Appearance
The Go Programming Language - 函数、方法
1. 函数
1.1. 函数声明
Go 语言没有默认参数值,也没有任何方法可以通过参数名指定形参,因此形参和返回值的变量名对于函数调用者而言没有意义。
没有函数体的函数声明,这表示该函数不是以 Go 实现的。这样的声明定义了函数标识符。
Go
package math
func Sin(x float64) float //implemented in assembly language1.2. 递归
大部分编程语言使用固定大小的函数调用栈,常见的大小从 64KB 到 2MB 不等。固定大小栈会限制递归的深度,当你用递归处理大量数据时,需要避免栈溢出;除此之外,还会导致安全性问题。与相反,Go 语言使用可变栈,栈的大小按需增加(初始时很小)。这使得我们使用递归时不必考虑溢出和安全问题。
1.3. 函数值
在 Go 中,函数被看作第一类值(first-class values):函数像其他值一样,拥有类型,可以被赋值给其他变量,传递给函数,从函数返回。
Go
func square(n int) int { return n * n }
func negative(n int) int { return -n }
func product(m, n int) int { return m * n }
f := square
fmt.Println(f(3)) // "9"
f = negative
fmt.Println(f(3)) // "-3"
fmt.Printf("%T\n", f) // "func(int) int"
f = product // compile error: can't assign func(int, int) int to func(int) int函数值可以与 nil 比较,但是函数值之间是不可比较的,也不能用函数值作为 map 的 key。
通过函数字面量(function literal)允许我们在使用函数时,再定义它:
Go
strings.Map(func(r rune) rune { return r + 1 }, "HAL-9000")1.4. 匿名函数
在函数中定义的内部函数可以引用该函数的变量:
Go
// squares 返回一个匿名函数。
// 该匿名函数每次被调用时都会返回下一个数的平方。
func squares() func() int {
var x int
return func() int {
x++
return x * x
}
}
func main() {
f := squares()
fmt.Println(f()) // "1"
fmt.Println(f()) // "4"
fmt.Println(f()) // "9"
fmt.Println(f()) // "16"
}函数 squares 返回另一个类型为 func() int 的函数。对 squares 的一次调用会生成一个局部变量 x 并返回一个匿名函数。每次调用时匿名函数时,该函数都会先使 x 的值加 1,再返回 x 的平方。第二次调用 squares 时,会生成第二个 x 变量,并返回一个新的匿名函数。新匿名函数操作的是第二个 x 变量。
在 squares 中定义的匿名内部函数可以访问和更新 squares 中的局部变量,这意味着匿名函数和 squares 中,存在变量引用。这就是函数值属于引用类型和函数值不可比较的原因。
1.4.1. 注意迭代变量
考虑这个样一个问题:你被要求首先创建一些目录,再将目录删除。在下面的例子中我们用函数值来完成删除操作。下面的示例代码需要引入 os 包。为了使代码简单,我们忽略了所有的异常处理。
Go
var rmdirs []func()
for _, d := range tempDirs() {
dir := d // NOTE: necessary!
os.MkdirAll(dir, 0755) // creates parent directories too
rmdirs = append(rmdirs, func() {
os.RemoveAll(dir)
})
}
// ...do some work…
for _, rmdir := range rmdirs {
rmdir() // clean up
}你可能会感到困惑,为什么要在循环体中用循环变量 d 赋值一个新的局部变量,而不是像下面的代码一样直接使用循环变量 dir。需要注意,下面的代码是错误的。
Go
var rmdirs []func()
for _, dir := range tempDirs() {
os.MkdirAll(dir, 0755)
rmdirs = append(rmdirs, func() {
os.RemoveAll(dir) // NOTE: incorrect!
