和具有默认排序的聚簇键。
Tacos 属性有一些有趣之处,因为它是 List<TacoUDT>,而不是 Taco 对象的列表。TacoOrder 和 Taco/TacoUDT 之间的关系在这里类似于 Taco 和 Ingredient/IngredientUDT 之间的关系。也就是说,与通过外键连接来自其他表的几行数据不同,orders 表将包含所有相关 taco 数据,以优化表的读取速度。
TacoUDT 类与 IngredientUDT 类非常相似,尽管它确实包含一个引用另一个用户定义类型的集合,如下所示:
Java
package graceful.hello.spring.web.udts;
import lombok.Data;
import org.springframework.data.cassandra.core.mapping.UserDefinedType;
import java.util.List;
@Data
@UserDefinedType("taco")
public class TacoUDT {
private final String name;
private final List<IngredientUDT> ingredients;
}1.4. 编写 Cassandra Repository
使用 Spring Data 编写存储库只涉及声明一个接口,该接口扩展 Spring Data 的基本存储库接口之一,并可选择声明额外的查询方法以进行自定义查询。事实证明,编写 Cassandra 存储库并没有太大的区别。
事实上,在我们已经编写的 Repository 几乎不需要更改,就可以适配 Cassandra 持久化。例如 IngedientRepository:
Java
package graceful.hello.spring.web.data;
import graceful.hello.spring.web.modules.Ingredient;
import org.springframework.data.repository.CrudRepository;
public interface IngredientRepository
extends CrudRepository<Ingredient, String> {
}通过扩展 CrudRepository,如上所示,IngredientRepository 已准备好持久化 Ingredient 对象,其 ID 属性(对于 Cassandra 来说是主键属性)为 String。太完美了!不需要对 IngredientRepository 进行任何更改。
对于 OrderRepository 所需的更改只稍微复杂一些。在扩展 CrudRepository 时,ID 参数类型将从 Long 更改为 UUID,如下所示:
Java
package graceful.hello.spring.web.data;
import graceful.hello.spring.web.modules.TacoOrder;
import org.springframework.data.repository.CrudRepository;
import java.util.UUID;
public interface OrderRepository
extends CrudRepository<TacoOrder, UUID> {
}2. 编写 MongoDB Repository
2.1. 启用 Spring Data MongoDB
要开始使用 Spring Data MongoDB,你需要将 Spring Data MongoDB 启动器添加到项目构建中。与 Spring Data Cassandra 一样,Spring Data MongoDB 有两个单独的启动器可供选择:一个是响应式的,一个是非响应式的。我们将在后续介绍持久性的响应式选项。现在,将以下依赖项添加到构建中,以使用非响应式的 MongoDB 启动器:
XML
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
</dependency>启动 MongoDB 服务器的一个简单方法是使用以下命令行:
Bash
$ docker run -p 27017:27017 -d mongo:latest但是,为了方便测试或开发,你可以选择使用嵌入式的 Mongo 数据库。要做到这一点,将以下的 Flapdoodle 嵌入式 MongoDB 依赖项添加到你的构建中:
XML
<dependency>
<groupId>de.flapdoodle.embed</groupId>
<artifactId>de.flapdoodle.embed.mongo</artifactId>
<!-- <scope>test</scope> -->
</dependency>Flapdoodle 嵌入式数据库为你提供了所有与内存中的 Mongo 数据库一起工作的便利性,就像你在处理关系数据时使用 H2 一样。也就是说,你不需要运行一个单独的数据库,但是当你重新启动应用程序时,所有的数据都会被清除。
嵌入式数据库非常适合开发和测试,但是一旦你将应用程序投入生产,你需要确保设置一些属性,让 Spring Data MongoDB 知道你的生产 Mongo 数据库在哪里以及如何访问,如下所示:
YAML
spring:
data:
mongodb:
host: mongodb.tacocloud.com
port: 27017
username: tacocloud
password: s3cr3tp455w0rd
database: tacoclouddb并非所有的这些属性都是必需的,下面是每个属性的配置说明:
spring.data.mongodb.host:Mongo 运行的主机名(默认值:localhost);spring.data.mongodb.port:Mongo 服务器监听的端口(默认值:27017);spring.data.mongodb.username:用于访问安全的 Mongo 数据库的用户名;spring.data.mongodb.password:用于访问安全的 Mongo 数据库的密码;spring.data.mongodb.database:数据库名称(默认值:test);
现在你已经在你的项目中启用了 Spring Data MongoDB,你需要将你的领域对象注解为 MongoDB 中的文档以进行持久化。
2.2. MongoDB 持久化实体映射
Spring Data MongoDB 提供了一些有用的注解,用于将领域类型映射到要在 MongoDB 中持久化的文档结构。虽然 Spring Data MongoDB 提供了六个映射注解,但对于大多数常见的使用场景,以下四个就够用了:
@Id:将属性指定为文档 ID(来自 Spring Data Commons);@Document:声明一个领域类型为要持久化到 MongoDB 的文档;@Field:指定在持久化文档中存储属性的字段名(以及可选的顺序);@Transient:指定属性不被持久化;
在这三个注解中,只有 @Id 和 @Document 注解是严格要求的。除非你另行指定,否则没有用 @Field 或 @Transient 注解的属性将假定字段名等于属性名。
将这些注解应用到 Ingredient 类,你会得到以下结果:
Java
@Data
@AllArgsConstructor
@NoArgsConstructor(access = AccessLevel.PRIVATE, force = true)
@Document
public class Ingredient {
@Id
private String id;
private String name;
private Type type;
public enum Type {
WRAP, PROTEIN, VEGGIES, CHEESE, SAUCE
}
}如你所见,你可以在类级别放置 @Document 注解,以指示 Ingredient 是一个可以写入和读取 Mongo 数据库的文档实体。默认情况下,集合名称是基于类名的,首字母小写。因为你没有另行指定,Ingredient 对象将被持久化到一个名为 ingredient 的集合中。但你可以通过设置 @Document 的 collection 属性来改变这一点,如下所示:
Java
@Document(collection="ingredients")你也会注意到 id 属性已经被 @Id 注解标注。这将该属性指定为持久化文档的 ID。你可以在任何类型为 Serializable 的属性上使用 @Id,包括 String 和 Long。
MongoDB 的文档持久化方式非常适合在聚合根级别应用持久化的领域驱动设计方式。MongoDB 中的文档往往被定义为聚合根,聚合的成员作为子文档。
对于 Taco Cloud 来说,这意味着因为 Taco 只作为 TacoOrder-rooted 聚合的成员进行持久化,所以 Taco 类不需要被注解为 @Document,也不需要一个 @Id 属性。Taco 类可以保持清洁,不需要任何持久化注解,如下所示:
Java
@Data
public class Taco {
@NotNull
@Size(min = 5, message = "Name must be at least 5 characters long")
private String name;
private Date createdAt = new Date();
@Size(min = 1, message = "You must choose at least 1 ingredient")
private List<Ingredient> ingredients = new ArrayList<>();
public void addIngredient(Ingredient ingredient) {
this.ingredients.add(ingredient);
}
}然而,TacoOrder 类作为聚合的根,需要用 @Document 进行注解,并且需要有一个 @Id 属性,如下所示:
Java
@Data
@Document
public class TacoOrder implements Serializable {
private static final long serialVersionUID = 1L;
@Id
private String id;
private Date placedAt = new Date();
...
private List<Taco> tacos = new ArrayList<>();
public void addTaco(Taco taco) {
this.tacos.add(taco);
}
}注意到 id 属性已经被改变为 String(相对于 JPA 版本中的 Long 或 Cassandra 版本中的 UUID)。如我前面所说,@Id 可以应用于任何 Serializable 类型。但如果你选择使用 String 属性作为 ID,当它被保存时(假设它是 null),你可以得到 Mongo 自动分配值的好处。通过选择 String,你可以得到一个数据库管理的 ID 分配,并且不需要手动设置该属性。虽然有一些更高级和不寻常的用例需要额外的映射,但你会发现,在大多数情况下,@Document 和 @Id,以及偶尔的 @Field 或 @Transient,对于 MongoDB 映射来说已经足够了。
现在剩下的就是编写仓库接口了。
2.3. 编写 MongoDB Repository 接口
Spring Data MongoDB 提供了类似于 Spring Data JPA 和 Spring Data Cassandra 所提供的自动仓库支持。
你可以从定义一个用于将 Ingredient 对象持久化为文档的仓库开始。和以前一样,你可以编写 IngredientRepository 来扩展 CrudRepository,如下所示:
Java
public interface IngredientRepository
extends CrudRepository<Ingredient, String> {
}等一下!这看起来和之前为 Cassandra 编写的 IngredientRepository 接口完全一样!的确,这是同一个接口,没有任何改变。这突显了扩展 CrudRepository 的一个好处——它在各种数据库类型之间更具可移植性,对于 MongoDB 和 Cassandra 同样有效。
接下来看 OrderRepository 接口:
Java
public interface OrderRepository
extends CrudRepository<TacoOrder, String> {
}就像 IngredientRepository 一样,OrderRepository 扩展了 CrudRepository。与你到目前为止定义的其他仓库相比,这个仓库没有什么特别的地方。然而,请注意,ID 参数现在是 String,而不是 Long(如 JPA)或 UUID(如 Cassandra)。这反映了我们在 TacoOrder 中做的改变,以支持 ID 的自动分配。
总的来说,使用 Spring Data MongoDB 并不会与我们使用过的其他 Spring Data 项目有太大的不同。领域类型的注解方式不同。但除了扩展 CrudRepository 时指定的 ID 参数外,仓库接口几乎是相同的。
3. 总结
Spring Data 支持各种 NoSQL 数据库的仓库,包括 Cassandra、MongoDB、Neo4j 和 Redis;
创建仓库的编程模型在不同的底层数据库之间差异很小;
使用非关系型数据库需要理解如何适当地为数据库最终存储的数据建模;