})
}问题的原因在于循环变量的作用域。在上面的程序中 for 循环语句生成的所有函数值都共享相同的 dir 变量。而当 for 循环完成时 dir 存储的值等于最后一次迭代的值,这意味着每次对 os.RemoveAll 的调用删除的都是相同的目录。
通常为了解决这个问题,我们会引入一个与循环变量同名的局部变量,作为循环变量的副本。比如:
Go
for _, dir := range tempDirs() {
dir := dir // declares inner dir, initialized to outer dir
// ...
}1.5. 可变参数
1.5.1. 可变参函数的定义及调用
在声明可变参数函数时,需要在参数列表的最后一个参数类型之前加上省略符号 “...”,这表示该函数会接收任意数量的该类型参数。
Go
func func1(vals...int) {
for _, val := range vals {
// ...
}
}调用:
Go
fmt.Println(sum())
fmt.Println(sum(3))
fmt.Println(sum(1, 2, 3, 4))调用者在调用时,会隐式的创建一个数组,并将原始参数复制到数组中,再把数组的一个切片作为参数传给被调函数。
如果原始参数已经是切片类型,那么我们只需在最后一个参数后加上省略符即可。
Go
values := []int{1, 2, 3, 4}
func1(values...)1.5.2. 可变参函数与切片参数函数
虽然在可变参数函数内部,...int 型参数的行为看起来很像切片类型,但实际上,可变参数函数和以切片作为参数的函数是不同的。
Go
func f(...int) {}
func g([]int) {}
fmt.Printf("%T\n", f) // "func(...int)"
fmt.Printf("%T\n", g) // "func([]int)"1.5.3. 任意类型可变参函数
interfac{} 表示函数的最后一个参数可以接收任意类型。
Go
func errorf(linenum int, format string, args ...interface{}) {
fmt.Fprintf(os.Stderr, "Line %d: ", linenum)
fmt.Fprintf(os.Stderr, format, args...)
fmt.Fprintln(os.Stderr)
}1.6. Deferred 函数
1.6.1. 基础用法
在调用普通函数或方法前加上关键字 defer,就完成了 defer 所需要的语法。当 defer 语句被执行时,跟在 defer 后面的函数会被延迟执行。直到包含该 defer 语句的函数执行完毕时,defer 后的函数才会被执行,不论包含 defer 语句的函数是通过 return 正常结束,还是由于 panic 导致的异常结束。
可以在一个函数中执行多条 defer 语句,它们的执行顺序与声明顺序相反。
defer 语句经常被用于处理成对的操作,如打开、关闭、连接、断开连接、加锁、释放锁。通过 defer 机制,不论函数逻辑多复杂,都能保证在任何执行路径下,资源被释放。释放资源的 defer 应该直接跟在请求资源的语句后。
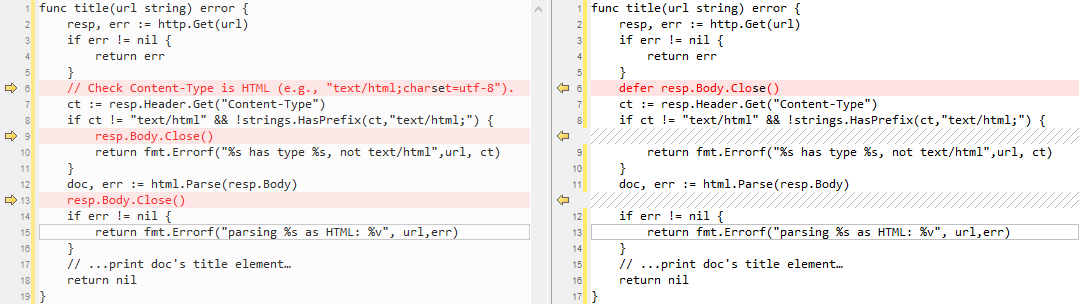
Go
func title(url string) error {
resp, err := http.Get(url)
if err != nil {
return err
}
// Check Content-Type is HTML (e.g., "text/html;charset=utf-8").
ct := resp.Header.Get("Content-Type")
if ct != "text/html" && !strings.HasPrefix(ct,"text/html;") {
resp.Body.Close()
return fmt.Errorf("%s has type %s, not text/html",url, ct)
}
doc, err := html.Parse(resp.Body)
resp.Body.Close()
if err != nil {
return fmt.Errorf("parsing %s as HTML: %v", url,err)
}
// ...print doc's title element…
return nil
}在上面的例子中 resp.Body.close 调用了多次,这是为了确保 title 在所有执行路径下(即使函数运行失败)都关闭了网络连接。随着函数变得复杂,需要处理的错误也变多,维护清理逻辑变得越来越困难。在下面我们将用一条 defer 语句替代了之前的所有 resp.Body.Close:
Go
func title(url string) error {
resp, err := http.Get(url)
if err != nil {
return err
}
defer resp.Body.Close()
ct := resp.Header.Get("Content-Type")
if ct != "text/html" && !strings.HasPrefix(ct,"text/html;") {
return fmt.Errorf("%s has type %s, not text/html",url, ct)
}
doc, err := html.Parse(resp.Body)
if err != nil {
return fmt.Errorf("parsing %s as HTML: %v", url,err)
}
// ...print doc's title element…
return nil
}
1.6.2. defer 返回值为函数的函数
调试复杂程序时,defer 机制也常被用于记录何时进入和退出函数。下例中的 bigSlowOperation 函数,直接调用 trace 记录函数的被调情况。bigSlowOperation 被调时,trace 会返回一个函数值,该函数值会在 bigSlowOperation 退出时被调用。通过这种方式,我们可以只通过一条语句控制函数的入口和所有的出口,甚至可以记录函数的运行时间,如例子中的 start。需要注意一点:不要忘记 defer 语句后的圆括号。
Go
func bigSlowOperation() {
defer trace("bigSlowOperation")() // don't forget the extra parentheses
// ...lots of work…
time.Sleep(10 * time.Second) // simulate slow operation by sleeping
}
func trace(msg string) func() {
start := time.Now()
log.Printf("enter %s", msg)
return func() {
log.Printf("exit %s (%s)", msg,time.Since(start))
}
}1.6.3. 使用 defer 观察或修改函数的返回值
defer 语句中的函数会在 return 语句更新返回值变量后再执行,又因为在函数中定义的匿名函数可以访问该函数包括返回值变量在内的所有变量,所以,对匿名函数采用 defer 机制,可以使其观察函数的返回值。
Go
func double(x int) int {
return x + x
}
func triple(x int) (result int) {
defer func() { result += x }()
return double(x)
}
fmt.Println(triple(4)) // "12"1.6.4. 注意在循环体中使用 defer
在循环体中的 defer 语句需要特别注意,因为只有在函数执行完毕后,这些被延迟的函数才会执行。下面的代码会导致系统的文件描述符耗尽,因为在所有文件都被处理之前,没有文件会被关闭。
Go
for _, filename := range filenames {
f, err := os.Open(filename)
if err != nil {
return err
}
defer f.Close() // NOTE: risky; could run out of file
descriptors
// ...process f…
}一种解决方法是将循环体中的 defer 语句移至另外一个函数。在每次循环时,调用这个函数。
Go
for _, filename := range filenames {
if err := doFile(filename); err != nil {
return err
}
}
func doFile(filename string) error {
f, err := os.Open(filename)
if err != nil {
return err
}
defer f.Close()
// ...process f…
}1.6.5. 延迟函数的调用在释放堆栈信息之前
Go
func main() {
defer printStack()
f(3)
}
func printStack() {
var buf [4096]byte
n := runtime.Stack(buf[:], false)
os.Stdout.Write(buf[:n])
}
func f(x int) {
fmt.Printf("f(%d)\n", x+0/x) // panics if x == 0
defer fmt.Printf("defer %d\n", x)
f(x - 1)
}printStack 的简化输出如下(下面只是 printStack 的输出,不包括 panic 的日志信息):
Text
goroutine 1 [running]:
main.printStack()
src/gopl.io/ch5/defer2/defer.go:20
main.f(0)
src/gopl.io/ch5/defer2/defer.go:27
main.f(1)
src/gopl.io/ch5/defer2/defer.go:29
main.f(2)
src/gopl.io/ch5/defer2/defer.go:29
main.f(3)
src/gopl.io/ch5/defer2/defer.go:29
main.main()
src/gopl.io/ch5/defer2/defer.go:15正是因为延迟函数的调用在释放堆栈信息之前,所以 runtime.Stack 能输出已经被释放函数的信息。
1.7. Panic 异常
1.7.1. 什么时候该用/不该用 Panic
当某些不应该发生的场景发生时,我们就应该调用 panic。比如,当程序到达了某条逻辑上不可能到达的路径:
Go
switch s := suit(drawCard()); s {
case "Spades": // ...
case "Hearts": // ...
case "Diamonds": // ...
case "Clubs": // ...
default:
panic(fmt.Sprintf("invalid suit %q", s)) // Joker?
}断言函数必须满足的前置条件是明智的做法,但这很容易被滥用。除非你能提供更多的错误信息,或者能更快速的发现错误,否则不需要使用断言。
Go
func Reset(x *Buffer) {
if x == nil {
panic("x is nil") // unnecessary!
}
x.elements = nil
}以 regexp.Compile 和 regexp.MustCompile 函数为例:
- 当调用方无法保证输入不会出错时,可以选择调用
regexp.Compile方法,该方法不会引发异常,并且返回一个错误对象供调用方检查; - 当调用方可以保证输入不会出错时,可以选择调用
regexp.MustCompile方法(因为在该情况下再要求调用者检查返回错误是不必要和累赘的),当调用者输入了不应该出现的输入时,触发 panic 异常。
regexp.MustCompile函数名中的Must前缀是一种针对此类函数的命名约定
Go
package regexp
func Compile(expr string) (*Regexp, error) { /* ... */ }
func MustCompile(expr string) *Regexp {
re, err := Compile(expr)
if err != nil {
panic(err)
}
return re
}1.8. Recover 捕获异常
如果在 deferred 函数中调用了内置函数 recover,并且定义该 defer 语句的函数发生了 panic 异常,recover 会使程序从 panic 中恢复,并返回 panic value。导致 panic 异常的函数不会继续运行,但能正常返回。在未发生 panic 时调用 recover,recover 会返回 nil。
为了标识某个 panic 是否应该被恢复,我们可以将 panic value 设置成特殊类型。在 recover 时对 panic value 进行检查,如果发现 panic value 是特殊类型,就将这个 panic 作为 error 处理,如果不是,则按照正常的 panic 进行处理。
Go
// soleTitle returns the text of the first non-empty title element
// in doc, and an error if there was not exactly one.
func soleTitle(doc *html.Node) (title string, err error) {
type bailout struct{}
defer func() {
switch p := recover(); p {
case nil: // no panic
case bailout{}: // "expected" panic
err = fmt.Errorf("multiple title elements")
default:
panic(p) // unexpected panic; carry on panicking
}
}()
// Bail out of recursion if we find more than one nonempty title.
forEachNode(doc, func(n *html.Node) {
if n.Type == html.ElementNode && n.Data == "title" &&
n.FirstChild != nil {
if title != "" {
panic(bailout{}) // multiple titleelements
}
title = n.FirstChild.Data
}
}, nil)
if title == "" {
return "", fmt.Errorf("no title element")
}
return title, nil
}以上例子中,soleTitle 在处理时,如果检测到有多个 <title>,会调用 panic,阻止函数继续递归,并将特殊类型 bailout 作为 panic 的参数。
2. 方法
2.1. 方法声明
Go
package geometry
import "math"
type Point struct{ X, Y float64 }
// traditional function
func Distance(p, q Point) float64 {
return math.Hypot(q.X-p.X, q.Y-p.Y)
}
// same thing, but as a method of the Point type
func (p Point) Distance(q Point) float64 {
return math.Hypot(q.X-p.X, q.Y-p.Y)
}上面的代码里那个附加的参数 p(第 13 行),叫做方法的接收器(receiver),在 Go 语言中并不像其它语言那样用 this 或者 self 作为接收器,我们可以任意的选择接收器的名字。
在 Go 语言里,我们甚至可以为一些简单的数值、字符串、slice、map 来定义一些附加行为。我们可以给同一个包内的任意命名类型定义方法,只要这个命名类型的底层类型(在下面这个例子中,底层类型是指 []Point 这个 slice,命名类型是 Path)不是指针或者 interface。
Go
// A Path is a journey connecting the points with straight lines.
type Path []Point
// Distance returns the distance traveled along the path.
func (path Path) Distance() float64 {
sum := 0.0
for i := range path {
if i > 0 {
sum += path[i-1].Distance(path[i])
}
}
return sum
}2.2. 基于指针对象的方法
2.2.1. 声明
当调用一个函数时,会对其每一个参数值进行拷贝,当我们希望能够避免进行这种默认的拷贝时,我们就可以用其指针而不是对象来声明方法,如:
Go
func (p *Point) ScaleBy(factor float64) {
p.X *= factor
p.Y *= factor
}Note
为了避免歧义,在声明方法时,如果一个类型名本身是一个指针的话,是不允许其出现在接收器中的,比如下面这个例子:
Gotype P *int func (P) f() { /* ... */ } // compile error: invalid receiver type
2.2.2. 调用
想要调用指针类型方法 (*Point).ScaleBy,只要提供一个 Point 类型的指针即可,像下面这样:
Go
r := &Point{1, 2}
r.ScaleBy(2)或者这样:
Go
p := Point{1, 2}
(&p).ScaleBy(2)上面第二种写法有点笨拙,幸运的是,我们可以用下面这种简短的写法:
Go
p.ScaleBy(2)Note
在简短写法中,实际上编译器会隐式地帮我们用
&p去调用ScaleBy这个方法;这种简写方法只适用于 “变量”,其它像
struct里的字段比如p.X,以及 array 和 slice 内的元素比如perim[0]均不支持这种写法;无法取到地址的接收器不能调用指针方法,比如临时变量的内存地址就无法获取得到:
GoPoint{1, 2}.ScaleBy(2) // compile error: can't take address of Point literal
于简短写法类似,我们也可以通过指针对象调用该底层对象的方法,所以以下两种写法等价:
Go
pptr.Distance(q)
(*pptr).Distance(q)更多关于值接收器的方法与指针接收器的方法在调用时的区别请看这里。
2.2.3. nil 也是一个合法的接收器值
下面是 net/url 包里 Values 类型定义的一部分:
Go
package url
// Values maps a string key to a list of values.
type Values map[string][]string
// Get returns the first value associated with the given key,
// or "" if there are none.
func (v Values) Get(key string) string {
if vs := v[key]; len(vs) > 0 {
return vs[0]
}
return ""
}
// Add adds the value to key.
// It appends to any existing values associated with key.
func (v Values) Add(key, value string) {
v[key] = append(v[key], value)
}这个定义向外部暴露了一个底层类型为 map 的命名类型,并且提供了一些能够简单操作这个 map 的方法。客户端使用这个变量的时候可以使用 map 固有的一些操作(make,切片,m[key] 等等),也可以使用这里提供的操作方法,或者两者并用,都是可以的:
Go
m := url.Values{"lang": {"en"}} // direct construction
m.Add("item", "1")
m.Add("item", "2")
fmt.Println(m.Get("lang")) // "en"
fmt.Println(m.Get("q")) // ""
fmt.Println(m.Get("item")) // "1" (first value)
fmt.Println(m["item"]) // "[1 2]" (direct map access)
m = nil
fmt.Println(m.Get("item")) // ""
m.Add("item", "3") // panic: assignment to entry in nil map对 Get 的最后一次调用中(第 11 行),nil 接收器的行为即是一个空 map 的行为。我们可以等价地将这个操作写成 Value(nil).Get("item"),但是如果你直接写 nil.Get("item") 的话是无法通过编译的,因为 nil 的字面量编译器无法判断其准确类型。所以相比之下,最后的那行 m.Add 的调用就会产生一个 panic,因为他尝试更新一个空 map。
2.3. 通过嵌入结构体来扩展类型
Go
import "image/color"
type Point struct{ X, Y float64 }
type ColoredPoint struct {
Point
Color color.RGBA
}通过内嵌,我们可以直接访问内嵌对象的字段值,就好像内嵌对象的字段就是 ColoredPoint 自身的字段:
Go
var cp ColoredPoint
cp.X = 1
fmt.Println(cp.Point.X) // "1"
cp.Point.Y = 2
fmt.Println(cp.Y) // "2"内嵌对象的方法也是一样:
Go
red := color.RGBA{255, 0, 0, 255}
blue := color.RGBA{0, 0, 255, 255}
var p = ColoredPoint{Point{1, 1}, red}
var q = ColoredPoint{Point{5, 4}, blue}
fmt.Println(p.Distance(q.Point)) // "5"
p.ScaleBy(2)
q.ScaleBy(2)
fmt.Println(p.Distance(q.Point)) // "10"实际上在 Go 当中并没有继承的概念,在上述例子中,我们不能将 ColoredPoint 看作 "is a Point"(从上述例子中的第 5、8 行 p.Distance(q.Point) 也可以看出,q 并不是一个 Point 类,在传参时我们必须显式地指出 q.Point),而是 ColoredPoint "has a Point"。
当然,内嵌的对象也可以是一个命名类型的指针,这种情况下字段和方法也会被间接地引入到当前的类型中:
Go
type ColoredPoint struct {
*Point
Color color.RGBA
}
p := ColoredPoint{&Point{1, 1}, red}
q := ColoredPoint{&Point{5, 4}, blue}
fmt.Println(p.Distance(*q.Point)) // "5"
q.Point = p.Point // p and q now share the same Point
p.ScaleBy(2)
fmt.Println(*p.Point, *q.Point) // "{2 2} {2 2}"一个 struct 类型也允许有多个匿名字段。我们将 ColoredPoint 定义为下面这样:
Go
type ColoredPoint struct {
Point
color.RGBA
}然后该类型的值便会拥有 Point 和 RGBA 类型的所有方法,以及直接定义在 ColoredPoint 中的方法。当编译器解析一个选择器到方法时,比如 p.ScaleBy,它会首先去找直接定义在这个类型里的 ScaleBy 方法,然后找被 ColoredPoint 的内嵌字段们引入的方法,然后去找 Point 和 RGBA 的内嵌字段引入的方法,然后一直递归向下找。如果选择器有二义性的话编译器会报错,比如你在同一级里有两个同名的方法。
2.4. 方法值和方法表达式
2.4.1. 方法值
Go
p := Point{1, 2}
q := Point{4, 6}
distanceFromP := p.Distance // method value
fmt.Println(distanceFromP(q)) // "5"
var origin Point // {0, 0}
fmt.Println(distanceFromP(origin)) // "2.23606797749979", sqrt(5)
scaleP := p.ScaleBy // method value
scaleP(2) // p becomes (2, 4)
scaleP(3) // then (6, 12)
scaleP(10) // then (60, 120)上例中 p.Distance 叫作 “选择器”,选择器会返回一个 “方法值”。这个 “方法值” 在调用时不需要指定接收器(因为已经在前文中指定过了),只要传入函数的参数即可。
方法值还可以作为参数进行传递:
Go
type Rocket struct { /* ... */ }
func (r *Rocket) Launch() { /* ... */ }
r := new(Rocket)
time.AfterFunc(10 * time.Second, r.Launch)2.4.2. 方法表达式
当 T 是一个类型时,方法表达式可能会写作 T.f 或者 (*T).f,会返回一个 “函数值”,这种函数会将其第一个参数用作接收器:
Go
p := Point{1, 2}
q := Point{4, 6}
distance := Point.Distance // method expression
fmt.Println(distance(p, q)) // "5"
fmt.Printf("%T\n", distance) // "func(Point, Point) float64"
scale := (*Point).ScaleBy
scale(&p, 2)
fmt.Println(p) // "{2 4}"
fmt.Printf("%T\n", scale) // "func(*Point, float64)"2.5. 示例: Bit 数组
Go 语言里的集合一般会用 map[T]bool 这种形式来表示,T 代表元素类型。集合用 map 类型来表示虽然非常灵活,但我们可以以一种更好的形式来表示它。例如在数据流分析领域,集合元素通常是一个非负整数,集合会包含很多元素,并且集合会经常进行并集、交集操作,这种情况下,bit 数组会比 map 表现更加理想。再或者,比如我们执行一个 http 下载任务,把文件按照 16kb 一块划分为很多块,需要有一个全局变量来标识哪些块下载完成了,这种时候也需要用到 bit 数组。
一个 bit 数组通常会用一个无符号数或者称之为 “字” 的 slice 来表示,每一个元素的每一位都表示集合里的一个值。当集合的第 i 位被设置时,我们才说这个集合包含元素 i。下面的这个程序展示了一个简单的 bit 数组类型,并且实现了三个函数来对这个 bit 数组来进行操作:
Go
// An IntSet is a set of small non-negative integers.
// Its zero value represents the empty set.
type IntSet struct {
words []uint64
}
// Has reports whether the set contains the non-negative value x.
func (s *IntSet) Has(x int) bool {
word, bit := x/64, uint(x%64)
return word < len(s.words) && s.words[word]&(1<<bit) != 0
}
// Add adds the non-negative value x to the set.
func (s *IntSet) Add(x int) {
word, bit := x/64, uint(x%64)
for word >= len(s.words) {
s.words = append(s.words, 0)
}
s.words[word] |= 1 << bit
}
// UnionWith sets s to the union of s and t.
func (s *IntSet) UnionWith(t *IntSet) {
for i, tword := range t.words {
if i < len(s.words) {
s.words[i] |= tword
} else {
s.words = append(s.words, tword)
}
}
}因为每一个字都有 64 个二进制位,所以为了定位 x 的 bit 位,我们用了 x/64 的商作为字的下标,并且用 x%64 得到的值作为这个字内的 bit 的所在位置。UnionWith 这个方法里用到了 bit 位的 “或” 逻辑操作符号 | 来一次完成 64 个元素的或计算。
但是有一个方法如果缺失的话我们的 bit 数组可能会比较难混:将 IntSet 作为一个字符串来打印。这里我们来实现它,让我们来给上面的例子添加一个 String 方法:
Go
// String returns the set as a string of the form "{1 2 3}".
func (s *IntSet) String() string {
var buf bytes.Buffer
buf.WriteByte('{')
for i, word := range s.words {
if word == 0 {
continue
}
for j := 0; j < 64; j++ {
if word&(1<<uint(j)) != 0 {
if buf.Len() > len("{") {
buf.WriteByte(' ')
}
fmt.Fprintf(&buf, "%d", 64*i+j)
}
}
}
buf.WriteByte('}')
return buf.String()
}bytes.Buffer 在 String 方法里经常这么用。当你为一个复杂的类型定义了一个 String 方法时,fmt 包就会特殊对待这种类型的值,这样可以让这些类型在打印的时候看起来更加友好,而不是直接打印其原始的值。fmt 会直接调用用户定义的 String 方法。这种机制依赖于接口和类型断言,后续我们会详细介绍。
现在我们就可以在实战中直接用上面定义好的 IntSet 了:
Go
var x, y IntSet
x.Add(1)
x.Add(144)
x.Add(9)
fmt.Println(x.String()) // "{1 9 144}"
y.Add(9)
y.Add(42)
fmt.Println(y.String()) // "{9 42}"
x.UnionWith(&y)
fmt.Println(x.String()) // "{1 9 42 144}"
fmt.Println(x.Has(9), x.Has(123)) // "true false"这里要注意:我们声明的 String 和 Has 两个方法都是以指针类型 *IntSet 来作为接收器的,但实际上对于这两个类型来说,把接收器声明为指针类型也没什么必要。不过另外两个函数就不是这样了,因为另外两个函数操作的是 s.words 对象,如果你不把接收器声明为指针对象,那么实际操作的是拷贝对象,而不是原来的那个对象。因此,因为我们的 String 方法定义在 IntSet 指针上,所以当我们的变量是 IntSet 类型而不是 IntSet 指针时,可能会有下面这样让人意外的情况:
Go
fmt.Println(&x) // "{1 9 42 144}"
fmt.Println(x.String()) // "{1 9 42 144}"
fmt.Println(x) // "{[4398046511618 0 65536]}"在第一个 Println 中,我们打印一个 *IntSet 的指针,这个类型的指针确实有自定义的 String 方法。第二 Println,我们直接调用了 x 变量的 String() 方法;这种情况下编译器会隐式地在 x 前插入 & 操作符,这样相当远我们还是调用的 IntSet 指针的 String 方法。在第三个 Println 中,因为 IntSet 类型没有 String 方法,所以 Println 方法会直接以原始的方式理解并打印。所以在这种情况下 & 符号是不能忘的。在我们这种场景下,你把 String 方法绑定到 IntSet 对象上,而不是 IntSet 指针上可能会更合适一些,不过这也需要具体问题具体分析。
2.6. 封装
封装提供了三方面的优点:
- 只需要关注少量的语句并且只要弄懂少量变量的可能的值即可;
- 隐藏实现的细节,可以防止调用方依赖那些可能变化的具体实现,这样使设计包的程序员在不破坏对外的 api 情况下能得到更大的自由;
- 阻止了外部调用方对对象内部的值任意地进行修改;
只用来访问或修改内部变量的函数被称为 setter 或者 getter。在命名一个 getter 方法时,我们通常会省略掉前面的 Get 前缀(这种简洁上的偏好也可以推广到各种类型的前缀比如 Fetch、Find 或者 Lookup)。
Go
package log
type Logger struct {
flags int
prefix string
// ...
}
func (l *Logger) Flags() int {
// ...
return l.flag
}
func (l *Logger) SetFlags(flag int) {
// ...
l.flag = flag
}
func (l *Logger) Prefix() string {
// ...
return l.prefix
}
func (l *Logger) SetPrefix(prefix string) {
// ...
l.prefix = prefix
}将之前的 IntSet 与 Path 进行对比。Path 被定义为一个 slice 类型,这允许其调用 slice 的字面方法来对其内部的 points 用 range 进行迭代遍历,而这点在 IntSet 中是不被允许的。
Path 的本质是一个坐标点的序列,不多也不少,我们可以预见到之后也并不会给他增加额外的字段,所以将 Path 暴露为一个 slice。相比之下,IntSet 仅仅是在这里用了一个 []uint64 的 slice。这个类型还可以用 []uint 类型来表示,或者我们甚至可以用其它完全不同的占用更小内存空间的东西来表示这个集合,所以我们可能还会需要额外的字段来在这个类型中记录元素的个数。也正是因为这些原因,我们让 IntSet 对调用方不透明。